Difficulty-guided Sampling: Bridging the Target Gap between Dataset Distillation and Downstream Tasks
作者: Mingzhuo Li, Guang Li, Linfeng Ye, Jiafeng Mao, Takahiro Ogawa, Konstantinos N. Plataniotis, Miki Haseyama
分类: cs.CV, cs.AI
发布日期: 2026-01-15
💡 一句话要点
提出难度引导采样(DGS)以弥合数据集蒸馏与下游任务之间的目标差距。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 数据集蒸馏 难度引导采样 下游任务 目标差距 图像分类
📋 核心要点
- 现有数据集蒸馏方法忽略了任务特定信息,导致蒸馏目标与下游任务存在差距。
- 提出难度引导采样(DGS),根据下游任务的难度分布对蒸馏数据集进行采样。
- 实验表明,DGS能有效提升数据集蒸馏的性能,并具有广泛的应用潜力。
📝 摘要(中文)
本文提出难度引导采样(DGS)来弥合数据集蒸馏目标与下游任务之间的目标差距,从而提高数据集蒸馏的性能。深度神经网络取得了显著的性能,但训练过程耗时且占用大量存储空间。数据集蒸馏旨在生成紧凑、高质量的蒸馏数据集,从而实现有效的模型训练,同时保持下游性能。现有方法通常侧重于从原始数据集中提取的特征,忽略了特定于任务的信息,导致蒸馏目标与下游任务之间存在目标差距。我们提出利用有益于下游训练的特性到数据蒸馏中,以弥合这一差距。针对图像分类的下游任务,我们引入了难度的概念,并提出DGS作为一个插件式的后处理采样模块。根据特定的目标难度分布,从现有方法生成的图像池中采样最终的蒸馏数据集。我们还提出了难度感知引导(DAG)来探索难度在生成过程中的影响。在多种设置下进行的大量实验证明了所提出方法的有效性。它也突出了难度对于各种下游任务的更广泛的潜力。
🔬 方法详解
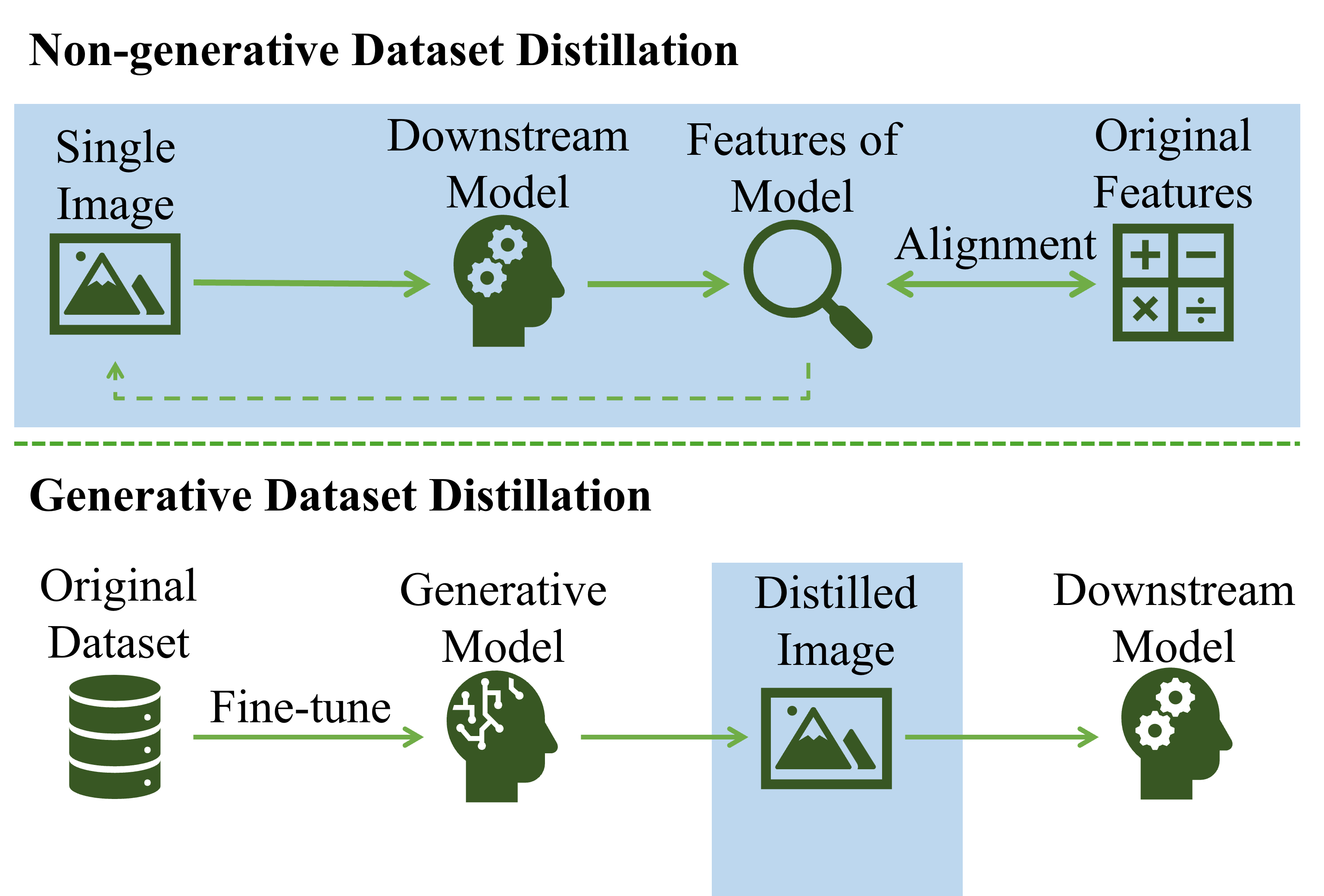
问题定义:数据集蒸馏旨在生成一个小的、具有代表性的数据集,用于训练模型并达到与在原始大数据集上训练相似的性能。然而,现有方法主要关注原始数据集的特征,忽略了下游任务的特定信息,导致蒸馏数据集与下游任务的目标不一致,限制了蒸馏性能。
核心思路:本文的核心思路是利用下游任务的难度信息来指导数据集蒸馏过程。通过对蒸馏数据集进行采样,使其难度分布与下游任务的目标难度分布相匹配,从而弥合蒸馏目标与下游任务之间的差距。
技术框架:该方法主要包含两个阶段:1) 使用现有的数据集蒸馏方法生成一个图像池;2) 使用提出的难度引导采样(DGS)模块,从图像池中采样最终的蒸馏数据集。DGS模块根据预先设定的目标难度分布进行采样,确保蒸馏数据集的难度分布与下游任务的需求相匹配。此外,还提出了难度感知引导(DAG)来探索难度在生成过程中的影响。
关键创新:该方法最重要的创新点在于引入了难度这一概念,并将其用于指导数据集蒸馏过程。通过难度引导采样,可以生成更符合下游任务需求的蒸馏数据集,从而提高蒸馏性能。与现有方法相比,该方法更加关注下游任务的特定信息,弥合了蒸馏目标与下游任务之间的差距。
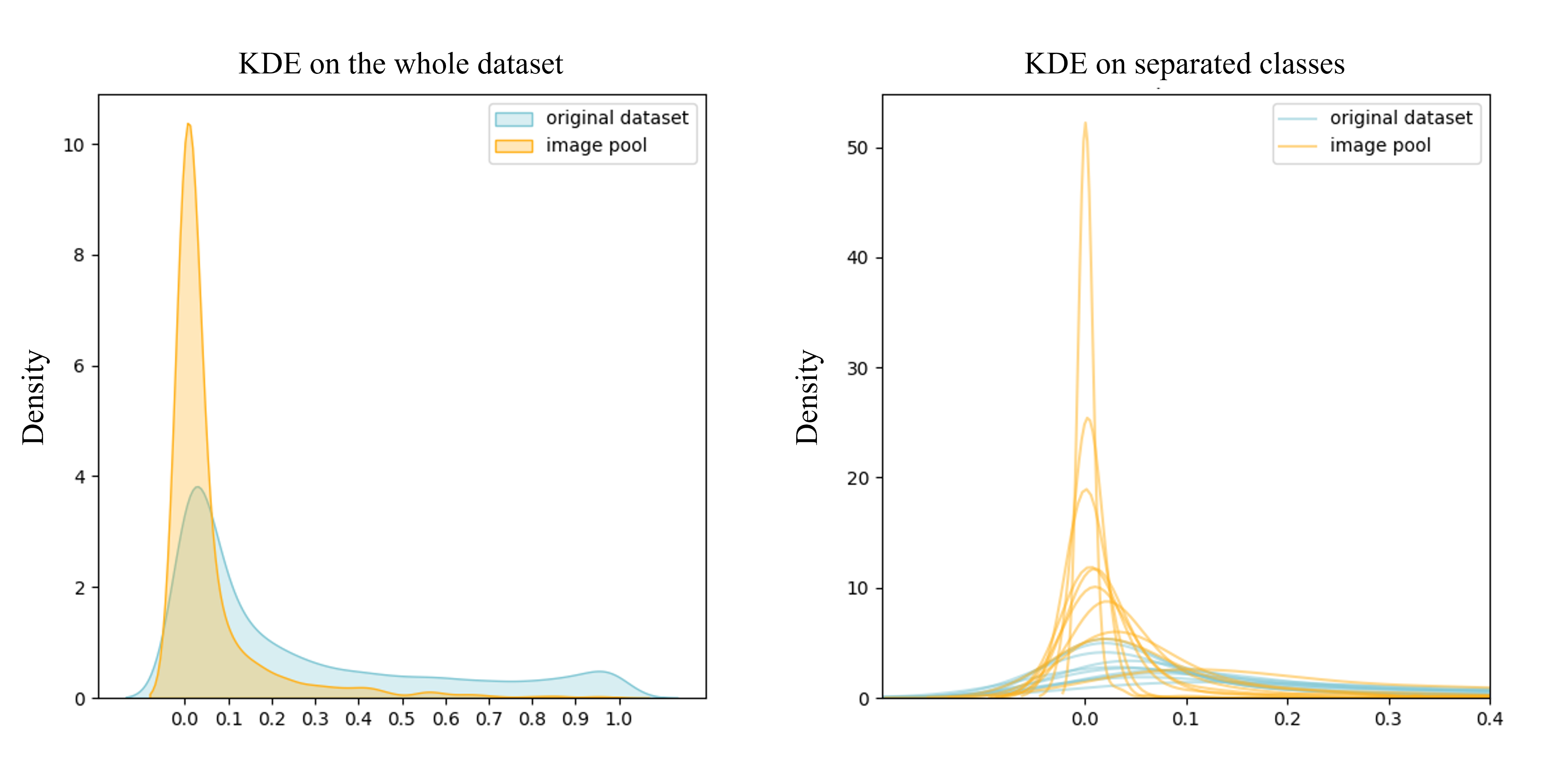
关键设计:DGS模块的关键设计在于如何定义和估计图像的难度,以及如何根据目标难度分布进行采样。论文中可能使用了某种难度评估指标(具体方法未知),并设计了一种采样策略,使得蒸馏数据集的难度分布尽可能接近目标难度分布。DAG模块的具体实现细节未知,但其目的是探索难度在蒸馏数据集生成过程中的作用。
🖼️ 关键图片
📊 实验亮点
论文在多个数据集和模型上进行了实验,结果表明,提出的DGS方法能够显著提高数据集蒸馏的性能。具体的性能提升数据未知,但实验结果表明,DGS能够有效地弥合蒸馏目标与下游任务之间的差距,并生成更符合下游任务需求的蒸馏数据集。
🎯 应用场景
该研究成果可应用于各种需要数据集蒸馏的场景,例如移动设备上的模型部署、资源受限环境下的模型训练等。通过生成更小、更高效的蒸馏数据集,可以降低模型训练和部署的成本,并提高模型的泛化能力。未来,该方法可以扩展到其他下游任务,例如目标检测、语义分割等。
📄 摘要(原文)
In this paper, we propose difficulty-guided sampling (DGS) to bridge the target gap between the distillation objective and the downstream task, therefore improving the performance of dataset distillation. Deep neural networks achieve remarkable performance but have time and storage-consuming training processes. Dataset distillation is proposed to generate compact, high-quality distilled datasets, enabling effective model training while maintaining downstream performance. Existing approaches typically focus on features extracted from the original dataset, overlooking task-specific information, which leads to a target gap between the distillation objective and the downstream task. We propose leveraging characteristics that benefit the downstream training into data distillation to bridge this gap. Focusing on the downstream task of image classification, we introduce the concept of difficulty and propose DGS as a plug-in post-stage sampling module. Following the specific target difficulty distribution, the final distilled dataset is sampled from image pools generated by existing methods. We also propose difficulty-aware guidance (DAG) to explore the effect of difficulty in the generation process. Extensive experiments across multiple settings demonstrate the effectiveness of the proposed methods. It also highlights the broader potential of difficulty for diverse downstream tasks.