OpenVoxel: Training-Free Grouping and Captioning Voxels for Open-Vocabulary 3D Scene Understanding
作者: Sheng-Yu Huang, Jaesung Choe, Yu-Chiang Frank Wang, Cheng Sun
分类: cs.CV
发布日期: 2026-01-14
备注: project page: https://peterjohnsonhuang.github.io/openvoxel-pages/
💡 一句话要点
提出OpenVoxel,一种免训练的三维场景体素分组与描述算法,用于开放词汇场景理解。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 三维场景理解 开放词汇 体素分组 视觉语言模型 多模态学习 免训练学习 指代表达式分割
📋 核心要点
- 现有方法依赖于预训练的文本编码器,限制了开放词汇场景理解的能力,且需要大量训练。
- OpenVoxel利用视觉语言模型和多模态大型语言模型,直接进行体素分组和场景描述,无需训练。
- 实验表明,OpenVoxel在指代表达式分割等任务上表现优异,超越了现有方法。
📝 摘要(中文)
本文提出OpenVoxel,一种免训练算法,用于对稀疏体素进行分组和描述,以实现开放词汇的三维场景理解任务。给定从三维场景的多视角图像中获得的稀疏体素栅格化(SVR)模型,OpenVoxel能够生成有意义的组,描述场景中的不同对象。此外,通过利用强大的视觉语言模型(VLMs)和多模态大型语言模型(MLLMs),OpenVoxel成功地通过描述每个组来构建信息丰富的场景地图,从而实现进一步的三维场景理解任务,例如开放词汇分割(OVS)或指代表达式分割(RES)。与以往的方法不同,我们的方法是免训练的,并且不引入来自CLIP/BERT文本编码器的嵌入。相反,我们直接使用MLLM进行文本到文本的搜索。通过大量的实验,我们的方法展示了优于最近研究的性能,尤其是在复杂的指代表达式分割(RES)任务中。代码将会开源。
🔬 方法详解
问题定义:现有三维场景理解方法通常依赖于预训练的CLIP或BERT等文本编码器,将文本信息嵌入到特征空间中,然后进行后续处理。这种方式的缺点在于,首先,预训练的词汇表限制了模型对开放词汇的理解能力;其次,需要大量的训练数据来微调这些模型,计算成本高昂。因此,如何设计一种免训练的、能够处理开放词汇的三维场景理解方法是一个挑战。
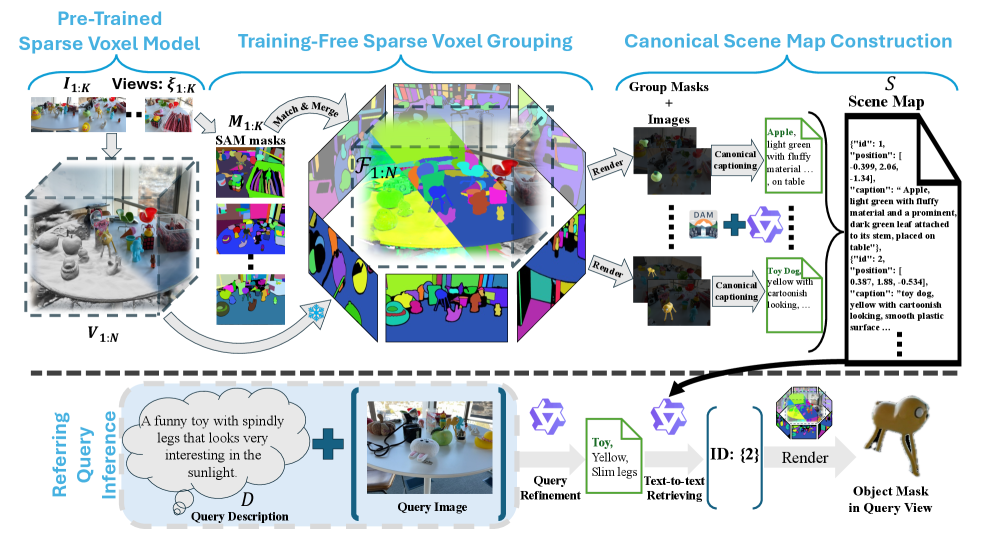
核心思路:OpenVoxel的核心思路是利用多模态大型语言模型(MLLMs)强大的文本生成和理解能力,直接对稀疏体素进行分组和描述,而无需依赖于预训练的文本编码器。通过将三维场景表示为体素集合,并利用MLLMs生成每个体素组的描述,从而实现对场景的理解。这种方法避免了对特定词汇的依赖,并且是免训练的,具有很强的灵活性和泛化能力。
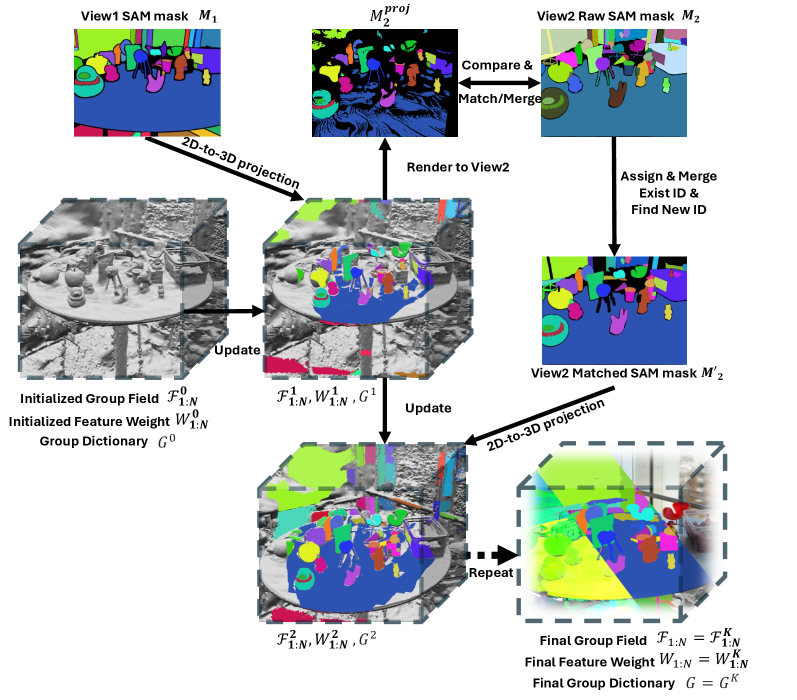
技术框架:OpenVoxel的整体框架包括以下几个主要阶段:1) 稀疏体素栅格化(SVR):从多视角图像中重建三维场景,得到稀疏体素表示。2) 体素分组:将相邻且具有相似视觉特征的体素进行分组,形成不同的对象。3) 场景描述:利用MLLMs为每个体素组生成文本描述,从而构建信息丰富的场景地图。4) 场景理解:基于生成的场景地图,可以进行开放词汇分割(OVS)或指代表达式分割(RES)等任务。
关键创新:OpenVoxel最重要的创新点在于其免训练的特性和对MLLMs的直接利用。与以往方法需要预训练文本编码器不同,OpenVoxel直接使用MLLMs进行文本到文本的搜索,避免了对特定词汇的依赖,并且无需训练。这种方法具有很强的灵活性和泛化能力,可以处理开放词汇的三维场景理解任务。
关键设计:在体素分组阶段,论文可能采用了基于几何邻近性和视觉特征相似性的聚类算法,例如K-means或DBSCAN。在场景描述阶段,论文可能使用了prompt engineering技术,设计合适的prompt来引导MLLMs生成准确且信息丰富的描述。具体的参数设置和损失函数细节未知,需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
OpenVoxel在指代表达式分割(RES)任务上表现出色,显著优于现有方法。具体的性能数据需要在论文中查找,但摘要中明确指出其在复杂RES任务中具有优越性。由于该方法是免训练的,因此在计算效率和部署成本方面也具有优势。
🎯 应用场景
OpenVoxel在机器人导航、自动驾驶、虚拟现实和增强现实等领域具有广泛的应用前景。它可以帮助机器人理解周围环境,从而实现更智能的导航和交互。在自动驾驶领域,它可以用于识别交通标志、行人和其他车辆,提高驾驶安全性。在虚拟现实和增强现实领域,它可以用于创建更逼真的三维场景,增强用户体验。
📄 摘要(原文)
We propose OpenVoxel, a training-free algorithm for grouping and captioning sparse voxels for the open-vocabulary 3D scene understanding tasks. Given the sparse voxel rasterization (SVR) model obtained from multi-view images of a 3D scene, our OpenVoxel is able to produce meaningful groups that describe different objects in the scene. Also, by leveraging powerful Vision Language Models (VLMs) and Multi-modal Large Language Models (MLLMs), our OpenVoxel successfully build an informative scene map by captioning each group, enabling further 3D scene understanding tasks such as open-vocabulary segmentation (OVS) or referring expression segmentation (RES). Unlike previous methods, our method is training-free and does not introduce embeddings from a CLIP/BERT text encoder. Instead, we directly proceed with text-to-text search using MLLMs. Through extensive experiments, our method demonstrates superior performance compared to recent studies, particularly in complex referring expression segmentation (RES) tasks. The code will be open.