Exploring Reliable Spatiotemporal Dependencies for Efficient Visual Tracking
作者: Junze Shi, Yang Yu, Jian Shi, Haibo Luo
分类: cs.CV
发布日期: 2026-01-14
备注: 8 pages, 6 figures
期刊: AAAI2026
💡 一句话要点
STDTrack:探索可靠时空依赖,提升轻量级视觉跟踪性能
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视觉跟踪 时空依赖 轻量级跟踪器 Transformer 多帧融合
📋 核心要点
- 现有轻量级跟踪器训练时采用稀疏采样,未能充分利用视频中的时空信息,限制了性能。
- STDTrack通过密集采样、时空Token传播和多帧信息融合,有效利用时空依赖关系,提升跟踪性能。
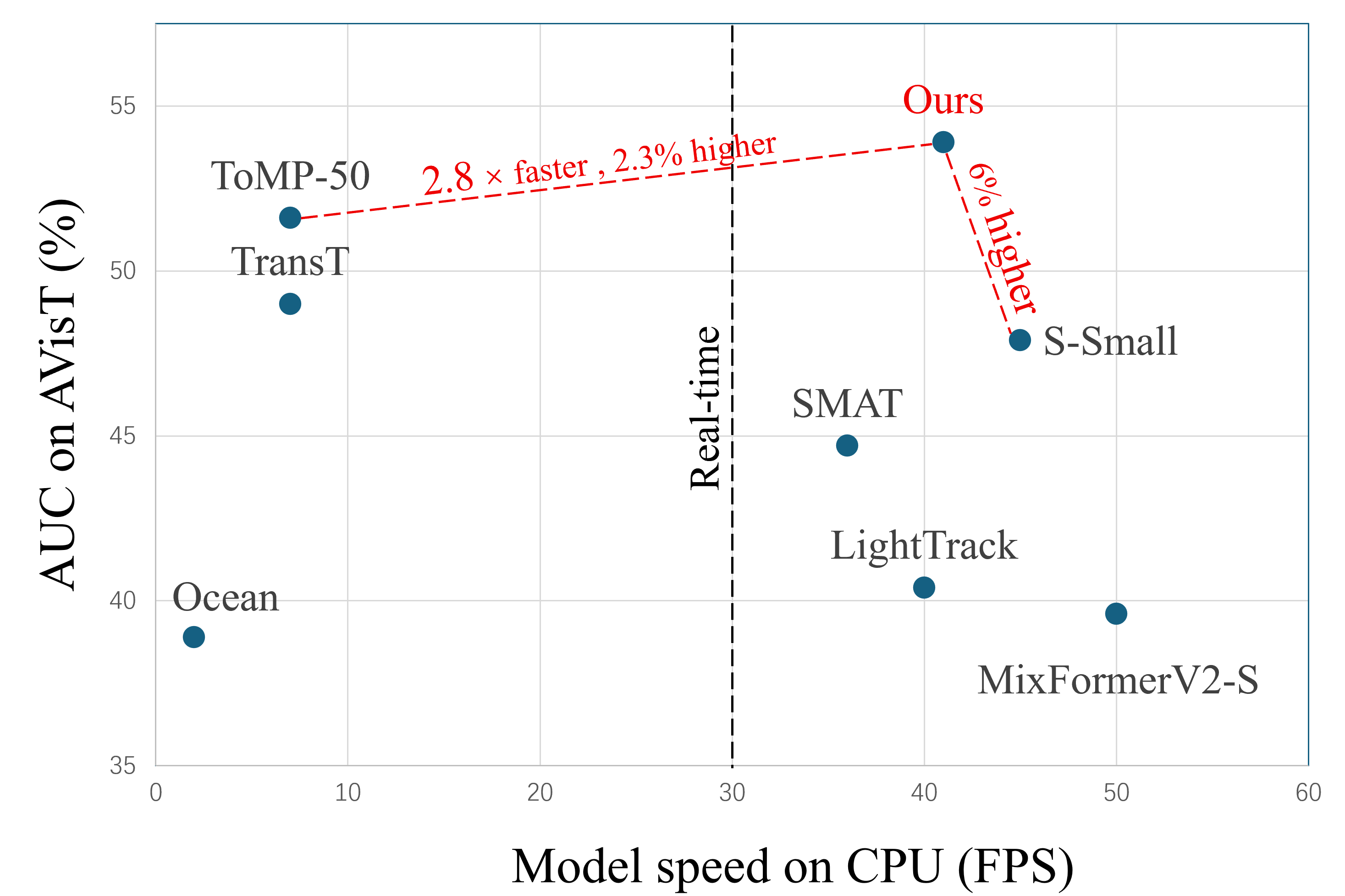
- 实验表明,STDTrack在多个基准测试中达到SOTA,并在GOT-10k上与非实时跟踪器MixFormer性能相当,同时保持实时性。
📝 摘要(中文)
本文提出STDTrack框架,旨在将可靠的时空依赖性集成到轻量级跟踪器中,从而弥合轻量级和高性能跟踪器之间的差距。现有方法普遍采用稀疏采样,限制了视频中时空信息的全面探索。STDTrack通过密集视频采样最大化时空信息利用率,并引入时间传播的时空token来指导每帧特征提取。为了确保全面的目标状态表示,设计了多帧信息融合模块(MFIFM),利用历史上下文增强当前依赖关系。MFIFM在构建的时空Token维护器(STM)上运行,其中基于质量的更新机制确保信息可靠性。考虑到跟踪目标的大小变化,开发了多尺度预测头以动态适应不同大小的对象。大量实验表明,STDTrack在六个基准测试中取得了最先进的结果。在GOT-10k上,STDTrack的性能可与某些高性能非实时跟踪器(例如MixFormer)相媲美,同时以192 FPS(GPU)和41 FPS(CPU)的速度运行。
🔬 方法详解
问题定义:现有基于Transformer的轻量级目标跟踪器虽然取得了显著进展,但训练过程中普遍采用稀疏采样策略,即每个序列仅使用一个模板图像和一个搜索图像。这种稀疏采样无法充分挖掘视频中的时空信息,导致性能瓶颈,限制了轻量级跟踪器与高性能跟踪器之间的差距。
核心思路:STDTrack的核心思路是通过密集视频采样来最大化时空信息的利用。此外,引入时间传播的时空Token来引导每帧特征提取,并设计多帧信息融合模块(MFIFM)来整合历史上下文信息,从而更全面地表示目标状态。通过这些方式,STDTrack旨在提升轻量级跟踪器的性能,使其能够媲美甚至超越某些高性能非实时跟踪器。
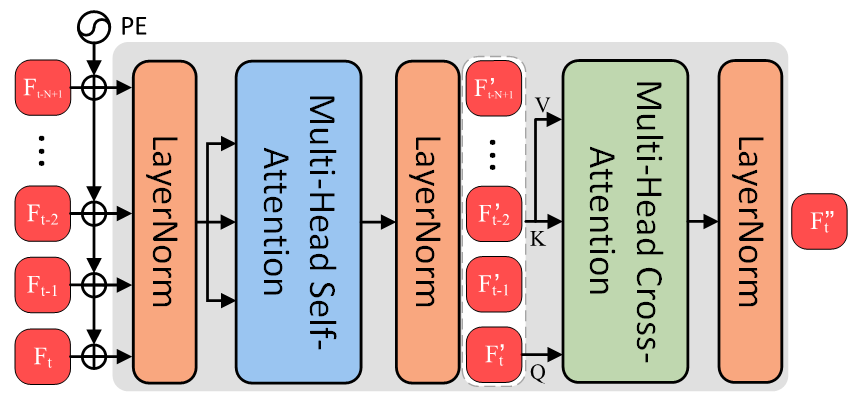
技术框架:STDTrack框架主要包含以下几个关键模块:1) 密集视频采样模块:用于从视频序列中提取更多的模板和搜索图像,以增加训练数据的多样性。2) 时空Token传播模块:引入一个时空Token,该Token在时间维度上进行传播,用于引导每帧特征提取,从而更好地捕捉目标的时空动态变化。3) 多帧信息融合模块(MFIFM):该模块用于融合当前帧的特征和历史帧的特征,从而更全面地表示目标状态。MFIFM在时空Token维护器(STM)上运行,STM负责存储和更新历史帧的特征。4) 多尺度预测头:用于动态适应不同大小的目标,提高跟踪的鲁棒性。
关键创新:STDTrack的关键创新在于将可靠的时空依赖性集成到轻量级跟踪器中。具体来说,密集视频采样、时空Token传播和多帧信息融合是三个关键创新点。与现有方法相比,STDTrack能够更充分地利用视频中的时空信息,从而提升跟踪性能。此外,STM中基于质量的更新机制确保了信息的可靠性。
关键设计:STM(Spatiotemporal Token Maintainer)采用基于质量的更新机制,具体实现细节未知,但推测是根据某种置信度或相似度指标来决定是否更新存储的特征。多尺度预测头的设计细节未知,但可以推测是采用了多个不同尺度的卷积层或Transformer层来预测目标的位置和大小。损失函数的设计细节未知,但可以推测是采用了常用的IoU损失或GIOU损失,以及可能的分类损失。
🖼️ 关键图片

📊 实验亮点
STDTrack在六个基准测试中取得了最先进的结果。特别是在GOT-10k数据集上,STDTrack的性能可以与某些高性能非实时跟踪器(例如MixFormer)相媲美,同时保持了192 FPS(GPU)和41 FPS(CPU)的实时运行速度。这表明STDTrack在性能和效率之间取得了良好的平衡。
🎯 应用场景
STDTrack具有广泛的应用前景,可应用于智能监控、自动驾驶、机器人导航、视频分析等领域。该研究的实际价值在于提升了轻量级视觉跟踪器的性能,使其能够在资源受限的设备上实现高性能的实时目标跟踪。未来,该研究可以进一步扩展到更复杂的场景,例如遮挡、光照变化、快速运动等,从而提高跟踪的鲁棒性和准确性。
📄 摘要(原文)
Recent advances in transformer-based lightweight object tracking have established new standards across benchmarks, leveraging the global receptive field and powerful feature extraction capabilities of attention mechanisms. Despite these achievements, existing methods universally employ sparse sampling during training--utilizing only one template and one search image per sequence--which fails to comprehensively explore spatiotemporal information in videos. This limitation constrains performance and cause the gap between lightweight and high-performance trackers. To bridge this divide while maintaining real-time efficiency, we propose STDTrack, a framework that pioneers the integration of reliable spatiotemporal dependencies into lightweight trackers. Our approach implements dense video sampling to maximize spatiotemporal information utilization. We introduce a temporally propagating spatiotemporal token to guide per-frame feature extraction. To ensure comprehensive target state representation, we disign the Multi-frame Information Fusion Module (MFIFM), which augments current dependencies using historical context. The MFIFM operates on features stored in our constructed Spatiotemporal Token Maintainer (STM), where a quality-based update mechanism ensures information reliability. Considering the scale variation among tracking targets, we develop a multi-scale prediction head to dynamically adapt to objects of different sizes. Extensive experiments demonstrate state-of-the-art results across six benchmarks. Notably, on GOT-10k, STDTrack rivals certain high-performance non-real-time trackers (e.g., MixFormer) while operating at 192 FPS(GPU) and 41 FPS(CPU).