SpikeVAEDiff: Neural Spike-based Natural Visual Scene Reconstruction via VD-VAE and Versatile Diffusion
作者: Jialu Li, Taiyan Zhou
分类: cs.CV, cs.AI
发布日期: 2026-01-14
备注: Preprint
💡 一句话要点
SpikeVAEDiff:结合VD-VAE和扩散模型,从神经元脉冲数据重建自然视觉场景
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 神经元脉冲 视觉场景重建 VD-VAE 扩散模型 脑机接口 神经科学 CLIP特征
📋 核心要点
- 从神经活动重建自然视觉场景是神经科学和计算机视觉的关键挑战,现有方法在重建质量和分辨率上存在不足。
- SpikeVAEDiff结合VDVAE和Versatile Diffusion,首先使用VDVAE生成低分辨率重建,然后利用扩散模型进行图像细化。
- 实验表明,该方法在Allen Visual Coding-Neuropixels数据集上有效,VISI区域对重建质量贡献最大,且优于fMRI方法。
📝 摘要(中文)
本文提出SpikeVAEDiff,一种新颖的两阶段框架,旨在从神经元脉冲数据中生成高分辨率且语义上有意义的图像重建,从而解决神经科学和计算机视觉中的关键挑战:从神经活动重建自然视觉场景。第一阶段,VDVAE(Very Deep Variational Autoencoder)通过将神经元脉冲信号映射到潜在表示,产生低分辨率的初步重建。第二阶段,回归模型将神经元脉冲信号映射到CLIP-Vision和CLIP-Text特征,使Versatile Diffusion模型能够通过图像到图像的生成来细化图像。我们在Allen Visual Coding-Neuropixels数据集上评估了该方法,并分析了不同的脑区。结果表明,VISI区域表现出最显著的激活,并在重建质量中起关键作用。我们展示了成功和不成功的重建案例,反映了解码神经活动的挑战。与基于fMRI的方法相比,脉冲数据提供了卓越的时间和空间分辨率。我们进一步验证了VDVAE模型的有效性,并进行了消融研究,表明来自特定脑区的数据显著提高了重建性能。
🔬 方法详解
问题定义:论文旨在解决从神经元脉冲数据重建自然视觉场景的问题。现有方法,特别是基于fMRI的方法,在时间和空间分辨率上存在局限性,难以捕捉神经活动的精细动态,导致重建图像的质量和语义信息不足。
核心思路:论文的核心思路是将神经元脉冲数据解码为图像重建问题,并利用深度生成模型的能力。通过结合VDVAE和Versatile Diffusion,实现从低分辨率初步重建到高分辨率、语义丰富图像的转换。VDVAE负责初步的特征提取和降维,而Versatile Diffusion则负责图像的细节生成和语义一致性。
技术框架:SpikeVAEDiff框架包含两个主要阶段:1) VDVAE阶段:神经元脉冲信号输入VDVAE,生成低分辨率的图像重建。VDVAE学习神经元活动与图像潜在表示之间的映射关系。2) Versatile Diffusion阶段:首先,回归模型将神经元脉冲信号映射到CLIP-Vision和CLIP-Text特征。然后,Versatile Diffusion模型利用这些CLIP特征作为条件,对VDVAE生成的低分辨率图像进行细化,生成高分辨率的重建图像。
关键创新:该方法的关键创新在于结合了VDVAE和Versatile Diffusion,利用VDVAE进行有效的特征提取和降维,同时利用Versatile Diffusion强大的图像生成能力。此外,使用CLIP特征作为扩散模型的条件,能够更好地控制生成图像的语义内容。与直接从神经元数据生成高分辨率图像相比,两阶段方法更易于训练和优化。
关键设计:VDVAE采用深度卷积结构,学习神经元脉冲信号的潜在表示。回归模型可以是简单的线性回归或更复杂的神经网络。Versatile Diffusion模型使用CLIP-Vision和CLIP-Text特征作为条件输入,指导图像生成过程。损失函数包括VDVAE的重构损失和KL散度损失,以及Versatile Diffusion的扩散模型损失。具体参数设置(如网络层数、滤波器大小、学习率等)未知,可能需要根据数据集进行调整。
🖼️ 关键图片
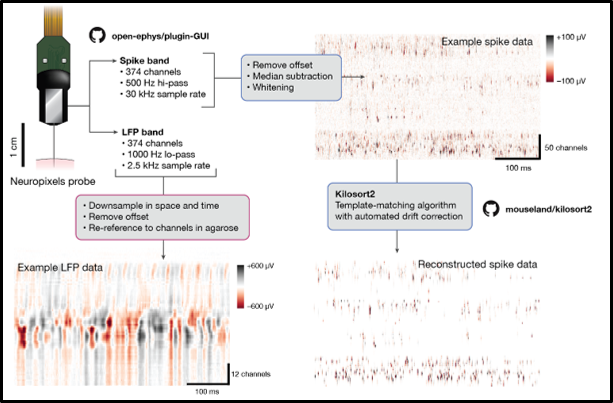
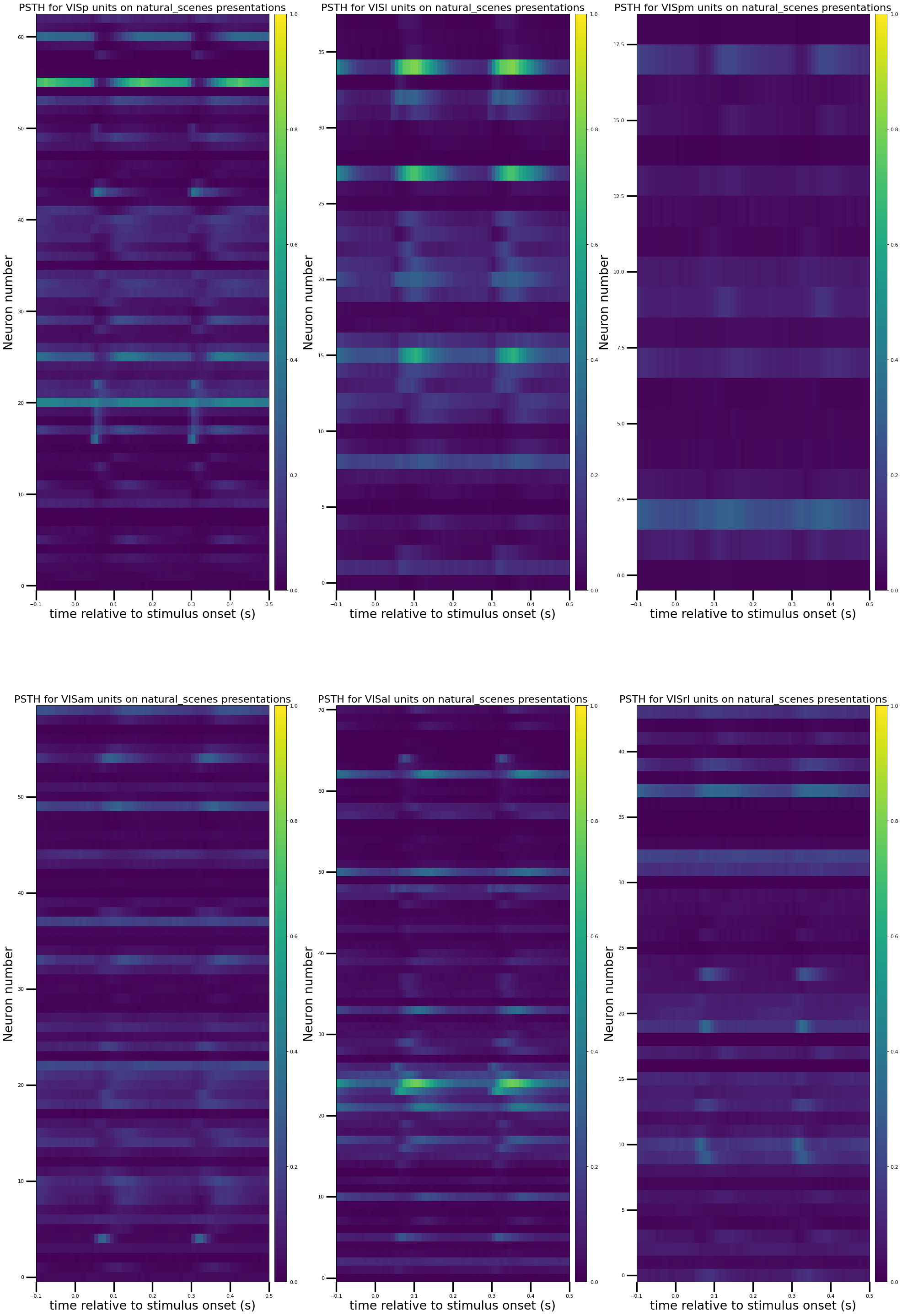

📊 实验亮点
实验结果表明,SpikeVAEDiff在Allen Visual Coding-Neuropixels数据集上取得了良好的重建效果,尤其是在VISI区域。与基于fMRI的方法相比,该方法能够利用神经元脉冲数据提供更高的时间和空间分辨率。消融研究表明,特定脑区的数据对重建性能有显著提升,验证了模型的有效性。
🎯 应用场景
该研究成果可应用于神经科学领域,帮助研究人员理解大脑如何编码视觉信息,并为开发脑机接口提供技术支持。此外,该技术在医学影像分析、图像修复和生成等领域也具有潜在应用价值,例如,可以用于重建受损的医学图像或生成具有特定语义特征的图像。
📄 摘要(原文)
Reconstructing natural visual scenes from neural activity is a key challenge in neuroscience and computer vision. We present SpikeVAEDiff, a novel two-stage framework that combines a Very Deep Variational Autoencoder (VDVAE) and the Versatile Diffusion model to generate high-resolution and semantically meaningful image reconstructions from neural spike data. In the first stage, VDVAE produces low-resolution preliminary reconstructions by mapping neural spike signals to latent representations. In the second stage, regression models map neural spike signals to CLIP-Vision and CLIP-Text features, enabling Versatile Diffusion to refine the images via image-to-image generation. We evaluate our approach on the Allen Visual Coding-Neuropixels dataset and analyze different brain regions. Our results show that the VISI region exhibits the most prominent activation and plays a key role in reconstruction quality. We present both successful and unsuccessful reconstruction examples, reflecting the challenges of decoding neural activity. Compared with fMRI-based approaches, spike data provides superior temporal and spatial resolution. We further validate the effectiveness of the VDVAE model and conduct ablation studies demonstrating that data from specific brain regions significantly enhances reconstruction performance.