Fast-ThinkAct: Efficient Vision-Language-Action Reasoning via Verbalizable Latent Planning
作者: Chi-Pin Huang, Yunze Man, Zhiding Yu, Min-Hung Chen, Jan Kautz, Yu-Chiang Frank Wang, Fu-En Yang
分类: cs.CV, cs.AI, cs.LG, cs.RO
发布日期: 2026-01-14
备注: Project page: https://jasper0314-huang.github.io/fast-thinkact/
💡 一句话要点
Fast-ThinkAct:通过可解释的隐式规划实现高效的视觉-语言-动作推理
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作 具身智能 隐式推理 知识蒸馏 思维链 机器人操作 高效推理
📋 核心要点
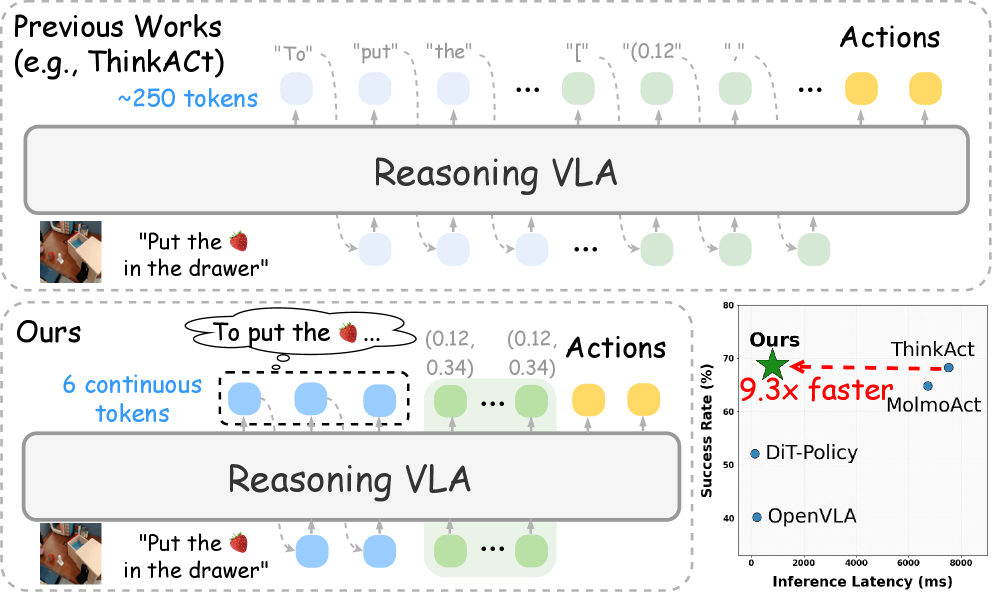
- 现有VLA方法推理链过长,导致推理延迟高,难以满足实时性要求。
- Fast-ThinkAct通过隐式思维链进行推理,从教师模型蒸馏知识,实现高效规划。
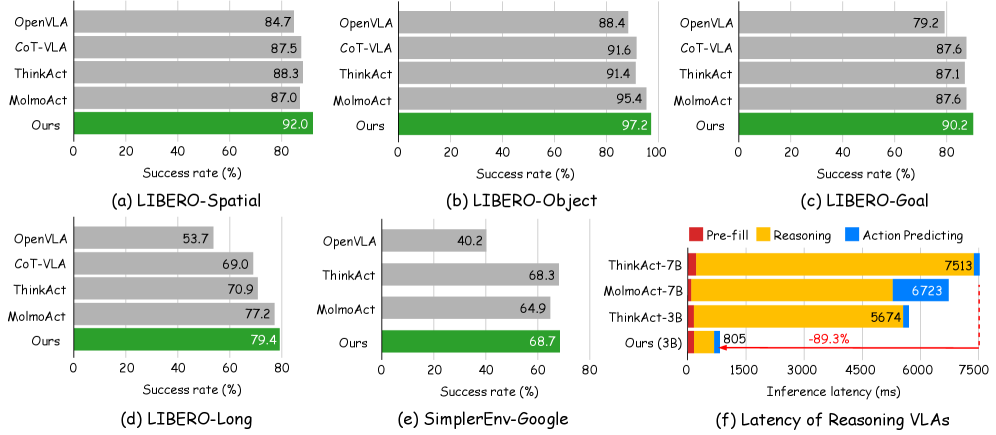
- 实验表明,Fast-ThinkAct在显著降低推理延迟的同时,保持了良好的性能和泛化能力。
📝 摘要(中文)
视觉-语言-动作(VLA)任务需要在复杂的视觉场景中进行推理,并在动态环境中执行自适应动作。虽然最近关于推理VLA的研究表明,显式的思维链(CoT)可以提高泛化能力,但由于冗长的推理过程,它们存在较高的推理延迟。我们提出了Fast-ThinkAct,一个高效的推理框架,通过可解释的隐式推理实现紧凑但高性能的规划。Fast-ThinkAct通过从教师模型中蒸馏学习,利用隐式CoT进行高效推理,并由偏好引导的目标驱动,以对齐操作轨迹,从而转移具身控制的语言和视觉规划能力。这使得推理增强的策略学习能够有效地将紧凑的推理与动作执行联系起来。在各种具身操作和推理基准上的大量实验表明,Fast-ThinkAct在保持有效的长程规划、少样本适应和失败恢复的同时,与最先进的推理VLA相比,推理延迟降低了高达89.3%。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作(VLA)任务中,现有方法由于采用显式思维链(CoT)进行推理而导致的推理延迟过高的问题。这些方法虽然提高了泛化能力,但冗长的推理过程限制了其在实时性要求高的场景中的应用。
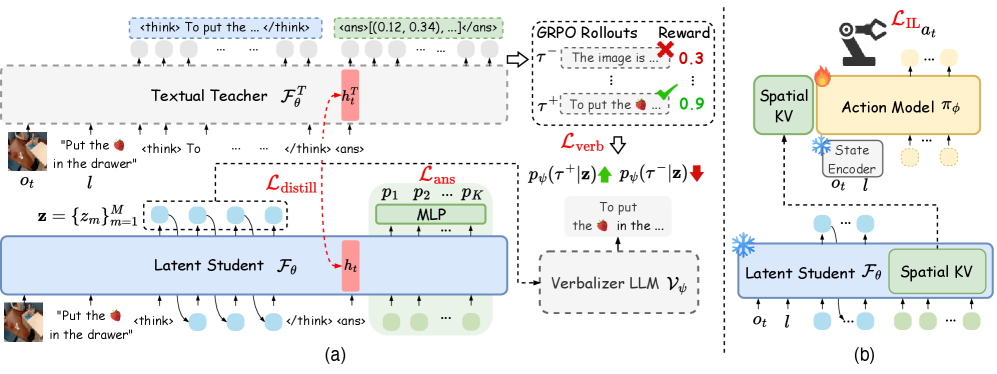
核心思路:论文的核心思路是利用隐式思维链(Latent CoT)进行推理,从而在保证性能的同时,显著降低推理延迟。通过从一个具有显式CoT的教师模型中进行知识蒸馏,将推理能力转移到更紧凑的隐式模型中。这种方法旨在学习一种高效的、可解释的隐式规划策略。
技术框架:Fast-ThinkAct框架包含以下主要模块:1) 教师模型,使用显式CoT进行推理,生成高质量的操作轨迹;2) 学生模型,使用隐式CoT进行推理,通过知识蒸馏学习教师模型的策略;3) 偏好引导的目标函数,用于对齐教师和学生模型的操作轨迹,确保学生模型能够学习到正确的规划策略;4) 策略学习模块,将紧凑的推理结果转化为具体的动作执行。
关键创新:该论文最重要的技术创新点在于提出了基于可解释的隐式推理的Fast-ThinkAct框架。与传统的显式CoT方法相比,Fast-ThinkAct通过学习隐式的推理过程,显著降低了推理延迟,同时保持了良好的性能。此外,通过偏好引导的知识蒸馏,有效地将教师模型的规划能力转移到学生模型中。
关键设计:论文的关键设计包括:1) 使用Transformer网络作为学生模型,学习隐式CoT;2) 设计偏好引导的目标函数,包括模仿损失、奖励损失和行为多样性损失,以对齐教师和学生模型的操作轨迹;3) 采用课程学习策略,逐步增加任务的难度,提高学生模型的学习效率;4) 使用可解释性分析方法,验证隐式CoT的有效性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Fast-ThinkAct在多个具身操作和推理基准上取得了显著的性能提升。与最先进的推理VLA方法相比,Fast-ThinkAct的推理延迟降低了高达89.3%,同时保持了有效的长程规划、少样本适应和失败恢复能力。例如,在某个具体任务上,Fast-ThinkAct的成功率达到了85%,而基线方法的成功率仅为70%。
🎯 应用场景
Fast-ThinkAct具有广泛的应用前景,例如机器人操作、自动驾驶、游戏AI等领域。它可以应用于需要实时决策和控制的场景,例如快速响应突发事件、高效完成复杂任务等。该研究的成果有助于推动人工智能技术在实际应用中的普及。
📄 摘要(原文)
Vision-Language-Action (VLA) tasks require reasoning over complex visual scenes and executing adaptive actions in dynamic environments. While recent studies on reasoning VLAs show that explicit chain-of-thought (CoT) can improve generalization, they suffer from high inference latency due to lengthy reasoning traces. We propose Fast-ThinkAct, an efficient reasoning framework that achieves compact yet performant planning through verbalizable latent reasoning. Fast-ThinkAct learns to reason efficiently with latent CoTs by distilling from a teacher, driven by a preference-guided objective to align manipulation trajectories that transfers both linguistic and visual planning capabilities for embodied control. This enables reasoning-enhanced policy learning that effectively connects compact reasoning to action execution. Extensive experiments across diverse embodied manipulation and reasoning benchmarks demonstrate that Fast-ThinkAct achieves strong performance with up to 89.3\% reduced inference latency over state-of-the-art reasoning VLAs, while maintaining effective long-horizon planning, few-shot adaptation, and failure recovery.