CLIDD: Cross-Layer Independent Deformable Description for Efficient and Discriminative Local Feature Representation
作者: Haodi Yao, Fenghua He, Ning Hao, Yao Su
分类: cs.CV
发布日期: 2026-01-14
💡 一句话要点
提出CLIDD,通过跨层独立形变描述实现高效且具区分性的局部特征表示,适用于机器人导航等空间智能任务。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 局部特征描述 跨层采样 形变描述 边缘计算 机器人导航 增强现实 度量学习
📋 核心要点
- 现有局部特征描述子在区分性和计算效率上难以兼顾,限制了其在资源受限设备上的应用。
- CLIDD通过跨层独立采样和可学习偏移,在保证区分性的同时,避免了密集计算,提升了效率。
- 实验表明,CLIDD在精度和效率上均优于现有方法,超紧凑版本模型大小仅为SuperPoint的0.3%。
📝 摘要(中文)
本文提出了一种名为跨层独立形变描述(CLIDD)的方法,旨在为空间智能任务(如机器人导航和增强现实)提供鲁棒的局部特征表示。CLIDD通过直接从独立的特征层级中采样,实现了卓越的区分性。该方法利用可学习的偏移量来捕获跨尺度的精细结构细节,同时避免了统一密集表示的计算负担。为了确保实时性能,本文实现了一种硬件感知的内核融合策略,以最大化推理吞吐量。此外,还开发了一个可扩展的框架,该框架将轻量级架构与利用度量学习和知识蒸馏的训练协议相结合。该方案生成了针对不同部署约束优化的各种模型变体。大量评估表明,该方法同时实现了卓越的匹配精度和出色的计算效率。超紧凑型变体在仅使用0.004M参数的情况下,匹配了SuperPoint的精度,模型尺寸减少了99.7%。高性能配置优于所有当前最先进的方法,包括基于高容量DINOv2的框架,同时在边缘设备上超过200 FPS。这些结果表明,CLIDD以最小的计算开销提供高精度的局部特征匹配,为实时空间智能任务提供了一个鲁棒且可扩展的解决方案。
🔬 方法详解
问题定义:论文旨在解决局部特征描述子在区分性和计算效率之间的trade-off问题。现有的局部特征描述子要么计算量大,难以在边缘设备上实时运行,要么区分性不足,导致匹配精度不高,无法满足机器人导航等空间智能任务的需求。
核心思路:论文的核心思路是利用跨层独立形变描述(Cross-Layer Independent Deformable Description, CLIDD)。通过从不同特征层级独立采样,并使用可学习的偏移量来捕捉细粒度的结构信息,从而在保证区分性的同时,避免了对所有特征进行密集计算,显著降低了计算复杂度。
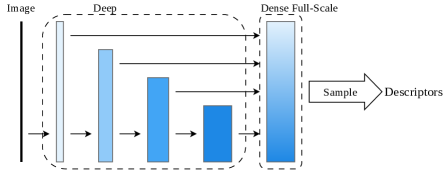
技术框架:CLIDD的整体框架包含特征提取、跨层独立采样、形变描述和特征匹配等几个主要阶段。首先,使用轻量级的卷积神经网络提取多层级的特征图。然后,从这些独立的特征层级中进行采样,并学习偏移量来捕捉局部形变。接着,利用采样得到的特征构建局部描述子。最后,使用相似度度量方法进行特征匹配。此外,论文还提出了一种硬件感知的内核融合策略,以进一步提升推理速度。
关键创新:CLIDD的关键创新在于其跨层独立采样和形变描述的思想。与传统的局部特征描述子不同,CLIDD不是基于单一尺度的特征进行描述,而是利用多个尺度的特征信息,从而能够更好地应对尺度变化和视角变化。同时,通过可学习的偏移量,CLIDD能够捕捉局部形变,增强了描述子的鲁棒性。
关键设计:CLIDD的关键设计包括:1) 使用轻量级的卷积神经网络作为特征提取器,例如MobileNet等,以降低计算复杂度;2) 设计合适的采样策略,例如随机采样或基于梯度的采样,以保证采样的有效性;3) 使用度量学习损失函数,例如Triplet Loss或Contrastive Loss,来训练网络,使得相似的特征更接近,不相似的特征更远离;4) 采用知识蒸馏的方法,将大型模型的知识迁移到小型模型中,以提升小型模型的性能。
🖼️ 关键图片
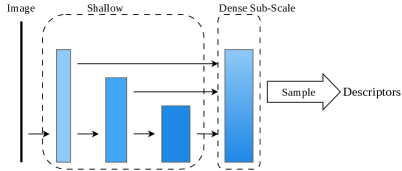
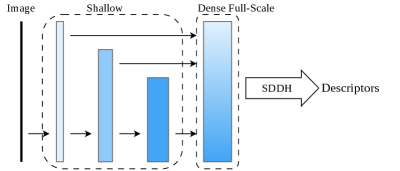
📊 实验亮点
CLIDD在多个数据集上取得了显著的性能提升。超紧凑型变体在参数量仅为0.004M的情况下,达到了与SuperPoint相当的精度,模型大小减少了99.7%。高性能配置在精度上优于所有当前最先进的方法,包括基于DINOv2的框架,同时在边缘设备上实现了超过200 FPS的推理速度,证明了其在精度和效率上的优越性。
🎯 应用场景
CLIDD具有广泛的应用前景,尤其是在机器人导航、增强现实、三维重建、视觉定位等空间智能任务中。其高效的计算性能使其能够部署在资源受限的边缘设备上,实现实时的特征匹配和场景理解。此外,CLIDD还可以应用于图像检索、目标识别等领域,提升相关任务的性能。
📄 摘要(原文)
Robust local feature representations are essential for spatial intelligence tasks such as robot navigation and augmented reality. Establishing reliable correspondences requires descriptors that provide both high discriminative power and computational efficiency. To address this, we introduce Cross-Layer Independent Deformable Description (CLIDD), a method that achieves superior distinctiveness by sampling directly from independent feature hierarchies. This approach utilizes learnable offsets to capture fine-grained structural details across scales while bypassing the computational burden of unified dense representations. To ensure real-time performance, we implement a hardware-aware kernel fusion strategy that maximizes inference throughput. Furthermore, we develop a scalable framework that integrates lightweight architectures with a training protocol leveraging both metric learning and knowledge distillation. This scheme generates a wide spectrum of model variants optimized for diverse deployment constraints. Extensive evaluations demonstrate that our approach achieves superior matching accuracy and exceptional computational efficiency simultaneously. Specifically, the ultra-compact variant matches the precision of SuperPoint while utilizing only 0.004M parameters, achieving a 99.7% reduction in model size. Furthermore, our high-performance configuration outperforms all current state-of-the-art methods, including high-capacity DINOv2-based frameworks, while exceeding 200 FPS on edge devices. These results demonstrate that CLIDD delivers high-precision local feature matching with minimal computational overhead, providing a robust and scalable solution for real-time spatial intelligence tasks.