Affostruction: 3D Affordance Grounding with Generative Reconstruction
作者: Chunghyun Park, Seunghyeon Lee, Minsu Cho
分类: cs.CV
发布日期: 2026-01-14
💡 一句话要点
Affostruction:提出基于生成式重建的3D可供性基准方法,解决可见表面局限性问题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D重建 可供性基准测试 生成式模型 主动视图选择 机器人操作
📋 核心要点
- 现有可供性基准测试方法仅限于可见表面,无法处理遮挡或未观测区域,限制了其在复杂场景中的应用。
- Affostruction通过生成式重建补全物体几何形状,并在完整形状上进行可供性预测,从而克服了可见性限制。
- 实验结果表明,Affostruction在可供性基准测试和3D重建方面均取得了显著提升,验证了其有效性。
📝 摘要(中文)
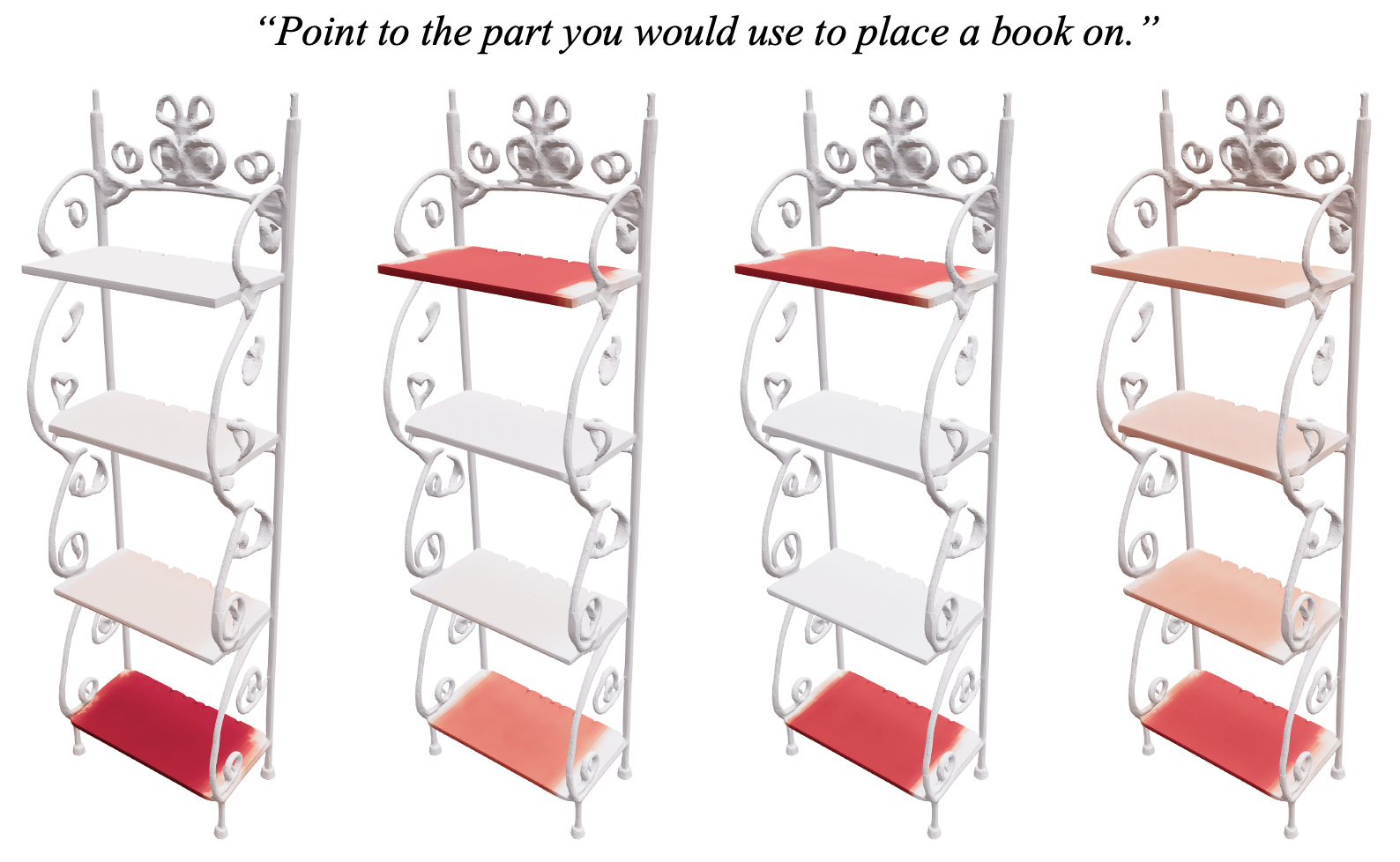
本文研究了从物体的RGBD图像中进行可供性基准测试的问题,旨在定位与描述物体动作的文本查询相对应的表面区域。现有方法仅在可见表面上预测可供性区域,本文提出了Affostruction,一个生成式框架,可以从部分观测中重建完整的几何形状,并在包括未观测区域的完整形状上进行可供性基准测试。本文做出了三个核心贡献:通过稀疏体素融合进行生成式多视图重建,在保持恒定token复杂度的同时推断未见几何形状;基于流的可供性基准测试,捕捉可供性分布中固有的模糊性;以及可供性驱动的主动视图选择,利用预测的可供性进行智能视点采样。Affostruction在可供性基准测试中实现了19.1的aIoU(提升40.4%),在3D重建中实现了32.67的IoU(提升67.7%),从而能够在完整形状上进行准确的可供性预测。
🔬 方法详解
问题定义:现有方法在RGBD图像的可供性基准测试中,主要依赖于可见表面信息,忽略了被遮挡或未观测到的区域。这导致预测的可供性区域不完整,影响了下游任务的性能。因此,需要一种方法能够从部分观测中推断出完整的3D几何形状,并在完整形状上进行可供性预测。
核心思路:Affostruction的核心思路是利用生成式模型从部分观测重建完整的3D几何形状,然后在此基础上进行可供性预测。通过重建完整形状,可以克服仅依赖可见表面的局限性,提高可供性预测的准确性和完整性。此外,该方法还利用流模型来捕捉可供性分布的模糊性,并采用主动视图选择策略来优化视点采样。
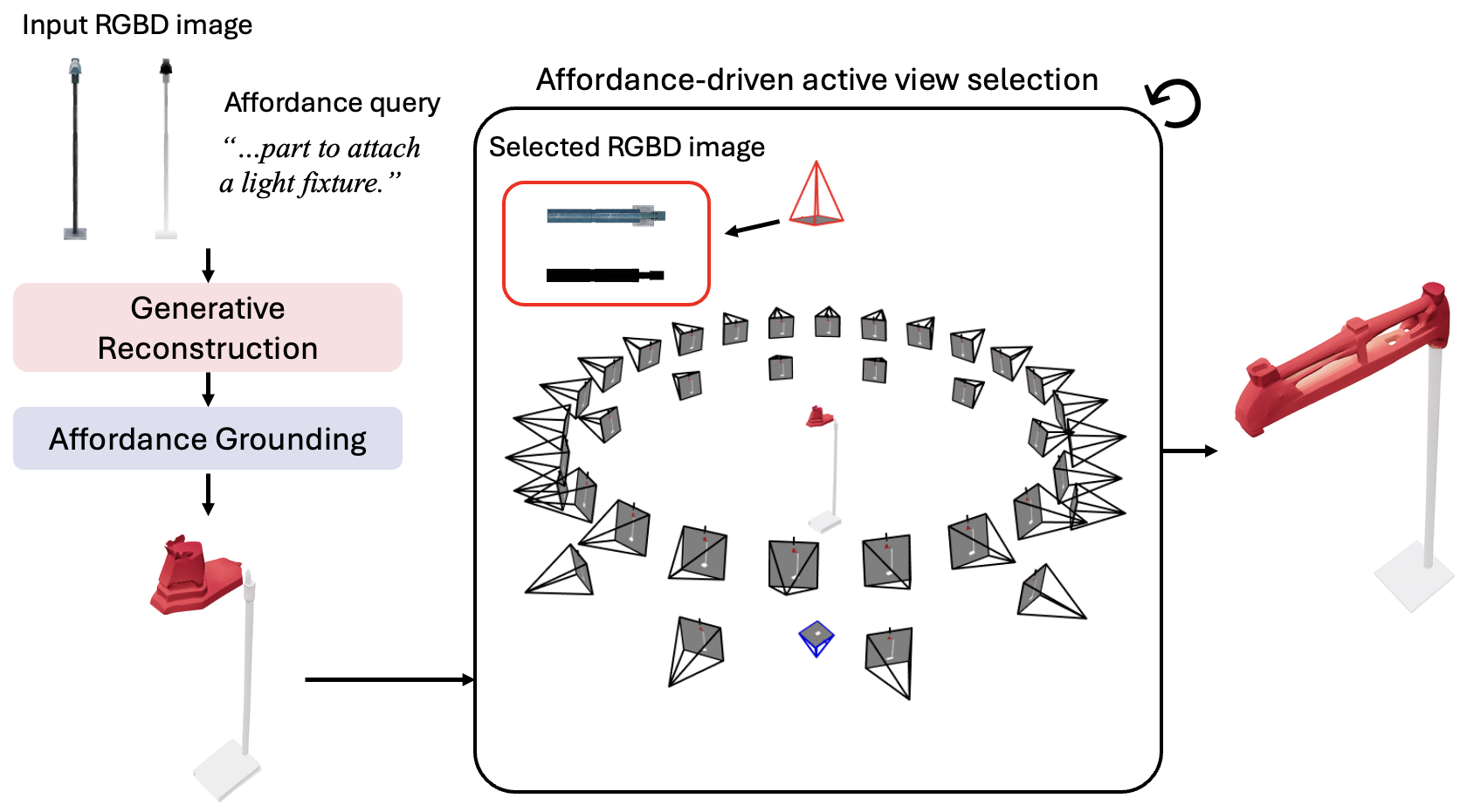
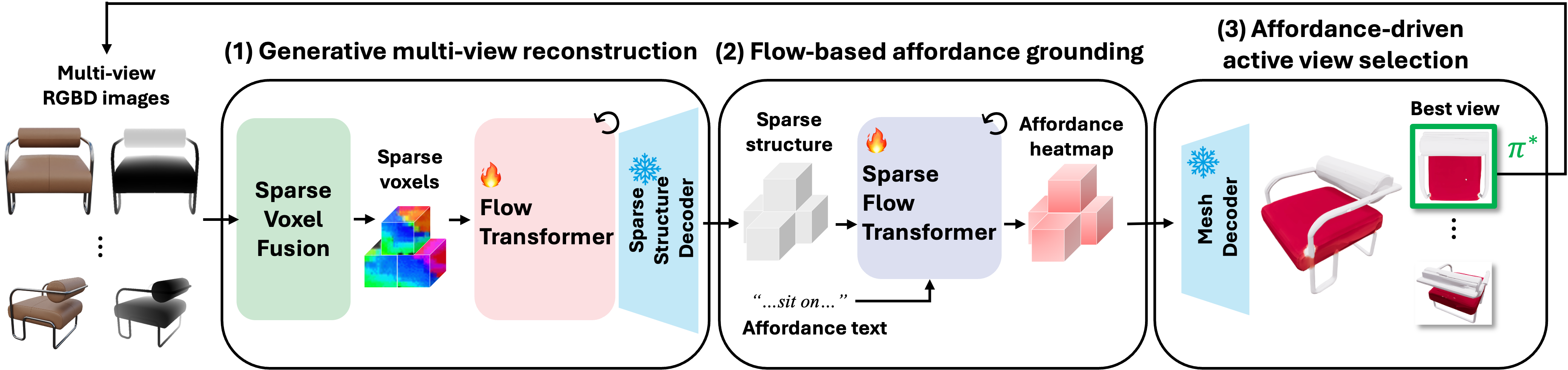
技术框架:Affostruction框架包含三个主要模块:1) 生成式多视图重建模块,通过稀疏体素融合从多个视角的RGBD图像重建完整的3D几何形状;2) 基于流的可供性基准测试模块,利用流模型预测完整形状上的可供性分布;3) 可供性驱动的主动视图选择模块,根据预测的可供性信息选择下一个最佳视点,以进一步提高重建和可供性预测的准确性。
关键创新:Affostruction的关键创新在于将生成式重建与可供性基准测试相结合,从而能够在完整形状上进行可供性预测。此外,该方法还提出了基于流的可供性基准测试方法,能够捕捉可供性分布的模糊性。主动视图选择策略进一步提高了重建和可供性预测的效率和准确性。
关键设计:生成式多视图重建模块采用稀疏体素融合,以保持恒定的token复杂度。基于流的可供性基准测试模块使用条件神经过程(CNP)来建模可供性分布。主动视图选择模块使用预测的可供性信息来选择下一个最佳视点,目标是最大化信息增益。
🖼️ 关键图片
📊 实验亮点
Affostruction在可供性基准测试中取得了显著的性能提升,aIoU达到19.1,相比现有方法提升了40.4%。在3D重建方面,IoU达到32.67,提升了67.7%。这些结果表明,Affostruction能够有效地重建完整的3D几何形状,并在完整形状上进行准确的可供性预测。
🎯 应用场景
该研究成果可应用于机器人操作、人机交互、虚拟现实等领域。例如,机器人可以利用该方法理解物体的可供性,从而更好地执行操作任务。在人机交互中,该方法可以帮助系统理解用户的意图,提供更自然和智能的交互体验。在虚拟现实中,该方法可以生成更逼真的3D场景,并支持更丰富的交互功能。
📄 摘要(原文)
This paper addresses the problem of affordance grounding from RGBD images of an object, which aims to localize surface regions corresponding to a text query that describes an action on the object. While existing methods predict affordance regions only on visible surfaces, we propose Affostruction, a generative framework that reconstructs complete geometry from partial observations and grounds affordances on the full shape including unobserved regions. We make three core contributions: generative multi-view reconstruction via sparse voxel fusion that extrapolates unseen geometry while maintaining constant token complexity, flow-based affordance grounding that captures inherent ambiguity in affordance distributions, and affordance-driven active view selection that leverages predicted affordances for intelligent viewpoint sampling. Affostruction achieves 19.1 aIoU on affordance grounding (40.4\% improvement) and 32.67 IoU for 3D reconstruction (67.7\% improvement), enabling accurate affordance prediction on complete shapes.