CogRail: Benchmarking VLMs in Cognitive Intrusion Perception for Intelligent Railway Transportation Systems
作者: Yonglin Tian, Qiyao Zhang, Wei Xu, Yutong Wang, Yihao Wu, Xinyi Li, Xingyuan Dai, Hui Zhang, Zhiyong Cui, Baoqing Guo, Zujun Yu, Yisheng Lv
分类: cs.CV, cs.AI
发布日期: 2026-01-14
🔗 代码/项目: GITHUB
💡 一句话要点
CogRail:构建铁路入侵认知感知基准,并提出联合微调框架提升VLM性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 铁路安全 入侵感知 视觉语言模型 时空推理 多任务学习
📋 核心要点
- 现有铁路安全系统在入侵感知方面存在局限,主要依赖于固定视觉范围内的目标分类和简单的规则判断,缺乏对潜在风险的时空推理能力。
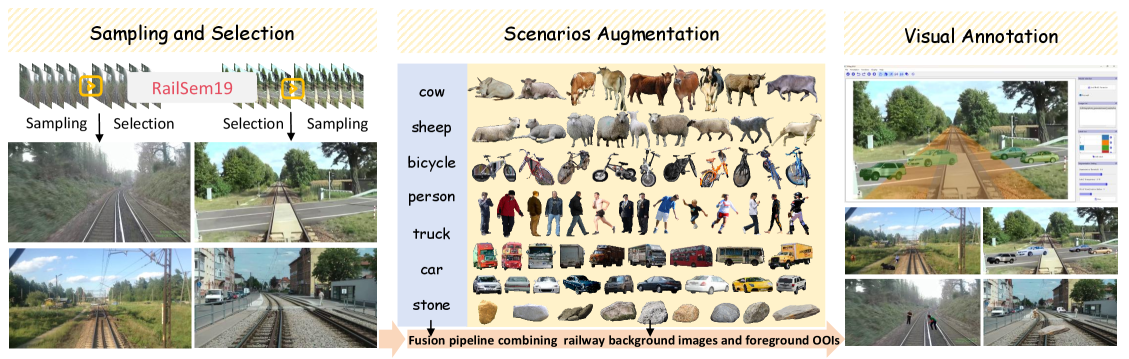
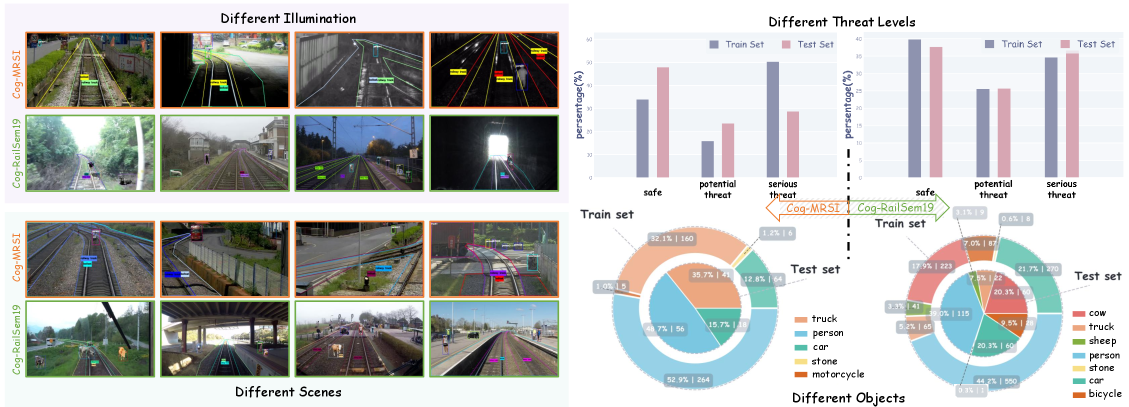
- 论文提出CogRail基准,包含数据集和认知驱动的问答注释,用于评估和提升视觉语言模型在铁路入侵认知感知方面的能力。
- 论文提出联合微调框架,整合位置感知、运动预测和威胁分析三个核心任务,显著提升了VLM在CogRail基准上的性能。
📝 摘要(中文)
为了确保铁路运输系统的安全,准确且及早地感知潜在入侵目标至关重要。现有系统主要关注固定视觉范围内的目标分类,并应用基于规则的启发式方法来确定入侵状态,常常忽略潜在的入侵风险。预测此类风险需要对感兴趣对象(OOI)进行时空上下文认知,这对传统视觉模型提出了挑战。为此,我们引入了一个新的基准CogRail,它集成了精心策划的开源数据集和认知驱动的问答注释,以支持时空推理和预测。在此基础上,我们使用多模态提示对最先进的视觉语言模型(VLM)进行了系统评估,以识别它们在该领域的优势和局限性。此外,我们对VLM进行了微调以获得更好的性能,并提出了一个联合微调框架,该框架集成了三个核心任务:位置感知、运动预测和威胁分析,从而促进了通用基础模型有效适应于专门的认知入侵感知模型。大量实验表明,当前的大规模多模态模型难以应对认知入侵感知任务所需的复杂时空推理,突显了现有基础模型在这个安全关键领域的局限性。相比之下,我们提出的联合微调框架通过实现针对特定领域推理需求的有针对性适应,显著提高了模型性能,突出了结构化多任务学习在提高准确性和可解释性方面的优势。
🔬 方法详解
问题定义:现有铁路入侵检测系统主要依赖于对固定场景中物体的简单分类,缺乏对潜在入侵风险的时空推理能力。这些系统难以理解物体间的关系、运动趋势以及环境上下文,导致对潜在威胁的早期预警能力不足。现有方法的痛点在于无法进行高级认知推理,难以适应复杂多变的铁路环境。
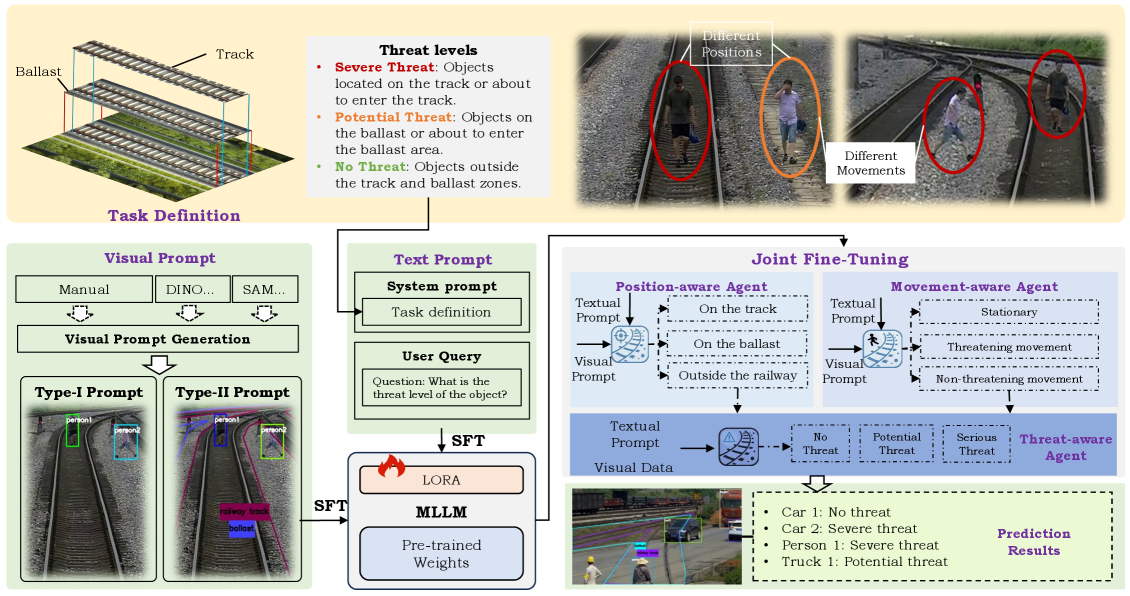
核心思路:论文的核心思路是通过构建一个包含时空推理和预测任务的基准数据集CogRail,并结合多任务联合微调策略,提升视觉语言模型(VLM)在铁路入侵认知感知方面的能力。通过让模型学习位置感知、运动预测和威胁分析,使其能够更好地理解场景上下文,从而更准确地识别和预测潜在的入侵风险。
技术框架:整体框架包含两个主要部分:CogRail基准数据集的构建和VLM的联合微调。CogRail数据集包含铁路场景的图像和视频,以及针对这些场景设计的认知驱动的问答注释,涵盖了位置、运动和威胁等多个方面。VLM的联合微调框架则包含三个核心任务分支:位置感知(预测物体的位置)、运动预测(预测物体的运动轨迹)和威胁分析(判断物体是否构成威胁)。这三个任务共享VLM的底层特征提取层,并通过各自的损失函数进行优化。
关键创新:论文的关键创新在于:1)提出了CogRail基准数据集,为铁路入侵认知感知任务提供了一个标准化的评估平台。2)提出了联合微调框架,通过多任务学习的方式,有效提升了VLM在时空推理和预测方面的能力。3)将通用VLM模型迁移到铁路安全这一特定领域,并验证了其有效性。
关键设计:在联合微调框架中,每个任务分支都使用特定的损失函数进行优化。例如,位置感知任务可以使用交叉熵损失或均方误差损失,运动预测任务可以使用轨迹预测的损失函数,威胁分析任务可以使用二元交叉熵损失。此外,论文可能还探索了不同的网络结构和参数设置,以优化模型的性能。具体的网络结构和参数设置在论文中应该有详细描述,此处未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有的通用VLM模型在CogRail基准上表现不佳,难以应对复杂的时空推理任务。而论文提出的联合微调框架能够显著提升VLM的性能,在位置感知、运动预测和威胁分析等任务上均取得了明显的提升。具体提升幅度未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于智能铁路交通系统,提升铁路安全监控的智能化水平。通过对潜在入侵目标的早期感知和预测,可以有效减少安全事故的发生,保障铁路运输的安全和效率。该技术还可扩展到其他安全关键领域,如智能交通、智慧城市等,具有广阔的应用前景。
📄 摘要(原文)
Accurate and early perception of potential intrusion targets is essential for ensuring the safety of railway transportation systems. However, most existing systems focus narrowly on object classification within fixed visual scopes and apply rule-based heuristics to determine intrusion status, often overlooking targets that pose latent intrusion risks. Anticipating such risks requires the cognition of spatial context and temporal dynamics for the object of interest (OOI), which presents challenges for conventional visual models. To facilitate deep intrusion perception, we introduce a novel benchmark, CogRail, which integrates curated open-source datasets with cognitively driven question-answer annotations to support spatio-temporal reasoning and prediction. Building upon this benchmark, we conduct a systematic evaluation of state-of-the-art visual-language models (VLMs) using multimodal prompts to identify their strengths and limitations in this domain. Furthermore, we fine-tune VLMs for better performance and propose a joint fine-tuning framework that integrates three core tasks, position perception, movement prediction, and threat analysis, facilitating effective adaptation of general-purpose foundation models into specialized models tailored for cognitive intrusion perception. Extensive experiments reveal that current large-scale multimodal models struggle with the complex spatial-temporal reasoning required by the cognitive intrusion perception task, underscoring the limitations of existing foundation models in this safety-critical domain. In contrast, our proposed joint fine-tuning framework significantly enhances model performance by enabling targeted adaptation to domain-specific reasoning demands, highlighting the advantages of structured multi-task learning in improving both accuracy and interpretability. Code will be available at https://github.com/Hub-Tian/CogRail.