GRCF: Two-Stage Groupwise Ranking and Calibration Framework for Multimodal Sentiment Analysis
作者: Manning Gao, Leheng Zhang, Shiqin Han, Haifeng Hu, Yuncheng Jiang, Sijie Mai
分类: cs.CV
发布日期: 2026-01-14
💡 一句话要点
提出GRCF框架,通过分组排序和校准解决多模态情感分析中的标签噪声和排序偏差问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感分析 分组排序 动态间隔 标签噪声 序数学习 校准 GRPO
📋 核心要点
- 传统多模态情感分析的点回归方法易受标签噪声影响,忽略样本间相对情感强度,导致预测不稳定。
- GRCF框架通过两阶段学习,首先构建细粒度序数结构,然后对齐预测幅度,解决排序偏差和校准问题。
- 实验表明,GRCF在多模态情感分析回归任务上达到SOTA,并在幽默和讽刺检测等分类任务上表现出良好的泛化性。
📝 摘要(中文)
大多数多模态情感分析研究集中于点回归方法。虽然直接,但这种方法对标签噪声敏感,忽略了样本间的情感相对强度,导致预测不稳定和相关性对齐效果差。成对序数学习框架通过学习比较关系来捕捉相对顺序,但引入了两个新的权衡:一是为所有比较分配相同的权重,未能自适应地关注难以排序的样本;二是采用静态排序间隔,未能反映情感组之间不同的语义距离。为了解决这些问题,我们提出了一个两阶段分组排序和校准框架(GRCF),它借鉴了分组相对策略优化(GRPO)的思想。我们的框架通过同时保持相对序数结构、确保绝对分数校准和自适应地关注困难样本来解决这些权衡。具体来说,第一阶段引入了受GRPO启发的优势加权动态间隔排序损失,以构建细粒度的序数结构。第二阶段采用MAE驱动的目标来对齐预测幅度。为了验证其泛化性,我们将GRCF扩展到分类任务,包括多模态幽默检测和讽刺检测。GRCF在核心回归基准上实现了最先进的性能,同时在分类任务中也表现出强大的泛化性。
🔬 方法详解
问题定义:多模态情感分析旨在根据文本、音频和视频等多模态信息预测情感强度。现有点回归方法对标签噪声敏感,忽略了样本之间的相对情感顺序关系,导致模型预测不稳定,相关性对齐效果差。成对序数学习虽然考虑了样本间的相对顺序,但对所有比较赋予相同的权重,且使用静态排序间隔,无法有效处理不同情感组之间的语义距离差异。
核心思路:GRCF框架的核心思路是借鉴分组相对策略优化(GRPO)的思想,通过两阶段学习来解决上述问题。第一阶段,利用优势加权动态间隔排序损失,自适应地关注难以排序的样本,构建细粒度的序数结构。第二阶段,通过MAE驱动的目标函数,对齐预测幅度,实现绝对分数校准。
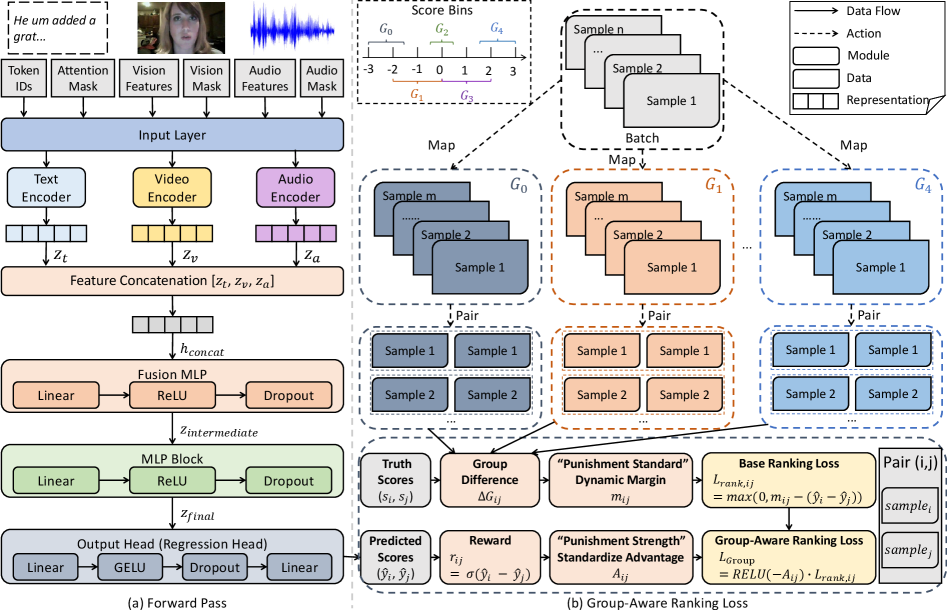
技术框架:GRCF框架包含两个主要阶段: 1. 分组排序阶段:使用优势加权动态间隔排序损失,学习样本之间的相对顺序关系。该损失函数能够根据样本的排序难度自适应地调整权重,并动态调整排序间隔。 2. 校准阶段:使用MAE损失函数,对齐模型的预测幅度,确保预测结果的绝对值与真实情感强度相符。
关键创新:GRCF的关键创新在于: 1. 优势加权动态间隔排序损失:该损失函数能够自适应地关注难以排序的样本,并动态调整排序间隔,从而更有效地学习样本之间的相对顺序关系。 2. 两阶段学习框架:通过分组排序和校准两个阶段,同时优化模型的排序能力和校准能力,从而提高模型的整体性能。
关键设计: 1. 优势函数:使用优势函数来衡量样本的排序难度,并根据排序难度调整样本的权重。优势函数的设计需要考虑样本的预测误差和排序一致性。 2. 动态间隔:根据情感组之间的语义距离动态调整排序间隔。语义距离可以使用预训练的词向量或情感词典来计算。 3. 损失函数权重:需要平衡分组排序损失和校准损失之间的权重,以获得最佳的性能。
🖼️ 关键图片

📊 实验亮点
GRCF在CMU-MOSI和CMU-MOSEI等核心多模态情感分析回归基准上取得了state-of-the-art的性能。此外,GRCF在多模态幽默检测和讽刺检测等分类任务上也表现出强大的泛化能力,证明了其有效性和通用性。具体性能数据未知,但摘要强调了其超越现有方法的优越性。
🎯 应用场景
GRCF框架可应用于各种多模态情感分析场景,例如社交媒体情感监控、客户服务质量评估、电影评论分析等。通过准确识别用户的情感倾向,可以帮助企业更好地了解用户需求,提升服务质量,并为决策提供支持。此外,该框架在多模态幽默和讽刺检测等任务上的成功应用,也表明其具有广泛的应用前景。
📄 摘要(原文)
Most Multimodal Sentiment Analysis research has focused on point-wise regression. While straightforward, this approach is sensitive to label noise and neglects whether one sample is more positive than another, resulting in unstable predictions and poor correlation alignment. Pairwise ordinal learning frameworks emerged to address this gap, capturing relative order by learning from comparisons. Yet, they introduce two new trade-offs: First, they assign uniform importance to all comparisons, failing to adaptively focus on hard-to-rank samples. Second, they employ static ranking margins, which fail to reflect the varying semantic distances between sentiment groups. To address this, we propose a Two-Stage Group-wise Ranking and Calibration Framework (GRCF) that adapts the philosophy of Group Relative Policy Optimization (GRPO). Our framework resolves these trade-offs by simultaneously preserving relative ordinal structure, ensuring absolute score calibration, and adaptively focusing on difficult samples. Specifically, Stage 1 introduces a GRPO-inspired Advantage-Weighted Dynamic Margin Ranking Loss to build a fine-grained ordinal structure. Stage 2 then employs an MAE-driven objective to align prediction magnitudes. To validate its generalizability, we extend GRCF to classification tasks, including multimodal humor detection and sarcasm detection. GRCF achieves state-of-the-art performance on core regression benchmarks, while also showing strong generalizability in classification tasks.