Towards Open Environments and Instructions: General Vision-Language Navigation via Fast-Slow Interactive Reasoning
作者: Yang Li, Aming Wu, Zihao Zhang, Yahong Han
分类: cs.CV
发布日期: 2026-01-14
💡 一句话要点
提出Slow4fast-VLN,通过快速-慢速交互推理实现通用视觉语言导航
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 通用场景适应 快速-慢速推理 机器人导航 开放环境 强化学习 经验学习
📋 核心要点
- 传统VLN方法在开放环境中泛化能力不足,难以应对多样化的场景和指令。
- 受人类认知系统的启发,论文提出快速-慢速交互推理框架,动态生成策略以适应开放世界。
- 通过经验积累和反思,慢速推理模块优化快速推理模块,提升导航决策的泛化能力。
📝 摘要(中文)
本文针对通用场景适应(GSA-VLN)任务,旨在学习通用的导航能力,以应对多样化的环境和不一致的指令。传统视觉语言导航(VLN)通常基于闭集假设,即训练和测试数据具有相同的图像和指令风格,难以适应开放世界。为了解决这个问题,本文提出了一种名为slow4fast-VLN的动态交互式快速-慢速推理框架。快速推理模块作为一个端到端策略网络,通过实时输入输出动作,并累积执行记录以构建记忆。慢速推理模块分析快速推理模块生成的记忆,提取经验以增强决策的泛化能力。这些经验被结构化地存储,并用于持续优化快速推理模块。与传统方法将快速-慢速推理视为独立机制不同,本文的框架实现了快速-慢速交互,从而使系统能够在面对未知场景时持续适应并高效地执行导航任务。
🔬 方法详解
问题定义:视觉语言导航(VLN)旨在使智能体根据语言指令导航到目标位置。现有方法主要在闭集环境下训练和测试,即训练和测试数据具有相似的图像和指令风格。然而,现实世界是开放的,包含各种未见过的环境,这给现有方法的泛化能力带来了巨大的挑战。因此,论文关注的是通用场景适应(GSA-VLN)任务,旨在学习在多样化环境和不一致指令下的通用导航能力。
核心思路:论文的核心思路是模仿人类的快速和慢速认知系统。快速推理模块负责实时决策,快速响应环境变化;慢速推理模块负责分析历史经验,提取通用策略,并优化快速推理模块。通过快速和慢速推理的交互,智能体可以动态地适应未见过的环境和指令,从而提高导航的泛化能力。
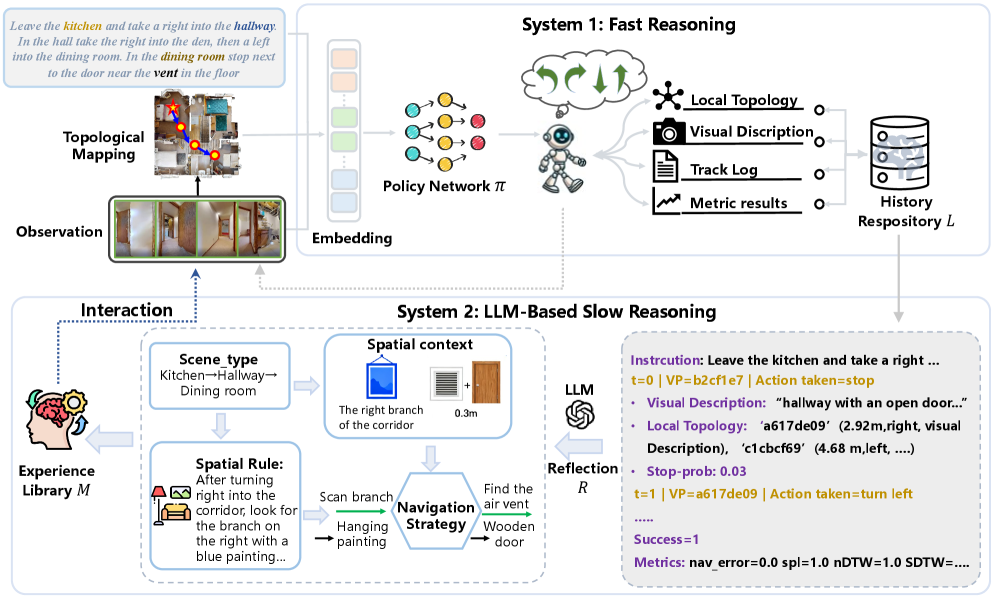
技术框架:slow4fast-VLN框架包含两个主要模块:快速推理模块和慢速推理模块。快速推理模块是一个端到端策略网络,接收视觉输入和语言指令,输出导航动作。它还将执行记录存储在历史仓库中,构建记忆。慢速推理模块分析快速推理模块生成的记忆,提取经验,并用于优化快速推理模块。两个模块通过经验共享和策略优化进行交互。
关键创新:论文的关键创新在于提出了一个动态交互式的快速-慢速推理框架。与传统方法将快速和慢速推理视为独立机制不同,该框架实现了快速和慢速推理之间的交互。慢速推理模块通过分析快速推理模块的经验,提取通用策略,并用于优化快速推理模块,从而提高了导航的泛化能力。
关键设计:论文的关键设计包括:1) 快速推理模块采用端到端神经网络结构,直接从视觉输入和语言指令预测导航动作;2) 慢速推理模块使用深度强化学习算法,从历史经验中学习通用策略;3) 快速和慢速推理模块之间通过经验共享和策略优化进行交互,实现动态适应。
🖼️ 关键图片

📊 实验亮点
论文提出了slow4fast-VLN框架,通过快速-慢速交互推理实现了通用视觉语言导航。实验结果表明,该框架在未见过的环境和指令下,能够有效地提高导航的成功率和效率。具体性能数据未知,但论文强调了其在GSA-VLN任务上的泛化能力。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。例如,在家庭服务机器人中,该技术可以使机器人根据用户的语音指令,在复杂的家庭环境中自主导航到指定位置。在自动驾驶领域,该技术可以提高车辆在复杂交通环境中的导航能力和安全性。此外,该技术还可以应用于虚拟现实游戏中,增强用户的沉浸式体验。
📄 摘要(原文)
Vision-Language Navigation aims to enable agents to navigate to a target location based on language instructions. Traditional VLN often follows a close-set assumption, i.e., training and test data share the same style of the input images and instructions. However, the real world is open and filled with various unseen environments, posing enormous difficulties for close-set methods. To this end, we focus on the General Scene Adaptation (GSA-VLN) task, aiming to learn generalized navigation ability by introducing diverse environments and inconsistent intructions.Towards this task, when facing unseen environments and instructions, the challenge mainly lies in how to enable the agent to dynamically produce generalized strategies during the navigation process. Recent research indicates that by means of fast and slow cognition systems, human beings could generate stable policies, which strengthen their adaptation for open world. Inspired by this idea, we propose the slow4fast-VLN, establishing a dynamic interactive fast-slow reasoning framework. The fast-reasoning module, an end-to-end strategy network, outputs actions via real-time input. It accumulates execution records in a history repository to build memory. The slow-reasoning module analyze the memories generated by the fast-reasoning module. Through deep reflection, it extracts experiences that enhance the generalization ability of decision-making. These experiences are structurally stored and used to continuously optimize the fast-reasoning module. Unlike traditional methods that treat fast-slow reasoning as independent mechanisms, our framework enables fast-slow interaction. By leveraging the experiences from slow reasoning. This interaction allows the system to continuously adapt and efficiently execute navigation tasks when facing unseen scenarios.