Video-MSR: Benchmarking Multi-hop Spatial Reasoning Capabilities of MLLMs
作者: Rui Zhu, Xin Shen, Shuchen Wu, Chenxi Miao, Xin Yu, Yang Li, Weikang Li, Deguo Xia, Jizhou Huang
分类: cs.CV
发布日期: 2026-01-14
🔗 代码/项目: GITHUB
💡 一句话要点
Video-MSR:首个动态视频多步空间推理能力评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 空间推理 视频理解 基准数据集 指令微调
📋 核心要点
- 现有MLLM基准侧重单步感知任务,缺乏对复杂视觉空间逻辑链的评估,无法有效衡量模型的多步空间推理能力。
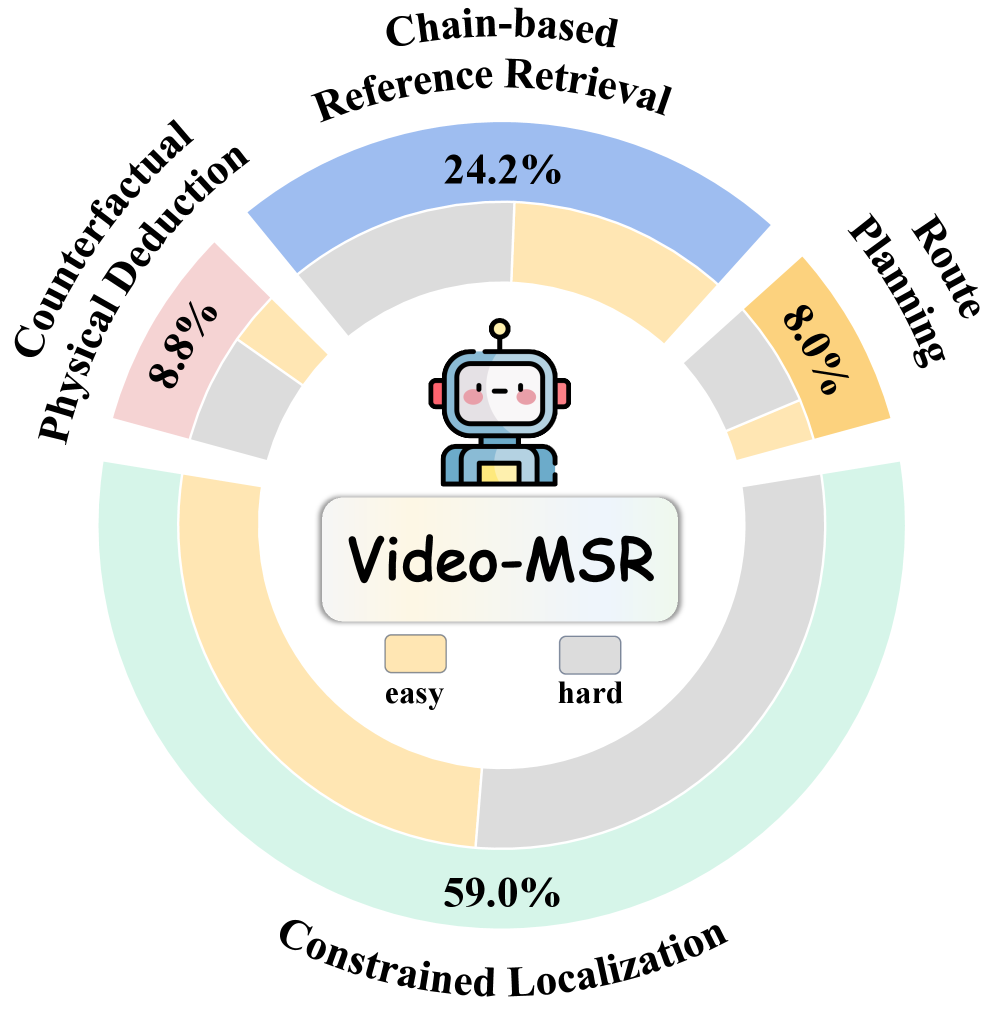
- 提出Video-MSR基准,包含约束定位、参考检索、路线规划和反事实物理推演四个任务,系统评估MLLM在动态视频中的多步空间推理能力。
- 实验表明现有MLLM在多步空间推理任务中存在空间迷失和幻觉问题,通过MSR-9K数据集微调Qwen-VL模型,在Video-MSR上取得显著提升。
📝 摘要(中文)
空间推理已成为多模态大型语言模型(MLLM)的关键能力,受到越来越多的关注和快速发展。然而,现有的基准主要集中于单步感知到判断的任务,对于需要复杂视觉空间逻辑链的场景的探索明显不足。为了弥补这一差距,我们推出了Video-MSR,这是第一个专门用于评估动态视频场景中多步空间推理(MSR)的基准。Video-MSR通过四个不同的任务系统地探测MSR能力:约束定位、基于链的参考检索、路线规划和反事实物理推演。我们的基准包含3,052个高质量视频实例和4,993个问答对,通过可扩展的、视觉接地的流程构建,该流程结合了先进的模型生成和严格的人工验证。通过对20个最先进的MLLM的全面评估,我们发现了显著的局限性,揭示了虽然模型在表面感知方面表现出熟练程度,但在MSR任务中表现出明显的性能下降,在多步推导过程中经常遭受空间迷失和幻觉。为了减轻这些缺点并使模型具有更强的MSR能力,我们进一步整理了MSR-9K,这是一个专门的指令调优数据集,并对Qwen-VL进行了微调,在Video-MSR上实现了+7.82%的绝对改进。我们的结果强调了多跳空间指令数据的有效性,并将Video-MSR确立为未来研究的重要基础。代码和数据将在https://github.com/ruiz-nju/Video-MSR上提供。
🔬 方法详解
问题定义:现有MLLM基准主要评估单步感知到判断的任务,无法有效评估模型在动态视频场景下的多步空间推理能力。现有方法在处理复杂视觉空间逻辑链时,容易出现空间迷失和幻觉问题,导致推理性能下降。
核心思路:论文的核心思路是构建一个专门用于评估动态视频场景中多步空间推理(MSR)能力的基准数据集Video-MSR。通过设计四个不同的任务,系统地探测MLLM在复杂场景下的空间推理能力,并利用该基准发现现有模型的不足之处,进而通过指令微调提升模型性能。
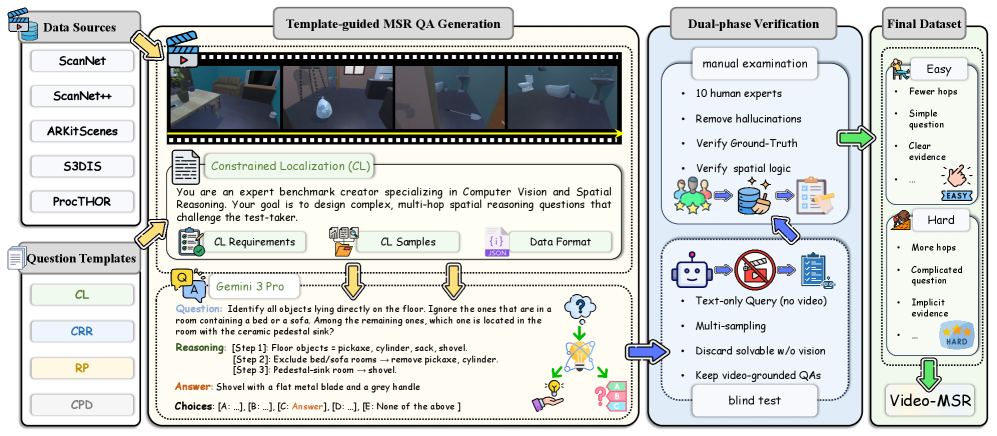
技术框架:Video-MSR的构建流程包含以下几个主要阶段:1) 视频数据生成:利用先进的模型生成视频数据,并结合人工验证保证数据质量。2) 任务设计:设计四个不同的MSR任务,包括约束定位、基于链的参考检索、路线规划和反事实物理推演。3) 数据集构建:为每个任务生成相应的问答对,构建高质量的Video-MSR数据集。4) 模型评估:利用Video-MSR评估现有MLLM的性能,并分析其在不同任务上的表现。5) 指令微调:构建MSR-9K数据集,并利用该数据集对Qwen-VL模型进行微调,提升其MSR能力。
关键创新:该论文的关键创新在于:1) 提出了首个专门用于评估动态视频场景中多步空间推理能力的基准数据集Video-MSR。2) 设计了四个不同的MSR任务,能够系统地探测MLLM在复杂场景下的空间推理能力。3) 构建了MSR-9K数据集,并利用该数据集对Qwen-VL模型进行微调,有效提升了其MSR能力。
关键设计:Video-MSR数据集包含3,052个高质量视频实例和4,993个问答对。MSR-9K数据集是一个专门的指令调优数据集,用于提升模型的MSR能力。论文使用Qwen-VL模型作为基础模型,并利用MSR-9K数据集对其进行微调。具体的参数设置和损失函数等技术细节在论文中未详细描述。
🖼️ 关键图片

📊 实验亮点
通过对20个最先进的MLLM进行评估,发现它们在多步空间推理任务中存在显著的性能下降。利用MSR-9K数据集对Qwen-VL模型进行微调后,在Video-MSR基准上取得了+7.82%的绝对改进,验证了多跳空间指令数据的有效性,并证明了该方法在提升模型MSR能力方面的潜力。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、视频监控、智能家居等领域。通过提升MLLM的多步空间推理能力,可以使机器人在复杂动态环境中更好地理解和推理,从而实现更智能、更可靠的决策和行动。该研究为未来开发更强大的多模态智能系统奠定了基础。
📄 摘要(原文)
Spatial reasoning has emerged as a critical capability for Multimodal Large Language Models (MLLMs), drawing increasing attention and rapid advancement. However, existing benchmarks primarily focus on single-step perception-to-judgment tasks, leaving scenarios requiring complex visual-spatial logical chains significantly underexplored. To bridge this gap, we introduce Video-MSR, the first benchmark specifically designed to evaluate Multi-hop Spatial Reasoning (MSR) in dynamic video scenarios. Video-MSR systematically probes MSR capabilities through four distinct tasks: Constrained Localization, Chain-based Reference Retrieval, Route Planning, and Counterfactual Physical Deduction. Our benchmark comprises 3,052 high-quality video instances with 4,993 question-answer pairs, constructed via a scalable, visually-grounded pipeline combining advanced model generation with rigorous human verification. Through a comprehensive evaluation of 20 state-of-the-art MLLMs, we uncover significant limitations, revealing that while models demonstrate proficiency in surface-level perception, they exhibit distinct performance drops in MSR tasks, frequently suffering from spatial disorientation and hallucination during multi-step deductions. To mitigate these shortcomings and empower models with stronger MSR capabilities, we further curate MSR-9K, a specialized instruction-tuning dataset, and fine-tune Qwen-VL, achieving a +7.82% absolute improvement on Video-MSR. Our results underscore the efficacy of multi-hop spatial instruction data and establish Video-MSR as a vital foundation for future research. The code and data will be available at https://github.com/ruiz-nju/Video-MSR.