EditEmoTalk: Controllable Speech-Driven 3D Facial Animation with Continuous Expression Editing
作者: Diqiong Jiang, Kai Zhu, Dan Song, Jian Chang, Chenglizhao Chen, Zhenyu Wu
分类: cs.MM, cs.CV
发布日期: 2026-01-15
💡 一句话要点
EditEmoTalk:提出可控的语音驱动3D面部动画框架,支持连续表情编辑
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 语音驱动 3D面部动画 情感编辑 连续表情 语义嵌入
📋 核心要点
- 现有语音驱动的3D面部动画方法难以实现连续和细粒度的情感控制,因为它们依赖于离散的情感类别。
- EditEmoTalk利用边界感知的语义嵌入学习情感决策边界的法线方向,构建连续表情流形,实现平滑的情感操作。
- 通过情感一致性损失,EditEmoTalk确保生成的面部运动与目标情感在语义上对齐,从而保证情感表达的准确性。
📝 摘要(中文)
本文提出EditEmoTalk,一个可控的语音驱动3D面部动画框架,支持连续的表情编辑。现有方法通常依赖于离散的情感类别,限制了连续和细粒度的情感控制。本文的核心思想是利用边界感知的语义嵌入,学习情感决策边界的法线方向,从而实现用于平滑情感操作的连续表情流形。此外,本文引入了一种情感一致性损失,通过映射网络强制生成的运动动态和目标情感嵌入之间的语义对齐,确保忠实的情感表达。大量实验表明,EditEmoTalk在保持准确的唇部同步的同时,实现了卓越的可控性、表现力和泛化能力。代码和预训练模型将会开源。
🔬 方法详解
问题定义:语音驱动3D面部动画旨在从音频直接生成逼真且富有表现力的面部运动。然而,现有方法通常依赖于离散的情感类别,这限制了对情感的连续和细粒度控制。这些方法难以实现平滑的情感过渡和精确的情感表达,缺乏灵活性和可控性。
核心思路:EditEmoTalk的核心思路是构建一个连续的表情流形,允许用户在情感空间中平滑地操作和编辑表情。通过学习情感决策边界的法线方向,该方法能够理解不同情感之间的关系,并生成自然的情感过渡。这种方法避免了离散情感类别带来的限制,实现了更精细的情感控制。
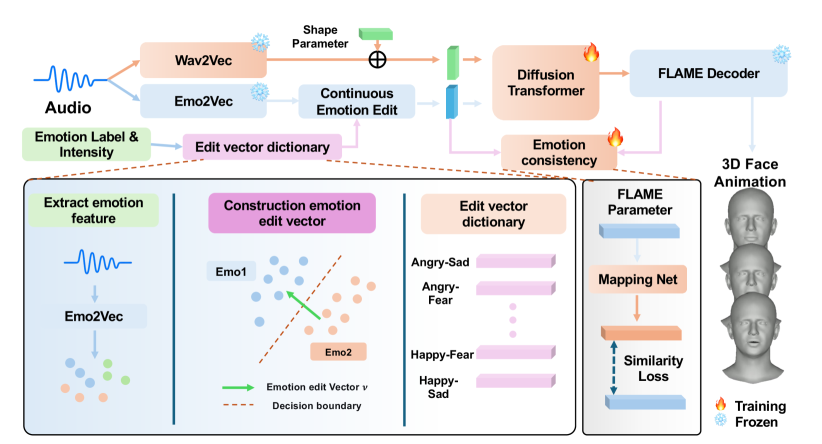
技术框架:EditEmoTalk框架主要包含以下几个模块:1) 语音特征提取模块,用于提取音频中的语音特征。2) 边界感知语义嵌入模块,用于学习情感决策边界的法线方向,构建连续表情流形。3) 运动生成模块,用于根据语音特征和情感嵌入生成3D面部运动。4) 情感一致性映射网络,用于确保生成的运动动态与目标情感嵌入之间的语义对齐。
关键创新:EditEmoTalk的关键创新在于边界感知的语义嵌入和情感一致性损失。边界感知的语义嵌入能够学习情感决策边界的法线方向,从而构建连续表情流形,实现平滑的情感操作。情感一致性损失通过映射网络强制生成的运动动态和目标情感嵌入之间的语义对齐,确保忠实的情感表达。与现有方法相比,EditEmoTalk能够实现更精细的情感控制和更自然的情感过渡。
关键设计:边界感知语义嵌入模块使用多层感知机(MLP)学习情感决策边界的法线方向。情感一致性损失采用均方误差(MSE)损失函数,用于衡量生成的运动动态和目标情感嵌入之间的差异。情感一致性映射网络使用残差连接的卷积神经网络(CNN),用于将运动动态映射到情感嵌入空间。
🖼️ 关键图片

📊 实验亮点
实验结果表明,EditEmoTalk在可控性、表现力和泛化能力方面均优于现有方法。通过定量评估和定性比较,证明了EditEmoTalk能够生成更逼真、更富有表现力的3D面部动画,同时保持准确的唇部同步。用户研究也表明,EditEmoTalk生成的动画在情感表达方面更符合人类的感知。
🎯 应用场景
EditEmoTalk在虚拟形象、游戏开发、电影制作、在线教育等领域具有广泛的应用前景。它可以用于创建更具表现力和互动性的虚拟角色,提升用户体验。此外,该技术还可以应用于情感分析、人机交互等领域,帮助机器更好地理解和响应人类情感。未来,EditEmoTalk有望成为构建更智能、更人性化的人工智能系统的重要组成部分。
📄 摘要(原文)
Speech-driven 3D facial animation aims to generate realistic and expressive facial motions directly from audio. While recent methods achieve high-quality lip synchronization, they often rely on discrete emotion categories, limiting continuous and fine-grained emotional control. We present EditEmoTalk, a controllable speech-driven 3D facial animation framework with continuous emotion editing. The key idea is a boundary-aware semantic embedding that learns the normal directions of inter-emotion decision boundaries, enabling a continuous expression manifold for smooth emotion manipulation. Moreover, we introduce an emotional consistency loss that enforces semantic alignment between the generated motion dynamics and the target emotion embedding through a mapping network, ensuring faithful emotional expression. Extensive experiments demonstrate that EditEmoTalk achieves superior controllability, expressiveness, and generalization while maintaining accurate lip synchronization. Code and pretrained models will be released.