VERHallu: Evaluating and Mitigating Event Relation Hallucination in Video Large Language Models
作者: Zefan Zhang, Kehua Zhu, Shijie Jiang, Hongyuan Lu, Shengkai Sun, Tian Bai
分类: cs.CV, cs.AI
发布日期: 2026-01-15
备注: 11 pages, 6 figures
💡 一句话要点
提出VERHallu基准评测并设计KFP策略,缓解视频大语言模型中的事件关系幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频大语言模型 事件关系幻觉 视频理解 关键帧传播 多模态学习 因果推理 时间推理
📋 核心要点
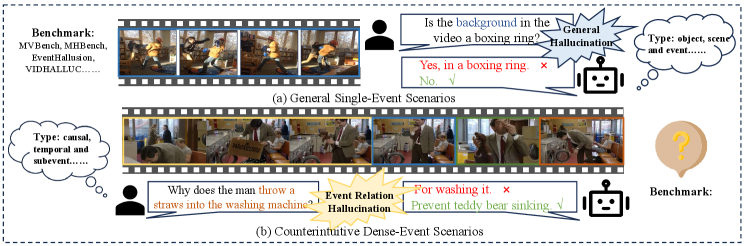
- 现有VideoLLM研究主要关注事件、对象和场景的幻觉,忽略了事件关系幻觉,导致模型对视频理解不完整。
- 论文提出关键帧传播(KFP)策略,通过在中间层重新分配帧级注意力,增强模型对多事件的理解能力。
- 实验结果表明,KFP策略能有效缓解事件关系幻觉,且不影响推理速度,提升了VideoLLM的性能。
📝 摘要(中文)
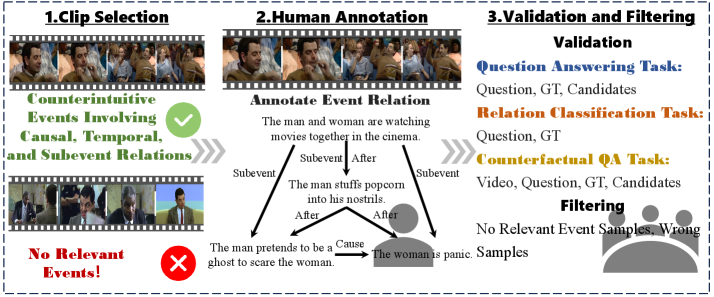
视频大语言模型(VideoLLMs)表现出多种幻觉。现有研究主要关注视频中事件、对象和场景的幻觉,而忽略了事件关系幻觉。本文提出了一个新的基准VERHallu,用于评估视频事件关系幻觉。该基准侧重于事件之间的因果、时间和子事件关系,包含关系分类、问答和反事实问答三种任务,全面评估事件关系幻觉。此外,它还包含违反常理的视频场景,这些场景偏离了典型的预训练分布,每个样本都附带人工标注的候选答案,涵盖了视觉-语言和纯语言偏差。分析表明,当前最先进的VideoLLM在密集事件关系推理方面存在困难,由于未能充分利用帧级线索,常常依赖于先验知识。尽管这些模型在关键事件的定位方面表现出强大的能力,但它们经常忽略周围的子事件,导致对事件关系的不完整和不准确的理解。为了解决这个问题,我们提出了一种关键帧传播(KFP)策略,该策略在中间层重新分配帧级注意力,以增强多事件理解。实验表明,该策略有效地缓解了事件关系幻觉,且不影响推理速度。
🔬 方法详解
问题定义:论文旨在解决视频大语言模型(VideoLLMs)中存在的事件关系幻觉问题。现有方法主要关注事件、对象和场景的幻觉,忽略了事件之间的因果、时间以及子事件等关系,导致模型对视频内容的理解不完整、不准确。现有模型在处理密集事件关系推理时,容易依赖先验知识,未能充分利用视频帧级别的视觉信息。
核心思路:论文的核心思路是通过关键帧传播(KFP)策略,增强模型对视频帧级别信息的利用,从而提升模型对事件关系的理解能力。KFP策略通过在模型的中间层重新分配帧级注意力,使模型能够更好地关注关键帧以及关键帧周围的子事件,从而更准确地推断事件之间的关系。
技术框架:论文提出的KFP策略可以嵌入到现有的VideoLLM框架中。整体流程如下:首先,VideoLLM对输入视频进行编码,提取视频特征。然后,在模型的中间层,应用KFP策略重新分配帧级注意力。最后,模型基于重新分配后的注意力权重,进行事件关系推理,并输出结果。VERHallu基准测试包含关系分类、问答和反事实问答三种任务。
关键创新:论文的关键创新在于提出了KFP策略,该策略通过在中间层重新分配帧级注意力,增强了模型对视频帧级别信息的利用,从而提升了模型对事件关系的理解能力。与现有方法相比,KFP策略能够更好地关注关键帧以及关键帧周围的子事件,从而更准确地推断事件之间的关系,缓解事件关系幻觉。
关键设计:KFP策略的关键设计在于如何重新分配帧级注意力。具体来说,该策略首先计算每个帧的重要性得分,然后基于重要性得分,重新分配帧级注意力权重。重要性得分可以通过多种方式计算,例如,可以使用注意力机制或者其他帧级别特征提取方法。论文中具体使用的计算方法未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的KFP策略能够有效缓解事件关系幻觉,且不影响推理速度。具体性能提升数据未知,但论文强调KFP策略在不牺牲效率的前提下,提高了VideoLLM对事件关系的理解能力。该方法在VERHallu基准测试上取得了显著的性能提升,证明了其有效性。
🎯 应用场景
该研究成果可应用于视频内容理解、智能监控、视频检索、视频摘要等领域。通过缓解视频大语言模型中的事件关系幻觉,可以提高模型对视频内容的理解准确性,从而提升相关应用的用户体验和性能。未来,该研究可以进一步扩展到更复杂的视频场景和事件关系推理任务中。
📄 摘要(原文)
Video Large Language Models (VideoLLMs) exhibit various types of hallucinations. Existing research has primarily focused on hallucinations involving the presence of events, objects, and scenes in videos, while largely neglecting event relation hallucination. In this paper, we introduce a novel benchmark for evaluating the Video Event Relation Hallucination, named VERHallu. This benchmark focuses on causal, temporal, and subevent relations between events, encompassing three types of tasks: relation classification, question answering, and counterfactual question answering, for a comprehensive evaluation of event relation hallucination. Additionally, it features counterintuitive video scenarios that deviate from typical pretraining distributions, with each sample accompanied by human-annotated candidates covering both vision-language and pure language biases. Our analysis reveals that current state-of-the-art VideoLLMs struggle with dense-event relation reasoning, often relying on prior knowledge due to insufficient use of frame-level cues. Although these models demonstrate strong grounding capabilities for key events, they often overlook the surrounding subevents, leading to an incomplete and inaccurate understanding of event relations. To tackle this, we propose a Key-Frame Propagating (KFP) strategy, which reallocates frame-level attention within intermediate layers to enhance multi-event understanding. Experiments show it effectively mitigates the event relation hallucination without affecting inference speed.