STEP3-VL-10B Technical Report
作者: Ailin Huang, Chengyuan Yao, Chunrui Han, Fanqi Wan, Hangyu Guo, Haoran Lv, Hongyu Zhou, Jia Wang, Jian Zhou, Jianjian Sun, Jingcheng Hu, Kangheng Lin, Liang Zhao, Mitt Huang, Song Yuan, Wenwen Qu, Xiangfeng Wang, Yanlin Lai, Yingxiu Zhao, Yinmin Zhang, Yukang Shi, Yuyang Chen, Zejia Weng, Ziyang Meng, Ang Li, Aobo Kong, Bo Dong, Changyi Wan, David Wang, Di Qi, Dingming Li, En Yu, Guopeng Li, Haiquan Yin, Han Zhou, Hanshan Zhang, Haolong Yan, Hebin Zhou, Hongbo Peng, Jiaran Zhang, Jiashu Lv, Jiayi Fu, Jie Cheng, Jie Zhou, Jisheng Yin, Jingjing Xie, Jingwei Wu, Jun Zhang, Junfeng Liu, Kaijun Tan, Kaiwen Yan, Liangyu Chen, Lina Chen, Mingliang Li, Qian Zhao, Quan Sun, Shaoliang Pang, Shengjie Fan, Shijie Shang, Siyuan Zhang, Tianhao You, Wei Ji, Wuxun Xie, Xiaobo Yang, Xiaojie Hou, Xiaoran Jiao, Xiaoxiao Ren, Xiangwen Kong, Xin Huang, Xin Wu, Xing Chen, Xinran Wang, Xuelin Zhang, Yana Wei, Yang Li, Yanming Xu, Yeqing Shen, Yuang Peng, Yue Peng, Yu Zhou, Yusheng Li, Yuxiang Yang, Yuyang Zhang, Zhe Xie, Zhewei Huang, Zhenyi Lu, Zhimin Fan, Zihui Cheng, Daxin Jiang, Qi Han, Xiangyu Zhang, Yibo Zhu, Zheng Ge
分类: cs.CV
发布日期: 2026-01-14
备注: 50 pages
💡 一句话要点
STEP3-VL-10B:一种轻量级多模态基础模型,通过高效预训练和强化学习实现卓越性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉语言模型 轻量级模型 强化学习 预训练 推理 并行计算
📋 核心要点
- 现有大型多模态模型计算成本高昂,难以部署和复现,限制了其在实际应用中的普及。
- STEP3-VL-10B通过统一的预训练策略和强化学习后训练,在保持模型轻量化的同时,提升了视觉-语言协同能力和推理性能。
- 实验结果表明,STEP3-VL-10B在多个基准测试中超越了参数量大10-20倍的模型,展现了卓越的性能。
📝 摘要(中文)
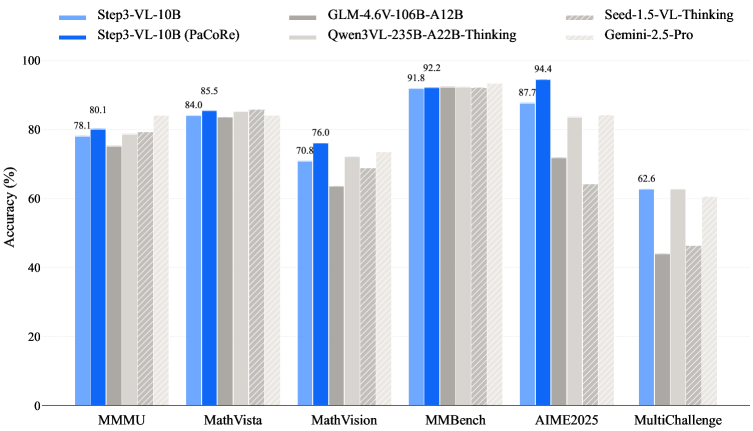
本文介绍了STEP3-VL-10B,一个轻量级的开源基础模型,旨在重新定义紧凑效率和前沿多模态智能之间的权衡。STEP3-VL-10B的实现依赖于两个战略性转变:首先,在1.2T多模态tokens上采用统一的、完全解冻的预训练策略,该策略集成了语言对齐的感知编码器和Qwen3-8B解码器,以建立内在的视觉-语言协同作用;其次,采用大规模的后训练流程,包含超过1k次迭代的强化学习。至关重要的是,我们实现了并行协调推理(PaCoRe)来扩展测试时计算,将资源分配给可扩展的感知推理,从而探索和综合不同的视觉假设。因此,尽管其紧凑的10B参数规模,STEP3-VL-10B可以媲美甚至超越大10-20倍的模型(例如,GLM-4.6V-106B,Qwen3-VL-235B)以及顶级的专有旗舰模型,如Gemini 2.5 Pro和Seed-1.5-VL。它提供了同类最佳的性能,在MMBench上记录了92.2%,在MMMU上记录了80.11%,同时在复杂推理方面表现出色,在AIME2025上达到94.43%,在MathVision上达到75.95%。我们发布完整的模型套件,为社区提供一个强大、高效且可复现的基线。
🔬 方法详解
问题定义:现有的大型视觉语言模型(VLM)通常参数量巨大,导致计算成本高昂,难以部署和复现。这限制了它们在资源受限环境中的应用,并且阻碍了研究人员对模型内部机制的深入理解。因此,需要开发一种轻量级且高性能的VLM,能够在保持竞争力的同时,降低计算负担。
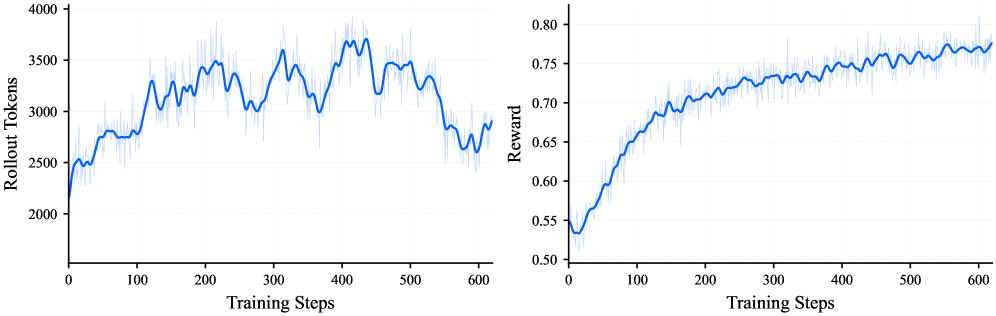
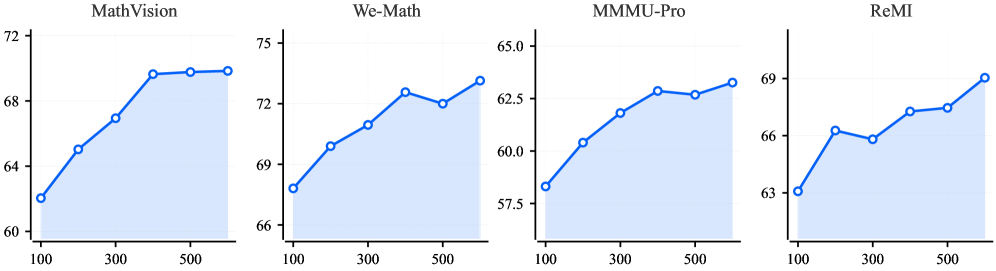
核心思路:STEP3-VL-10B的核心思路是通过高效的预训练和后训练策略,在有限的参数规模下,最大化模型的视觉-语言理解和推理能力。具体来说,它采用统一的、完全解冻的预训练方法,以建立内在的视觉-语言协同作用,并通过强化学习进行后训练,以进一步提升模型的性能。此外,引入并行协调推理(PaCoRe)来扩展测试时计算,从而探索和综合不同的视觉假设。
技术框架:STEP3-VL-10B的整体框架包括以下几个主要模块:1) 语言对齐的感知编码器:用于提取图像的视觉特征,并将其映射到与语言空间对齐的表示;2) Qwen3-8B解码器:作为语言模型,用于生成文本描述或回答问题;3) 统一预训练:在1.2T多模态tokens上进行预训练,以学习视觉和语言之间的关联;4) 强化学习后训练:通过强化学习算法,进一步优化模型的性能;5) 并行协调推理(PaCoRe):在测试时,分配计算资源进行可扩展的感知推理。
关键创新:STEP3-VL-10B的关键创新在于其高效的预训练和后训练策略,以及并行协调推理(PaCoRe)机制。与传统的预训练方法不同,STEP3-VL-10B采用完全解冻的预训练策略,允许所有参数在训练过程中进行更新,从而更好地学习视觉和语言之间的关联。PaCoRe机制则通过并行探索不同的视觉假设,并综合这些假设来提高推理的准确性。
关键设计:在预训练阶段,使用了1.2T tokens的多模态数据集。强化学习后训练的具体算法未知,但强调了超过1k次的迭代。PaCoRe的具体实现细节未知,但其核心思想是分配资源进行可扩展的感知推理,探索和综合不同的视觉假设。
🖼️ 关键图片
📊 实验亮点
STEP3-VL-10B在多个基准测试中取得了显著的成果。在MMBench上达到了92.2%的准确率,在MMMU上达到了80.11%的准确率。更重要的是,在需要复杂推理的任务中,例如AIME2025和MathVision,分别达到了94.43%和75.95%的准确率。这些结果表明,STEP3-VL-10B在视觉-语言理解和推理方面具有卓越的性能,甚至超越了参数量大10-20倍的模型。
🎯 应用场景
STEP3-VL-10B具有广泛的应用前景,包括智能问答、图像描述、视觉推理、机器人导航等。由于其轻量级的特性,它可以部署在资源受限的设备上,例如移动设备和嵌入式系统。该模型可以赋能各种应用,例如智能客服、自动驾驶、智能家居等,并促进人机交互的智能化。
📄 摘要(原文)
We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.