Hot-Start from Pixels: Low-Resolution Visual Tokens for Chinese Language Modeling
作者: Shuyang Xiang, Hao Guan
分类: cs.CV, cs.AI
发布日期: 2026-01-14
备注: 15 pages, 5 figures, submitted to ACL 2026
💡 一句话要点
提出基于低分辨率像素的中文语言建模方法,有效利用汉字视觉信息。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 中文语言建模 视觉信息 低分辨率图像 字符表示 热启动 表意文字 汉字识别
📋 核心要点
- 现有中文语言模型主要依赖字符索引,忽略了汉字本身蕴含的视觉信息。
- 论文提出使用低分辨率汉字图像作为输入,探索视觉信息在语言建模中的潜力。
- 实验表明,即使是极低分辨率的图像也能达到与传统方法相当甚至更快的训练效果。
📝 摘要(中文)
大型语言模型通常将汉字表示为离散的、基于索引的 tokens,很大程度上忽略了其视觉形式。对于表意文字,视觉结构携带语义和语音信息,这可能有助于预测。本文研究了低分辨率视觉输入是否可以作为字符级建模的替代方案。解码器接收单个汉字的灰度图像,分辨率低至 8x8 像素,而不是 token IDs。 值得注意的是,这些输入实现了 39.2% 的准确率,与基于索引的基线 39.1% 相当。 这种低资源设置也表现出明显的“热启动”效应:在总训练量的 0.4% 时,准确率达到 12% 以上,而基于索引的模型则低于 6%。 总之,我们的结果表明,最小的视觉结构可以为中文语言建模提供强大而有效的信号,为字符表示提供了一种补充传统基于索引方法的替代视角。
🔬 方法详解
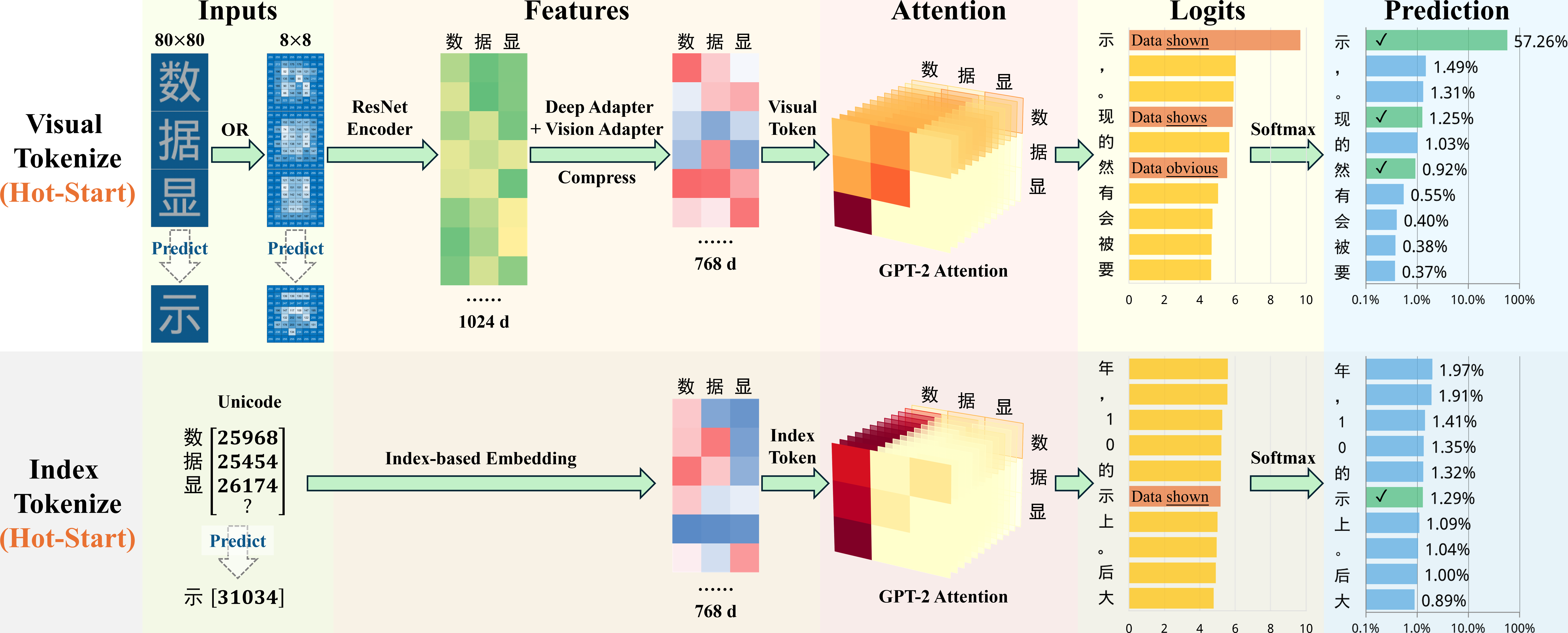
问题定义:现有中文语言模型通常将汉字视为独立的符号,通过索引进行编码,忽略了汉字作为表意文字所蕴含的视觉信息。这种方法无法有效利用汉字的字形结构所携带的语义和语音信息,可能限制模型的学习效率和泛化能力。
核心思路:论文的核心思路是利用汉字的视觉信息作为语言建模的输入。具体来说,将汉字图像作为模型的输入,而不是传统的字符索引。通过让模型直接从像素中学习汉字的表示,从而挖掘汉字字形结构中的语义和语音信息。这种方法旨在提高模型的学习效率和鲁棒性。
技术框架:该方法使用一个解码器,该解码器接收单个汉字的灰度图像作为输入,而不是token IDs。这些图像的分辨率可以低至8x8像素。解码器的具体结构未知,但可以推测其类似于图像处理中的卷积神经网络(CNN)或Transformer结构,用于提取图像特征并进行语言建模。
关键创新:该方法最重要的创新点在于将汉字的视觉信息直接融入到语言建模过程中。与传统的基于索引的方法不同,该方法不需要预先定义字符集,而是直接从像素中学习汉字的表示。这种方法可以更好地利用汉字的字形结构,并且可能具有更好的泛化能力。此外,该方法在低资源场景下表现出显著的“热启动”效应,表明视觉信息可以加速模型的学习过程。
关键设计:论文的关键设计在于使用低分辨率的汉字图像作为输入。实验表明,即使是 8x8 像素的图像也能提供足够的信息进行语言建模。这种设计可以降低计算成本,并且可能有助于模型学习到更加鲁棒的特征。论文中没有明确提及损失函数和网络结构的具体细节,这些是未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于低分辨率汉字图像的语言模型能够达到与基于索引的基线模型相当的准确率(39.2% vs 39.1%)。更重要的是,该方法在低资源设置下表现出显著的“热启动”效应,在训练初期就能快速达到较高的准确率(0.4%训练量时达到12%以上,而基线模型低于6%)。
🎯 应用场景
该研究成果可应用于低资源语言建模、手写汉字识别、OCR纠错等领域。通过利用汉字的视觉信息,可以提高模型在数据稀缺情况下的性能,并增强模型对噪声和变形的鲁棒性。未来,该方法有望应用于更复杂的中文自然语言处理任务,例如机器翻译和文本生成。
📄 摘要(原文)
Large language models typically represent Chinese characters as discrete index-based tokens, largely ignoring their visual form. For logographic scripts, visual structure carries semantic and phonetic information, which may aid prediction. We investigate whether low-resolution visual inputs can serve as an alternative for character-level modeling. Instead of token IDs, our decoder receives grayscale images of individual characters, with resolutions as low as $8 \times 8$ pixels. Remarkably, these inputs achieve 39.2\% accuracy, comparable to the index-based baseline of 39.1\%. Such low-resource settings also exhibit a pronounced \emph{hot-start} effect: by 0.4\% of total training, accuracy reaches above 12\%, while index-based models lag at below 6\%. Overall, our results demonstrate that minimal visual structure can provide a robust and efficient signal for Chinese language modeling, offering an alternative perspective on character representation that complements traditional index-based approaches.