Efficient Camera-Controlled Video Generation of Static Scenes via Sparse Diffusion and 3D Rendering
作者: Jieying Chen, Jeffrey Hu, Joan Lasenby, Ayush Tewari
分类: cs.CV
发布日期: 2026-01-14
备注: Project page: https://ayushtewari.com/projects/srender/
💡 一句话要点
SRENDER:利用稀疏扩散和3D渲染实现高效相机控制的静态场景视频生成
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频生成 扩散模型 3D渲染 相机控制 关键帧 静态场景 实时交互 神经渲染
📋 核心要点
- 现有的基于扩散模型的视频生成方法计算效率低下,难以满足实时交互应用的需求。
- 该论文提出SRENDER,通过稀疏关键帧扩散生成和3D渲染,在保证几何一致性的前提下,大幅降低计算成本。
- 实验表明,SRENDER在保持视觉质量和时间稳定性的同时,视频生成速度比基线方法快40倍以上。
📝 摘要(中文)
本文提出了一种针对静态场景的相机控制视频生成新策略。该方法利用扩散模型生成稀疏的关键帧集合,然后通过3D重建和渲染合成完整的视频。通过将关键帧提升到3D表示并渲染中间视角,该方法在数百帧上分摊生成成本,同时保证了几何一致性。此外,本文还引入了一个模型来预测给定相机轨迹的最佳关键帧数量,使系统能够自适应地分配计算资源。最终方法SRENDER对于简单轨迹使用非常稀疏的关键帧,而对于复杂的相机运动则使用更密集的关键帧。实验结果表明,在生成20秒视频时,SRENDER比基于扩散的基线方法快40倍以上,同时保持了高视觉保真度和时间稳定性,为高效且可控的视频合成提供了一条实用途径。
🔬 方法详解
问题定义:现有的基于扩散模型的视频生成方法,尤其是相机控制的视频生成,计算成本非常高昂,生成几秒钟的视频需要大量的GPU时间。这使得它们难以应用于需要实时交互的场景,例如具身智能和VR/AR。现有方法的痛点在于需要对每一帧都进行扩散生成,计算量巨大。
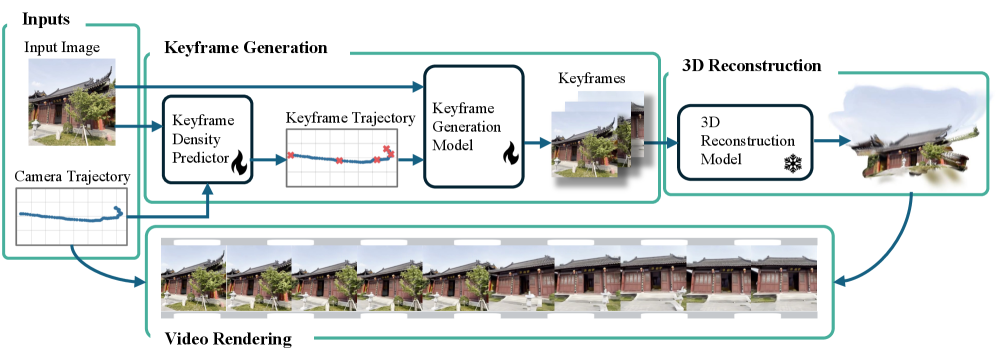
核心思路:论文的核心思路是利用静态场景的特性,只对少量关键帧进行扩散生成,然后通过3D重建和渲染技术,从这些关键帧中合成出完整的视频序列。这样可以将扩散生成的计算成本分摊到多个帧上,从而显著提高生成效率。此外,论文还引入自适应关键帧选择机制,根据相机轨迹的复杂程度动态调整关键帧的数量。
技术框架:SRENDER的整体框架包含以下几个主要模块:1) 关键帧选择模块:根据给定的相机轨迹,预测最佳的关键帧数量和位置。2) 关键帧生成模块:使用扩散模型生成选定的关键帧。3) 3D重建模块:将生成的关键帧提升到3D空间,进行场景重建。4) 渲染模块:根据相机轨迹,渲染出中间帧,从而生成完整的视频序列。
关键创新:SRENDER的关键创新在于将扩散模型和3D渲染技术相结合,用于相机控制的视频生成。与直接对每一帧进行扩散生成的方法相比,SRENDER只需要生成少量的关键帧,从而大大降低了计算成本。此外,自适应关键帧选择机制可以根据相机轨迹的复杂程度动态调整关键帧的数量,进一步提高了生成效率。
关键设计:关键帧选择模块使用一个神经网络来预测关键帧的数量和位置,该网络以相机轨迹作为输入,并输出关键帧的索引。关键帧生成模块可以使用各种现有的扩散模型,例如DDPM或Stable Diffusion。3D重建模块可以使用各种现有的多视图几何算法,例如Structure-from-Motion或Neural Radiance Fields (NeRF)。渲染模块可以使用传统的渲染技术或神经渲染技术。
🖼️ 关键图片


📊 实验亮点
SRENDER在静态场景的相机控制视频生成任务上取得了显著的性能提升。实验结果表明,在生成20秒的视频时,SRENDER比基于扩散的基线方法快40倍以上,同时保持了高视觉保真度和时间稳定性。此外,SRENDER的自适应关键帧选择机制可以根据相机轨迹的复杂程度动态调整关键帧的数量,进一步提高了生成效率。这些结果表明,SRENDER是一种高效且可控的视频合成方法。
🎯 应用场景
SRENDER具有广泛的应用前景,尤其是在需要实时交互的场景中。例如,它可以用于VR/AR应用中,根据用户的头部运动生成逼真的虚拟环境视频。此外,它还可以用于具身智能领域,帮助机器人根据环境变化生成相应的视频反馈。该研究的成果将推动视频生成技术在实时交互领域的应用,并为未来的虚拟现实和人工智能发展提供技术支持。
📄 摘要(原文)
Modern video generative models based on diffusion models can produce very realistic clips, but they are computationally inefficient, often requiring minutes of GPU time for just a few seconds of video. This inefficiency poses a critical barrier to deploying generative video in applications that require real-time interactions, such as embodied AI and VR/AR. This paper explores a new strategy for camera-conditioned video generation of static scenes: using diffusion-based generative models to generate a sparse set of keyframes, and then synthesizing the full video through 3D reconstruction and rendering. By lifting keyframes into a 3D representation and rendering intermediate views, our approach amortizes the generation cost across hundreds of frames while enforcing geometric consistency. We further introduce a model that predicts the optimal number of keyframes for a given camera trajectory, allowing the system to adaptively allocate computation. Our final method, SRENDER, uses very sparse keyframes for simple trajectories and denser ones for complex camera motion. This results in video generation that is more than 40 times faster than the diffusion-based baseline in generating 20 seconds of video, while maintaining high visual fidelity and temporal stability, offering a practical path toward efficient and controllable video synthesis.