Beyond the final layer: Attentive multilayer fusion for vision transformers
作者: Laure Ciernik, Marco Morik, Lukas Thede, Luca Eyring, Shinichi Nakajima, Zeynep Akata, Lukas Muttenthaler
分类: cs.CV
发布日期: 2026-01-14
💡 一句话要点
提出基于注意力机制的多层融合方法,提升Vision Transformer线性探测性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Vision Transformer 线性探测 注意力机制 多层融合 迁移学习
📋 核心要点
- 线性探测仅利用最后一层表示,忽略了网络中间层可能包含的任务相关信息,限制了模型性能。
- 提出一种注意力探测机制,动态融合Vision Transformer所有层的表示,自适应地选择对特定任务最相关的层。
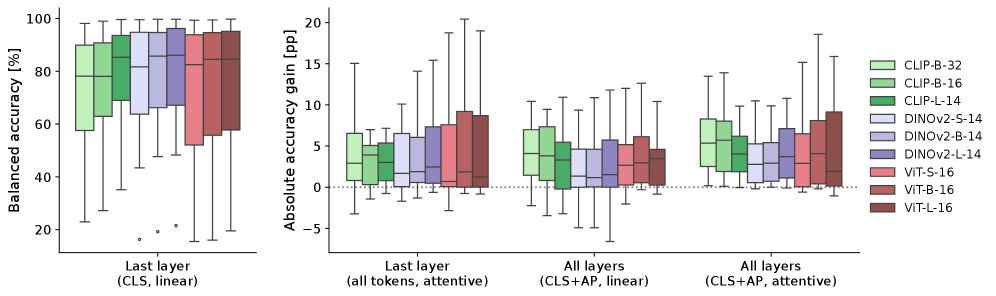
- 实验表明,该方法在多个数据集和预训练模型上显著优于标准线性探测,尤其在与预训练领域不同的任务上。
📝 摘要(中文)
随着大规模基础模型的兴起,如何高效地将其适配到下游任务仍然是一个核心挑战。线性探测是一种计算高效的方法,它冻结骨干网络并训练一个轻量级的头部,但通常仅限于最后一层的表示。本文表明,任务相关的信息分布在网络层次结构中,而不是仅仅编码在任何最后一层中。为了利用这种信息分布,我们应用了一种注意力探测机制,该机制动态地融合来自Vision Transformer所有层的表示。该机制学习识别目标任务最相关的层,并将低级结构线索与高级语义抽象相结合。在20个不同的数据集和多个预训练的基础模型上,我们的方法比标准线性探测实现了持续的、显著的收益。注意力热图进一步表明,与预训练领域不同的任务从中间表示中获益最多。总的来说,我们的发现强调了中间层信息的价值,并展示了一种基于原则的、任务感知的的方法,用于释放它们在基于探测的适配中的潜力。
🔬 方法详解
问题定义:现有线性探测方法在迁移学习中存在局限性,它们通常只利用预训练Vision Transformer的最后一层特征进行下游任务的训练,忽略了网络中间层可能包含的、对特定任务更具价值的信息。这种做法限制了模型性能,无法充分利用预训练模型的潜力。
核心思路:论文的核心思想是,任务相关的信息并非只存在于网络的最后一层,而是分布在整个网络层次结构中。因此,应该设计一种机制,能够动态地、自适应地融合来自不同层的特征表示,从而更好地适应下游任务。通过学习不同层特征的重要性权重,模型可以专注于对当前任务最有用的信息。
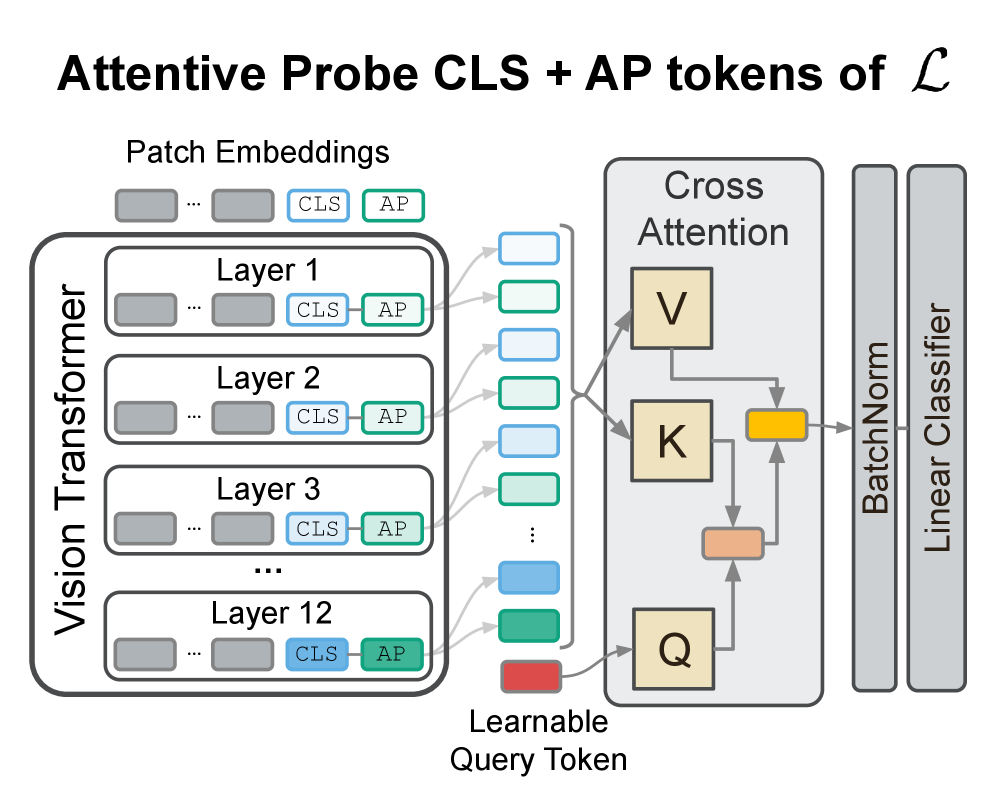
技术框架:该方法的核心是一个注意力融合模块,它接收来自Vision Transformer所有层的特征表示作为输入。该模块首先对每一层的特征进行线性变换,然后使用一个注意力机制来学习每一层的权重。注意力权重反映了每一层特征对于当前任务的重要性。最后,将所有层的特征按照学习到的权重进行加权融合,得到最终的特征表示,用于下游任务的训练。
关键创新:该方法最重要的创新点在于提出了一个任务感知的注意力融合机制,能够动态地选择和融合来自Vision Transformer不同层的特征。与传统的线性探测方法相比,该方法能够更好地利用预训练模型的中间层信息,从而提高模型在下游任务上的性能。这种方法避免了手动选择特定层或简单地平均所有层特征的策略,而是通过学习的方式来确定最佳的特征融合方式。
关键设计:注意力机制的具体实现采用了一个小型神经网络,该网络接收每一层的特征作为输入,并输出一个标量权重。该网络的参数通过反向传播进行训练,以最小化下游任务的损失函数。损失函数通常是交叉熵损失或均方误差损失,具体取决于下游任务的类型。此外,为了防止过拟合,可以使用dropout或权重衰减等正则化技术。
🖼️ 关键图片
📊 实验亮点
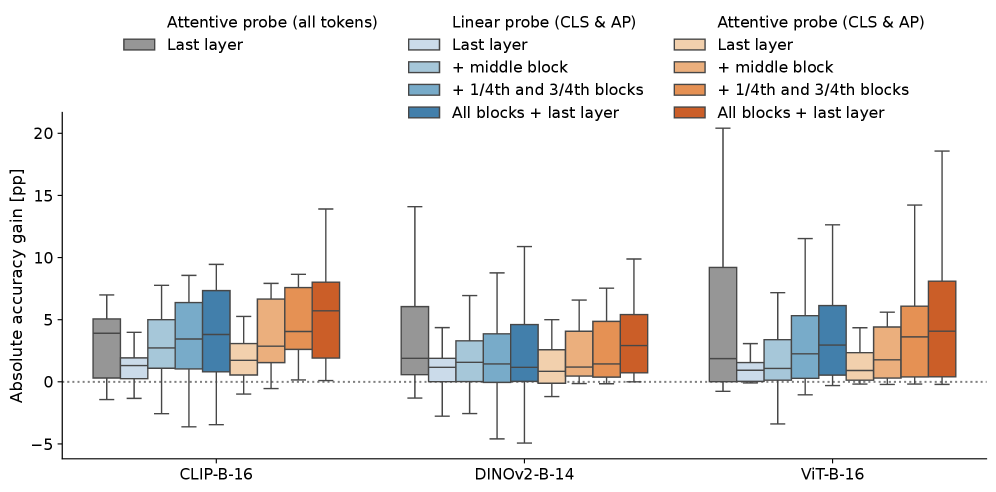
实验结果表明,该方法在20个不同的数据集上均取得了显著的性能提升。例如,在某些数据集上,该方法比标准线性探测的性能提升超过5%。注意力热图可视化结果显示,对于与预训练领域不同的任务,中间层的特征具有更高的权重,这验证了该方法能够有效地利用中间层信息的假设。此外,该方法在不同的预训练模型上都表现出良好的泛化能力。
🎯 应用场景
该研究成果可广泛应用于各种计算机视觉任务,如图像分类、目标检测、语义分割等。通过自适应地融合Vision Transformer的不同层特征,可以提升模型在各种下游任务上的性能,尤其是在数据量有限或任务与预训练领域存在差异的情况下。该方法具有很高的实际应用价值,可以帮助研究人员和工程师更好地利用预训练模型,降低模型训练成本,并提高模型泛化能力。
📄 摘要(原文)
With the rise of large-scale foundation models, efficiently adapting them to downstream tasks remains a central challenge. Linear probing, which freezes the backbone and trains a lightweight head, is computationally efficient but often restricted to last-layer representations. We show that task-relevant information is distributed across the network hierarchy rather than solely encoded in any of the last layers. To leverage this distribution of information, we apply an attentive probing mechanism that dynamically fuses representations from all layers of a Vision Transformer. This mechanism learns to identify the most relevant layers for a target task and combines low-level structural cues with high-level semantic abstractions. Across 20 diverse datasets and multiple pretrained foundation models, our method achieves consistent, substantial gains over standard linear probes. Attention heatmaps further reveal that tasks different from the pre-training domain benefit most from intermediate representations. Overall, our findings underscore the value of intermediate layer information and demonstrate a principled, task aware approach for unlocking their potential in probing-based adaptation.