DR$^2$Seg: Decomposed Two-Stage Rollouts for Efficient Reasoning Segmentation in Multimodal Large Language Models
作者: Yulin He, Wei Chen, Zhikang Jian, Tianhang Guo, Wenjuan Zhou, Minglong Li
分类: cs.CV
发布日期: 2026-01-15
💡 一句话要点
提出DR$^2$Seg框架,提升多模态大语言模型在推理分割任务中的效率与精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推理分割 多模态大语言模型 自奖励学习 两阶段展开 视觉语言理解
📋 核心要点
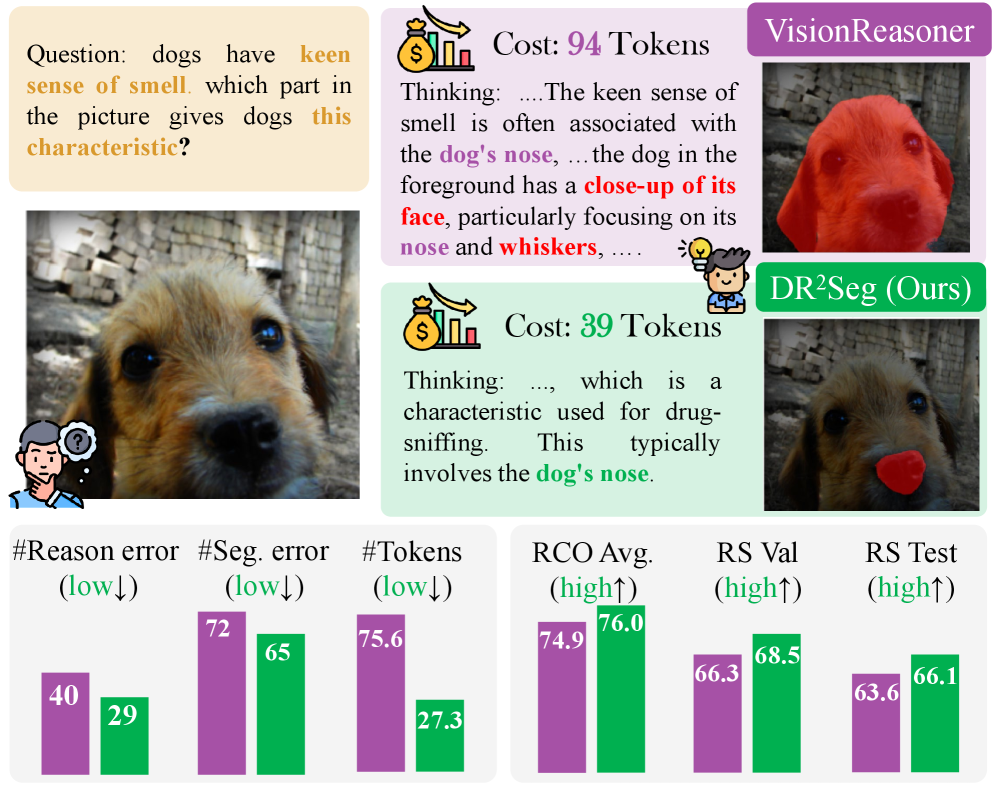
- 现有推理分割方法存在过度思考问题,生成冗余推理链,影响多模态大语言模型中的对象定位。
- DR$^2$Seg采用两阶段展开策略,分解推理分割为多模态推理和指代分割,并引入自奖励机制。
- 实验表明,DR$^2$Seg在不同规模的MLLMs和分割模型上,持续提升了推理效率和分割性能。
📝 摘要(中文)
本文提出DR$^2$Seg,一个自奖励框架,旨在提升多模态大语言模型(MLLMs)在推理分割任务中的推理效率和分割精度,无需额外的思考监督。现有方法常存在过度思考的问题,产生冗长的推理链,干扰MLLMs中的对象定位。DR$^2$Seg采用两阶段展开策略,将推理分割分解为多模态推理和指代分割。第一阶段,模型生成一个自包含的描述,明确指定目标对象。第二阶段,该描述替换原始复杂查询,以验证其自包含性。基于此设计,引入两个自奖励来加强目标导向的推理并抑制冗余思考。在不同规模的MLLMs和分割模型上的大量实验表明,DR$^2$Seg始终如一地提高了推理效率和整体分割性能。
🔬 方法详解
问题定义:推理分割任务要求模型根据复杂的文本查询精确分割图像中的对象。现有方法,特别是基于多模态大语言模型的方法,常常会生成冗长且不必要的推理链,导致“过度思考”,反而降低了对象定位的准确性,同时也降低了效率。这些冗余的推理步骤会干扰模型对关键信息的关注,使得分割结果不准确。
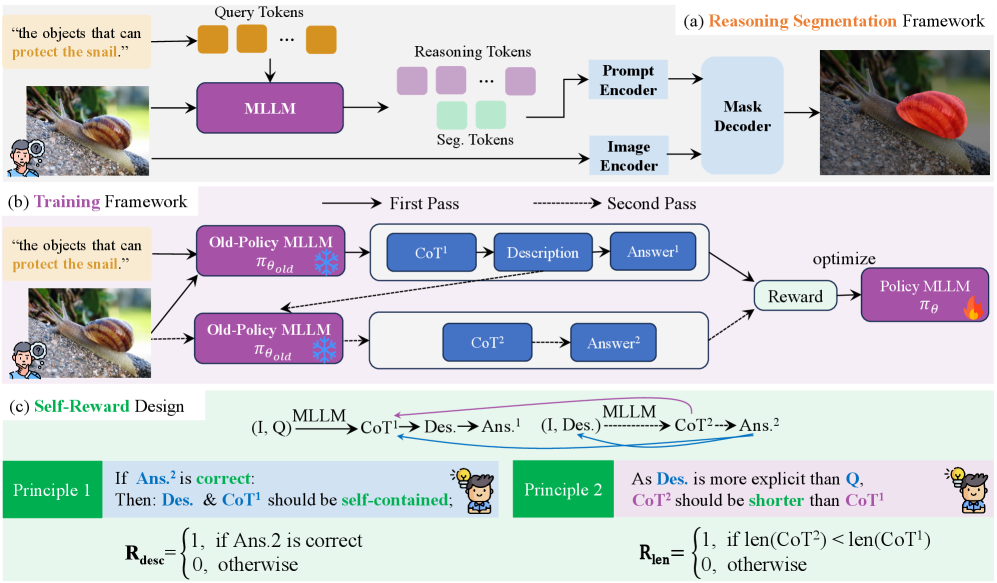
核心思路:DR$^2$Seg的核心思路是将推理分割任务分解为两个更易于管理和优化的阶段:多模态推理和指代分割。通过显式地生成一个自包含的目标对象描述,模型可以避免在后续分割阶段重新进行复杂的推理。这种分解降低了模型的认知负担,使其能够更专注于目标对象的定位。此外,自奖励机制鼓励模型生成更简洁、更目标导向的描述,从而抑制冗余思考。
技术框架:DR$^2$Seg框架包含两个主要阶段: 1. 多模态推理阶段:模型接收图像和复杂的文本查询作为输入,生成一个自包含的描述,明确指定目标对象。这个描述应该包含足够的信息,以便在没有原始复杂查询的情况下也能准确地识别目标对象。 2. 指代分割阶段:生成的描述替换原始复杂查询,与图像一起输入到分割模型中。分割模型根据这个自包含的描述来分割图像中的目标对象。框架还包含一个自奖励机制,用于评估生成的描述的质量,并根据评估结果调整模型的行为。
关键创新:DR$^2$Seg的关键创新在于其两阶段展开策略和自奖励机制。两阶段展开策略通过分解任务降低了模型的认知负担,使其能够更专注于目标对象的定位。自奖励机制则鼓励模型生成更简洁、更目标导向的描述,从而抑制冗余思考。与现有方法相比,DR$^2$Seg不需要额外的思考监督,而是通过自我评估和奖励来优化模型的行为。
关键设计:DR$^2$Seg的关键设计包括: 1. 自包含描述生成:模型需要学习如何生成包含足够信息的描述,以便在没有原始复杂查询的情况下也能准确地识别目标对象。这可能涉及到使用特定的提示工程技术或训练策略。 2. 自奖励函数:设计两个自奖励函数,分别用于加强目标导向的推理和抑制冗余思考。具体的奖励函数形式未知,但其目标是鼓励模型生成简洁、准确的描述。 3. 两阶段训练:模型需要进行两阶段训练,分别优化多模态推理阶段和指代分割阶段。具体的训练策略未知,但其目标是使模型能够有效地生成自包含的描述,并根据这些描述准确地分割图像中的目标对象。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DR$^2$Seg在不同规模的MLLMs和分割模型上都取得了显著的性能提升。具体的数据和对比基线未知,但摘要强调DR$^2$Seg能够持续提高推理效率和整体分割性能,证明了该方法的有效性和泛化能力。该方法无需额外的思考监督,更具实用价值。
🎯 应用场景
DR$^2$Seg具有广泛的应用前景,例如智能图像编辑、视觉问答、机器人导航和自动驾驶等领域。通过提高推理效率和分割精度,该方法可以使机器人在复杂环境中更好地理解和操作,提升人机交互的自然性和准确性。未来,该研究可以扩展到更复杂的场景和任务中,例如视频理解和三维场景理解。
📄 摘要(原文)
Reasoning segmentation is an emerging vision-language task that requires reasoning over intricate text queries to precisely segment objects. However, existing methods typically suffer from overthinking, generating verbose reasoning chains that interfere with object localization in multimodal large language models (MLLMs). To address this issue, we propose DR$^2$Seg, a self-rewarding framework that improves both reasoning efficiency and segmentation accuracy without requiring extra thinking supervision. DR$^2$Seg employs a two-stage rollout strategy that decomposes reasoning segmentation into multimodal reasoning and referring segmentation. In the first stage, the model generates a self-contained description that explicitly specifies the target object. In the second stage, this description replaces the original complex query to verify its self-containment. Based on this design, two self-rewards are introduced to strengthen goal-oriented reasoning and suppress redundant thinking. Extensive experiments across MLLMs of varying scales and segmentation models demonstrate that DR$^2$Seg consistently improves reasoning efficiency and overall segmentation performance.