M3CoTBench: Benchmark Chain-of-Thought of MLLMs in Medical Image Understanding
作者: Juntao Jiang, Jiangning Zhang, Yali Bi, Jinsheng Bai, Weixuan Liu, Weiwei Jin, Zhucun Xue, Yong Liu, Xiaobin Hu, Shuicheng Yan
分类: eess.IV, cs.CV
发布日期: 2026-01-13
备注: 40 pages, 8 pages
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出M3CoTBench,用于评估多模态大语言模型在医学图像理解中的思维链推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学图像理解 多模态大语言模型 思维链 基准测试 临床推理 可解释性 医疗人工智能
📋 核心要点
- 现有医学图像理解基准侧重最终结果,忽略推理过程,导致模型决策缺乏透明性和可解释性。
- M3CoTBench旨在通过评估CoT推理的正确性、效率、影响和一致性,提升模型在医学图像理解中的能力。
- M3CoTBench包含多样化的数据集和评估指标,揭示了现有MLLM在医学图像推理方面的局限性。
📝 摘要(中文)
本文提出了一个新的基准测试集M3CoTBench,专门用于评估多模态大语言模型(MLLMs)在医学图像理解中思维链(CoT)推理的正确性、效率、影响和一致性。现有的医学图像理解基准通常只关注最终答案,忽略了推理路径,导致缺乏可靠的判断依据,难以辅助医生诊断。M3CoTBench包含:1) 多样化的、多层次难度的数据集,涵盖24种检查类型;2) 13个不同难度的任务;3) 一套针对临床推理定制的CoT特定评估指标(正确性、效率、影响和一致性);4) 多个MLLM的性能分析。M3CoTBench系统地评估了各种医学成像任务中的CoT推理,揭示了MLLM在生成可靠和临床可解释的推理方面的局限性,旨在促进开发透明、可信和诊断准确的医疗人工智能系统。
🔬 方法详解
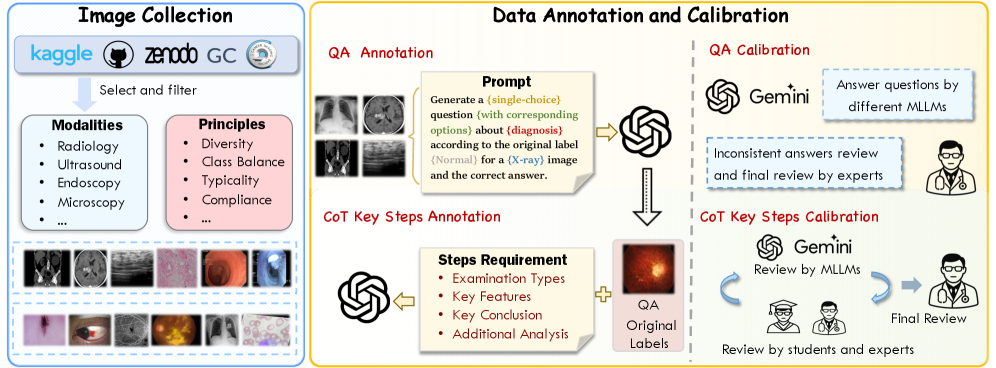
问题定义:现有医学图像理解的基准测试主要关注模型输出的最终答案,而忽略了模型进行推理的过程。这导致模型决策过程不透明,难以判断模型是否真正理解了医学图像,也难以发现模型推理过程中的错误。这种不透明性限制了模型在临床诊断中的应用,因为医生需要了解模型的推理过程才能信任模型的建议。
核心思路:本文的核心思路是引入思维链(Chain-of-Thought, CoT)推理,并构建一个专门用于评估MLLM在医学图像理解中CoT推理能力的基准测试集。通过评估模型在推理过程中的每一步的正确性、效率、影响和一致性,可以更全面地了解模型的推理能力,并发现模型推理过程中的不足。
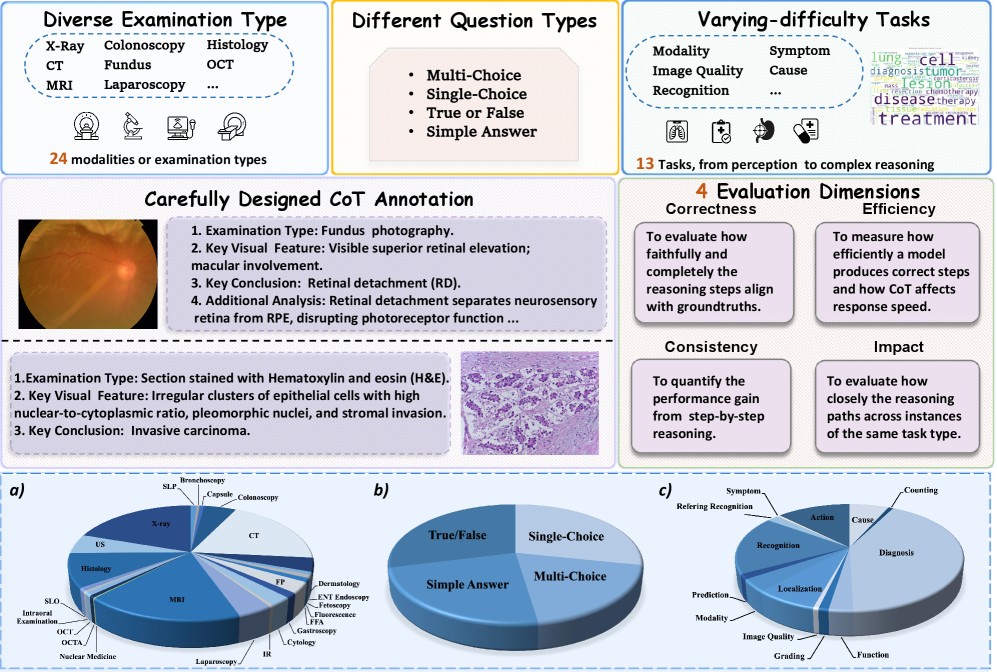
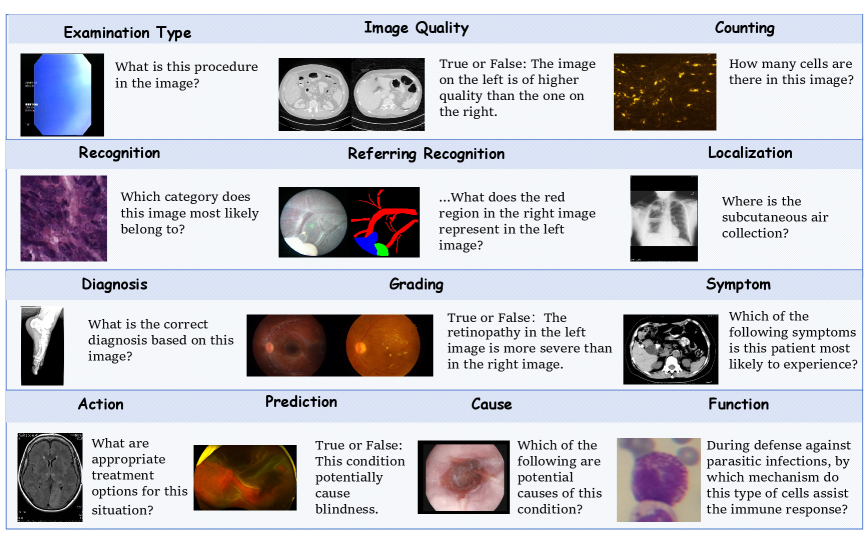
技术框架:M3CoTBench包含以下几个主要组成部分:1) 多样化的数据集,涵盖24种医学检查类型,并具有多层次的难度;2) 13个不同难度的任务,涵盖了医学图像理解的多个方面;3) 一套CoT特定的评估指标,包括正确性、效率、影响和一致性;4) 多个MLLM的性能分析。研究者使用这些组件来系统地评估MLLM在医学图像理解中的CoT推理能力。
关键创新:M3CoTBench的关键创新在于其专注于评估MLLM在医学图像理解中的CoT推理能力。与现有的基准测试不同,M3CoTBench不仅关注模型的最终答案,还关注模型的推理过程。这使得研究者可以更全面地了解模型的推理能力,并发现模型推理过程中的不足。此外,M3CoTBench还提供了一套CoT特定的评估指标,可以更准确地评估模型的CoT推理能力。
关键设计:M3CoTBench的数据集包含了多种医学检查类型,并具有多层次的难度,以确保基准测试的全面性和挑战性。评估指标包括正确性(推理步骤和最终答案的准确性)、效率(推理所需的步骤数)、影响(CoT推理对最终答案的影响)和一致性(不同推理路径的一致性)。具体参数设置和网络结构取决于被评估的MLLM模型。
🖼️ 关键图片
📊 实验亮点
M3CoTBench系统地评估了多个MLLM在各种医学成像任务中的CoT推理能力,揭示了当前MLLM在生成可靠和临床可解释的推理方面的局限性。实验结果表明,现有MLLM在医学图像理解方面仍有很大的提升空间,尤其是在推理的正确性和一致性方面。该基准测试集为未来的研究提供了重要的参考。
🎯 应用场景
M3CoTBench的研究成果可应用于开发更透明、可信和诊断准确的医疗人工智能系统。通过评估和改进MLLM在医学图像理解中的推理能力,可以帮助医生做出更准确的诊断,提高医疗效率,并最终改善患者的治疗效果。该基准测试集可以促进医疗AI领域的进一步研究和发展。
📄 摘要(原文)
Chain-of-Thought (CoT) reasoning has proven effective in enhancing large language models by encouraging step-by-step intermediate reasoning, and recent advances have extended this paradigm to Multimodal Large Language Models (MLLMs). In the medical domain, where diagnostic decisions depend on nuanced visual cues and sequential reasoning, CoT aligns naturally with clinical thinking processes. However, Current benchmarks for medical image understanding generally focus on the final answer while ignoring the reasoning path. An opaque process lacks reliable bases for judgment, making it difficult to assist doctors in diagnosis. To address this gap, we introduce a new M3CoTBench benchmark specifically designed to evaluate the correctness, efficiency, impact, and consistency of CoT reasoning in medical image understanding. M3CoTBench features 1) a diverse, multi-level difficulty dataset covering 24 examination types, 2) 13 varying-difficulty tasks, 3) a suite of CoT-specific evaluation metrics (correctness, efficiency, impact, and consistency) tailored to clinical reasoning, and 4) a performance analysis of multiple MLLMs. M3CoTBench systematically evaluates CoT reasoning across diverse medical imaging tasks, revealing current limitations of MLLMs in generating reliable and clinically interpretable reasoning, and aims to foster the development of transparent, trustworthy, and diagnostically accurate AI systems for healthcare. Project page at https://juntaojianggavin.github.io/projects/M3CoTBench/.