Sim2real Image Translation Enables Viewpoint-Robust Policies from Fixed-Camera Datasets
作者: Jeremiah Coholich, Justin Wit, Robert Azarcon, Zsolt Kira
分类: cs.CV, cs.AI, cs.RO
发布日期: 2026-01-14
💡 一句话要点
提出MANGO,通过图像转换实现固定视角数据集的视角鲁棒机器人策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: Sim2Real 图像转换 机器人操作 视角鲁棒性 模仿学习
📋 核心要点
- 现有基于视觉的机器人策略对相机视角变化敏感,而真实机器人数据难以覆盖所有视角。
- MANGO是一种非配对图像转换方法,通过分割条件InfoNCE损失等技术保持视角一致性。
- 实验表明,MANGO在视角转换任务中优于其他方法,并显著提升了模仿学习策略的性能。
📝 摘要(中文)
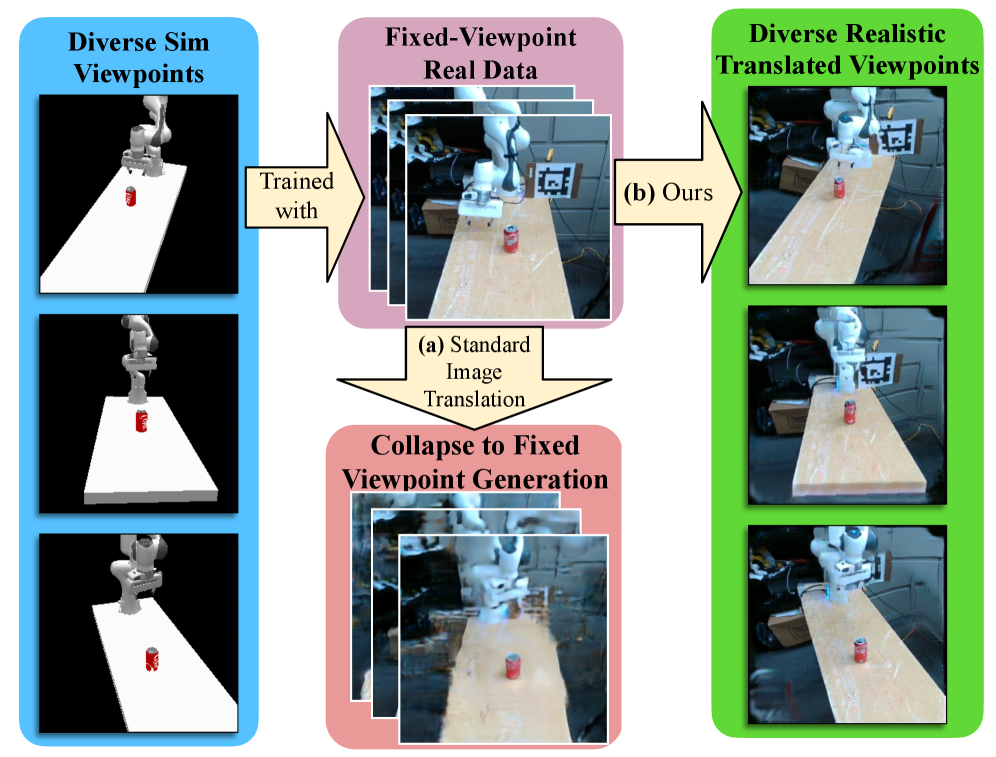
基于视觉的机器人操作策略近年来取得了显著进展,但仍然容易受到诸如相机视角变化等分布偏移的影响。机器人演示数据稀缺,且通常缺乏适当的相机视角变化。仿真提供了一种大规模收集机器人演示数据的方法,可以全面覆盖不同的视角,但也带来了视觉上的sim2real挑战。为了弥合这一差距,我们提出了一种名为MANGO的非配对图像转换方法,该方法具有新颖的分割条件InfoNCE损失、高度正则化的判别器设计和改进的PatchNCE损失。我们发现这些元素对于在sim2real转换期间保持视角一致性至关重要。在训练MANGO时,我们只需要少量来自真实世界的固定相机数据,但表明我们的方法可以通过转换模拟观察来生成各种未见过的视角。在这个领域,MANGO优于我们测试的所有其他图像转换方法。在MANGO增强的数据上训练的模仿学习策略能够在非增强策略完全失败的视角上实现高达60%的成功率。
🔬 方法详解
问题定义:论文旨在解决机器人操作中,视觉策略对相机视角变化鲁棒性差的问题。现有方法依赖大量真实数据,但真实数据难以覆盖所有视角,且采集成本高昂。Sim2Real方法可以利用仿真数据,但存在视觉差异,导致策略性能下降。
核心思路:论文的核心思路是利用图像转换技术,将仿真图像转换为真实图像,同时保持视角的一致性。通过这种方式,可以利用仿真数据生成各种视角的真实感图像,从而增强策略的视角鲁棒性。
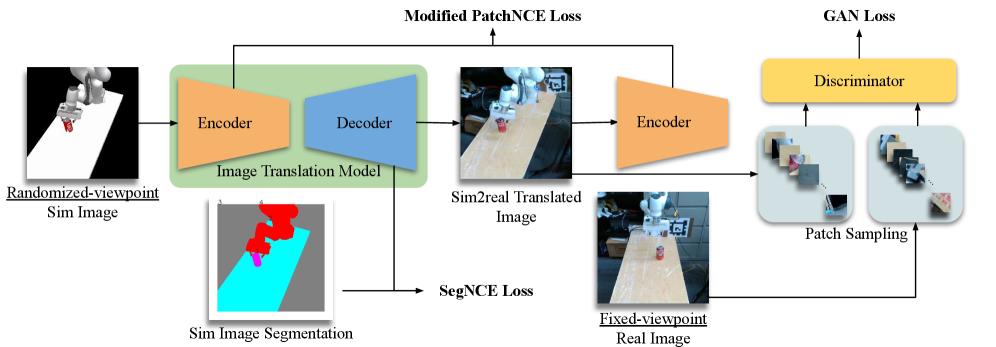
技术框架:MANGO的整体框架是一个非配对图像转换模型,基于GAN的结构。它包含一个生成器G和一个判别器D。生成器负责将仿真图像转换为真实图像,判别器负责区分生成的图像和真实的图像。此外,MANGO还引入了分割网络,用于提取图像的分割信息,辅助图像转换。
关键创新:MANGO的关键创新在于以下几个方面:1) 提出了分割条件InfoNCE损失,用于保持视角一致性;2) 设计了高度正则化的判别器,防止过拟合;3) 改进了PatchNCE损失,提高图像质量。这些创新使得MANGO在视角转换任务中表现出色。与现有方法相比,MANGO更注重保持视角一致性,从而提升了策略的鲁棒性。
关键设计:MANGO的关键设计包括:1) 分割条件InfoNCE损失:该损失利用分割信息,约束生成图像和原始图像在分割区域的特征相似性,从而保持视角一致性。2) 高度正则化的判别器:判别器采用谱归一化和梯度惩罚等技术,防止过拟合,提高泛化能力。3) 改进的PatchNCE损失:该损失在原始PatchNCE损失的基础上,引入了分割信息,使得损失更加关注前景区域,提高图像质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MANGO在视角转换任务中优于其他图像转换方法。在模仿学习任务中,使用MANGO增强的数据训练的策略,在非增强策略完全失败的视角上,成功率高达60%。这证明了MANGO在提升策略视角鲁棒性方面的有效性。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶等领域。通过图像转换技术,可以降低对真实数据的依赖,利用仿真数据训练出更鲁棒的视觉策略。这有助于降低机器人开发的成本,加速机器人在复杂环境中的应用。
📄 摘要(原文)
Vision-based policies for robot manipulation have achieved significant recent success, but are still brittle to distribution shifts such as camera viewpoint variations. Robot demonstration data is scarce and often lacks appropriate variation in camera viewpoints. Simulation offers a way to collect robot demonstrations at scale with comprehensive coverage of different viewpoints, but presents a visual sim2real challenge. To bridge this gap, we propose MANGO -- an unpaired image translation method with a novel segmentation-conditioned InfoNCE loss, a highly-regularized discriminator design, and a modified PatchNCE loss. We find that these elements are crucial for maintaining viewpoint consistency during sim2real translation. When training MANGO, we only require a small amount of fixed-camera data from the real world, but show that our method can generate diverse unseen viewpoints by translating simulated observations. In this domain, MANGO outperforms all other image translation methods we tested. Imitation-learning policies trained on data augmented by MANGO are able to achieve success rates as high as 60\% on views that the non-augmented policy fails completely on.