Reasoning Matters for 3D Visual Grounding
作者: Hsiang-Wei Huang, Kuang-Ming Chen, Wenhao Chai, Cheng-Yen Yang, Jen-Hao Cheng, Jenq-Neng Hwang
分类: cs.CV, cs.AI
发布日期: 2026-01-13
备注: 2025 CVPR Workshop on 3D-LLM/VLA: Bridging Language, Vision and Action in 3D Environments
💡 一句话要点
提出Reason3DVG-8B,通过合成数据和LLM微调提升3D视觉定位的推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D视觉定位 大型语言模型 数据合成 推理能力 微调
📋 核心要点
- 现有3D视觉定位模型推理能力有限,依赖大量标注数据,且扩展合成数据带来的性能提升受限。
- 提出一种自动合成3D视觉定位数据的数据管道,该数据包含对应的推理过程,用于LLM的微调。
- 提出的Reason3DVG-8B模型仅使用少量数据,性能超越了先前基于LLM的3D-GRAND模型,证明了数据和推理的重要性。
📝 摘要(中文)
本文针对3D视觉定位任务中现有模型推理能力不足的挑战,提出了一种3D视觉定位数据生成流程,能够自动合成包含推理过程的3D视觉定位数据。利用生成的数据对大型语言模型(LLM)进行微调,提出了Reason3DVG-8B模型。实验结果表明,Reason3DVG-8B仅使用3D-GRAND模型1.6%的训练数据,就超越了该基于LLM的方法,验证了本文数据生成方法的有效性以及推理能力在3D视觉定位中的重要性。
🔬 方法详解
问题定义:现有的3D视觉定位模型在推理能力上存在不足,导致其在复杂场景下的定位精度不高。此外,这些模型通常需要大量的3D标注数据进行训练,而获取这些数据的成本很高。即使通过合成数据进行训练,性能提升也往往不明显,无法与数据收集成本成正比。因此,如何提升3D视觉定位模型的推理能力,同时降低对大量标注数据的依赖,是本文要解决的核心问题。
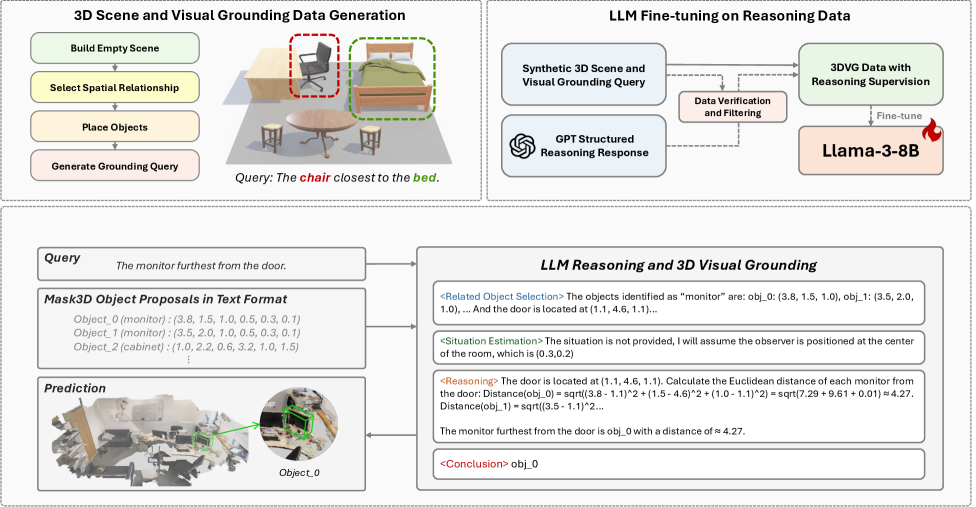
核心思路:本文的核心思路是通过自动生成包含推理过程的3D视觉定位数据,来提升模型的推理能力。通过构建一个数据生成管道,可以自动创建带有推理链的3D场景和对应的文本描述,从而为LLM的微调提供高质量的训练数据。这种方法避免了人工标注的成本,并且能够针对性地生成具有挑战性的推理场景。
技术框架:本文提出的数据生成管道主要包含以下几个阶段:首先,根据预定义的规则和模板,自动生成3D场景,包括物体的摆放位置、大小、颜色等属性。然后,利用LLM生成与场景相关的文本描述,这些描述不仅包含对目标物体的直接指代,还包含推理过程,例如“最大的红色物体左边的物体”。最后,将生成的3D场景和文本描述作为训练数据,对LLM进行微调,使其具备更强的3D视觉定位推理能力。
关键创新:本文最重要的技术创新在于提出了一种自动生成包含推理过程的3D视觉定位数据的数据管道。与以往的合成数据方法不同,本文的方法不仅生成3D场景和文本描述,还模拟了人类的推理过程,使得模型能够学习到如何根据文本描述中的推理线索来定位目标物体。这种方法显著提升了模型的推理能力,并且降低了对大量人工标注数据的依赖。
关键设计:在数据生成方面,设计了多种规则和模板来控制3D场景的复杂度和多样性,例如物体的数量、颜色、大小、位置关系等。在LLM微调方面,采用了标准的Transformer架构,并针对3D视觉定位任务进行了优化,例如引入了3D坐标信息作为输入特征。损失函数方面,采用了交叉熵损失函数来衡量预测结果与真实标签之间的差异,并通过调整损失函数的权重来平衡不同类型的数据。
🖼️ 关键图片


📊 实验亮点
Reason3DVG-8B模型仅使用3D-GRAND模型1.6%的训练数据,就超越了该基线模型。这表明本文提出的数据生成方法能够有效地提升模型的推理能力,并且降低对大量标注数据的依赖。实验结果验证了推理能力在3D视觉定位中的重要性,为未来的研究方向提供了新的思路。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、自动驾驶等领域。例如,机器人可以通过理解自然语言指令,在复杂的3D环境中定位目标物体,从而完成各种任务。在智能家居中,用户可以通过语音控制,让设备执行特定的操作,例如“把电视机旁边的遥控器递给我”。在自动驾驶领域,该技术可以帮助车辆更好地理解周围环境,从而提高驾驶安全性。
📄 摘要(原文)
The recent development of Large Language Models (LLMs) with strong reasoning ability has driven research in various domains such as mathematics, coding, and scientific discovery. Meanwhile, 3D visual grounding, as a fundamental task in 3D understanding, still remains challenging due to the limited reasoning ability of recent 3D visual grounding models. Most of the current methods incorporate a text encoder and visual feature encoder to generate cross-modal fuse features and predict the referring object. These models often require supervised training on extensive 3D annotation data. On the other hand, recent research also focus on scaling synthetic data to train stronger 3D visual grounding LLM, however, the performance gain remains limited and non-proportional to the data collection cost. In this work, we propose a 3D visual grounding data pipeline, which is capable of automatically synthesizing 3D visual grounding data along with corresponding reasoning process. Additionally, we leverage the generated data for LLM fine-tuning and introduce Reason3DVG-8B, a strong 3D visual grounding LLM that outperforms previous LLM-based method 3D-GRAND using only 1.6% of their training data, demonstrating the effectiveness of our data and the importance of reasoning in 3D visual grounding.