Vision Foundation Models for Domain Generalisable Cross-View Localisation in Planetary Ground-Aerial Robotic Teams
作者: Lachlan Holden, Feras Dayoub, Alberto Candela, David Harvey, Tat-Jun Chin
分类: cs.CV, cs.RO
发布日期: 2026-01-14
备注: 7 pages, 10 figures. Presented at the International Conference on Space Robotics (iSpaRo) 2025 in Sendai, Japan. Dataset available: https://doi.org/10.5281/zenodo.17364038
💡 一句话要点
提出基于视觉基础模型的跨视角定位方法,用于行星地空机器人协同。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨视角定位 视觉基础模型 领域泛化 行星探测 地空协同
📋 核心要点
- 行星探测任务中,地面漫游车精确的定位能力是实现高级自主性的关键,但真实场景下带有ground-truth的位置标签数据稀缺。
- 论文提出利用跨视角定位的双编码器深度神经网络,结合视觉基础模型的语义分割能力和大量合成数据,来解决真实数据不足的问题。
- 实验结果表明,该方法结合粒子滤波,能够基于地面图像序列在复杂轨迹上实现精确的位置估计。
📝 摘要(中文)
本文提出了一种新颖的跨视角定位方法,用于解决行星探测中地面漫游车在受限视野的单目RGB图像下,利用空中地图进行自身定位的问题。该方法采用跨视角定位的双编码器深度神经网络,并利用视觉基础模型的语义分割能力和大量合成数据来弥合真实图像的领域差距。此外,本文还贡献了一个新的真实世界漫游车轨迹跨视角数据集,该数据集包含在行星模拟设施中捕获的地面真实定位数据,以及一个包含大量类似合成图像对的数据集。通过使用粒子滤波器进行状态估计,结合跨视角网络,可以在简单和复杂的轨迹上,基于地面图像序列实现精确的位置估计。
🔬 方法详解
问题定义:行星探测任务中,地面漫游车需要利用空中地图和自身携带的单目相机图像进行定位。然而,真实行星环境数据稀缺,难以训练出泛化性强的模型。现有方法难以有效弥合合成数据和真实数据之间的领域差距,导致定位精度不高。
核心思路:论文的核心思路是利用视觉基础模型强大的语义分割能力,结合大量合成数据,训练一个跨视角定位的双编码器深度神经网络。通过语义信息增强特征表示,从而减小合成数据和真实数据之间的领域差距,提高定位精度和泛化能力。
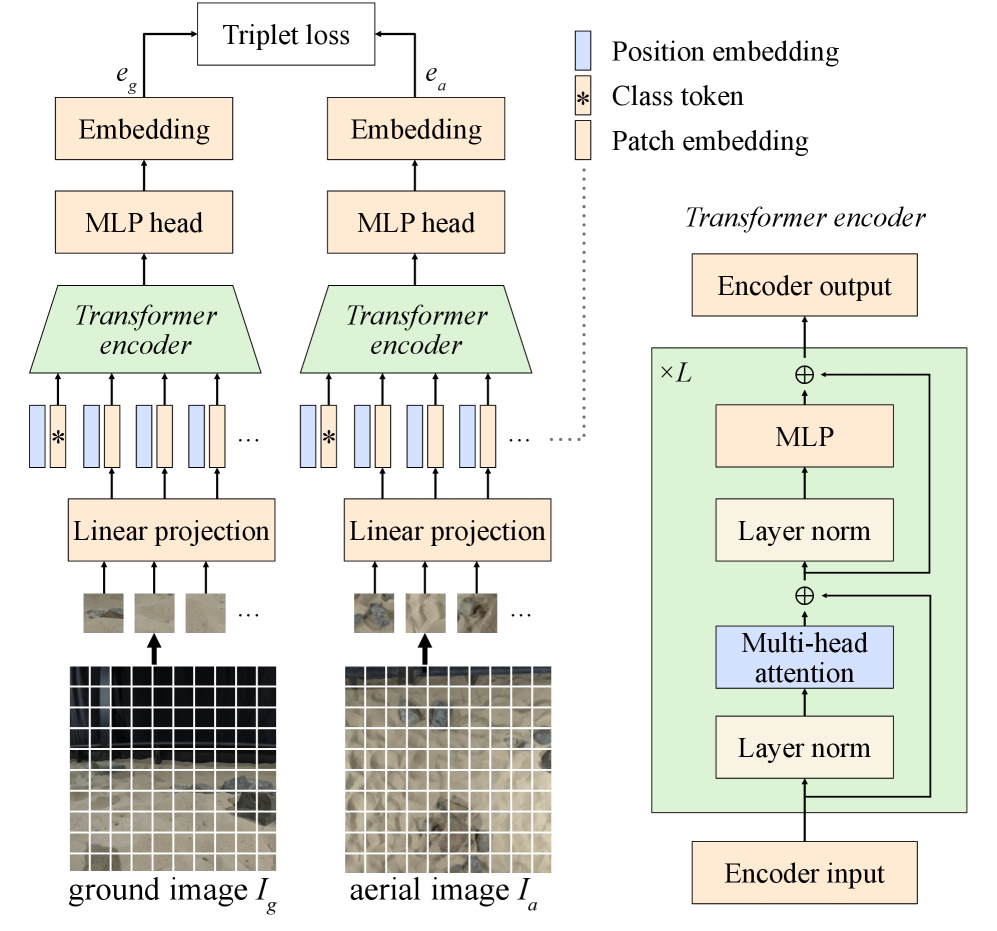
技术框架:该方法主要包含以下几个模块:1) 数据生成模块:生成大量合成的地面和空中图像对,并标注位置信息。2) 特征提取模块:使用双编码器网络分别提取地面图像和空中图像的特征。3) 语义分割模块:利用视觉基础模型对地面图像进行语义分割,提取语义信息。4) 特征融合模块:将地面图像的视觉特征和语义特征进行融合。5) 跨视角定位模块:利用融合后的特征进行跨视角定位,预测漫游车的位置。6) 状态估计模块:使用粒子滤波器对位置序列进行状态估计,提高定位精度。
关键创新:论文的关键创新在于:1) 利用视觉基础模型进行语义分割,增强了特征表示,有效弥合了领域差距。2) 提出了一个跨视角定位的双编码器网络,能够有效地学习地面图像和空中图像之间的对应关系。3) 构建了一个包含真实数据和合成数据的混合数据集,为模型的训练提供了充足的数据。
关键设计:在网络结构方面,采用了双编码器结构,分别提取地面图像和空中图像的特征。损失函数方面,使用了对比损失函数,鼓励相似的图像对在特征空间中靠近,不相似的图像对远离。在数据增强方面,使用了随机旋转、缩放、平移等方法,增加了数据的多样性。
🖼️ 关键图片


📊 实验亮点
论文构建了真实和合成数据集,并验证了所提方法的有效性。实验结果表明,该方法在真实数据集上取得了良好的定位精度,相较于传统方法有显著提升。具体性能数据未知,但摘要强调了在复杂轨迹上的精确位置估计。
🎯 应用场景
该研究成果可应用于未来的行星探测任务中,例如火星车和无人机的协同探测。通过提高地面漫游车的定位精度,可以实现更高级的自主导航和任务规划,从而扩大探测范围,提高探测效率。此外,该方法还可以应用于其他需要跨视角定位的场景,例如自动驾驶、城市建模等。
📄 摘要(原文)
Accurate localisation in planetary robotics enables the advanced autonomy required to support the increased scale and scope of future missions. The successes of the Ingenuity helicopter and multiple planetary orbiters lay the groundwork for future missions that use ground-aerial robotic teams. In this paper, we consider rovers using machine learning to localise themselves in a local aerial map using limited field-of-view monocular ground-view RGB images as input. A key consideration for machine learning methods is that real space data with ground-truth position labels suitable for training is scarce. In this work, we propose a novel method of localising rovers in an aerial map using cross-view-localising dual-encoder deep neural networks. We leverage semantic segmentation with vision foundation models and high volume synthetic data to bridge the domain gap to real images. We also contribute a new cross-view dataset of real-world rover trajectories with corresponding ground-truth localisation data captured in a planetary analogue facility, plus a high volume dataset of analogous synthetic image pairs. Using particle filters for state estimation with the cross-view networks allows accurate position estimation over simple and complex trajectories based on sequences of ground-view images.