SfMamba: Efficient Source-Free Domain Adaptation via Selective Scan Modeling
作者: Xi Chen, Hongxun Yao, Sicheng Zhao, Jiankun Zhu, Jing Jiang, Kui Jiang
分类: cs.CV
发布日期: 2026-01-13
🔗 代码/项目: GITHUB
💡 一句话要点
SfMamba:通过选择性扫描建模实现高效的无源域自适应
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无源域自适应 领域自适应 选择性扫描建模 Mamba 视觉状态空间模型
📋 核心要点
- 现有SFDA方法在感知范围和计算效率之间存在trade-off,难以有效学习域不变特征。
- SfMamba通过通道视觉状态空间块和语义一致Shuffle策略,增强模型对通道频率特征的捕获和空间鲁棒性。
- 实验结果表明,SfMamba在多个基准测试中优于现有方法,同时保持了良好的参数效率。
📝 摘要(中文)
无源域自适应(SFDA)旨在解决将源域预训练模型适应到无标签目标域的关键挑战,无需访问源数据,从而克服了实际应用中的数据隐私和存储限制。然而,现有的SFDA方法在域不变特征学习中难以平衡感知范围和计算效率。最近,Mamba通过其选择性扫描机制提供了一个有希望的解决方案,该机制能够以线性复杂度进行长程依赖建模。但是,Visual Mamba (即VMamba)在捕获对域对齐至关重要的通道频率特征以及在显著域偏移下保持空间鲁棒性方面仍然受到限制。为了解决这些问题,我们提出了一个名为SfMamba的框架,以充分探索无源模型迁移中的稳定依赖性。SfMamba引入了通道视觉状态空间块,该块支持通道序列扫描以进行域不变特征提取。此外,SfMamba还涉及一种语义一致的Shuffle策略,该策略破坏了2D选择性扫描中的背景块序列,同时保持了预测一致性,以减轻误差累积。在多个基准上的综合评估表明,SfMamba比现有方法实现了始终如一的更强性能,同时保持了良好的参数效率,为SFDA提供了一个实用的解决方案。
🔬 方法详解
问题定义:无源域自适应(SFDA)旨在解决模型在没有源数据的情况下适应到目标域的问题。现有方法在学习域不变特征时,难以兼顾全局感知和计算效率,尤其是在处理显著的域偏移时,性能会显著下降。Visual Mamba虽然具有线性复杂度,但在捕获通道频率特征和保持空间鲁棒性方面存在不足。
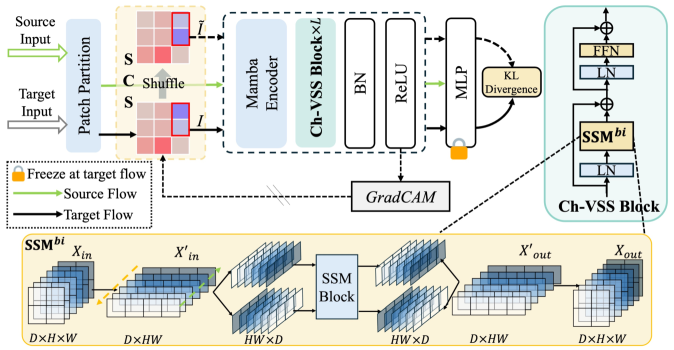
核心思路:SfMamba的核心思路是通过改进Mamba架构,使其能够更好地捕获通道间的依赖关系,并增强模型对空间扰动的鲁棒性。具体来说,通过引入通道视觉状态空间块(Channel-wise Visual State-Space block)来增强通道特征的学习,并使用语义一致的Shuffle策略来减少误差累积。
技术框架:SfMamba框架主要包含两个关键模块:通道视觉状态空间块(CVM)和语义一致Shuffle策略(SCS)。CVM用于提取域不变的通道特征,SCS用于增强模型的空间鲁棒性。整体流程是:首先,输入图像经过CVM提取特征;然后,应用SCS策略对特征进行扰动;最后,将扰动后的特征输入到分类器进行预测。
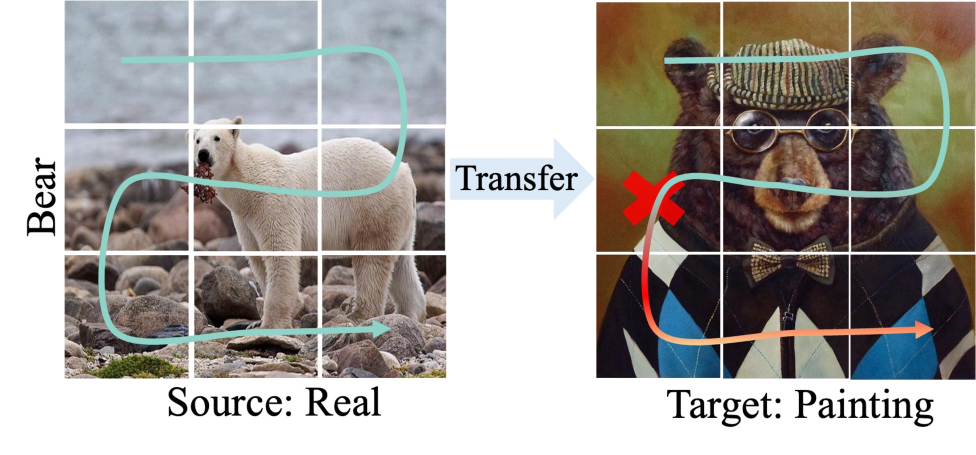
关键创新:SfMamba的关键创新在于:1) 提出了通道视觉状态空间块(CVM),通过通道序列扫描,更好地捕获通道间的依赖关系,从而提取更鲁棒的域不变特征。2) 引入了语义一致的Shuffle策略(SCS),通过扰乱背景块序列,减少误差累积,提高模型的空间鲁棒性。
关键设计:CVM块的设计借鉴了Mamba的selective scan机制,但将其应用于通道维度,允许模型根据输入动态地选择需要关注的通道。SCS策略的关键在于保持预测一致性,即扰动后的特征应该产生与原始特征相似的预测结果。为此,论文设计了一种损失函数来约束扰动后的特征的预测结果。
🖼️ 关键图片

📊 实验亮点
SfMamba在多个SFDA基准测试中取得了显著的性能提升。例如,在Office-Home数据集上,SfMamba的平均准确率比现有最佳方法提高了2-3个百分点。此外,SfMamba在保持高性能的同时,还具有良好的参数效率,使其更易于部署到资源受限的设备上。
🎯 应用场景
SfMamba在数据隐私敏感或存储受限的场景下具有广泛的应用前景,例如医疗影像分析、自动驾驶、安全监控等。该方法可以帮助模型在没有源数据的情况下,快速适应新的目标域,降低部署成本,提高模型的泛化能力。未来,该方法可以进一步扩展到其他领域,例如自然语言处理和语音识别。
📄 摘要(原文)
Source-free domain adaptation (SFDA) tackles the critical challenge of adapting source-pretrained models to unlabeled target domains without access to source data, overcoming data privacy and storage limitations in real-world applications. However, existing SFDA approaches struggle with the trade-off between perception field and computational efficiency in domain-invariant feature learning. Recently, Mamba has offered a promising solution through its selective scan mechanism, which enables long-range dependency modeling with linear complexity. However, the Visual Mamba (i.e., VMamba) remains limited in capturing channel-wise frequency characteristics critical for domain alignment and maintaining spatial robustness under significant domain shifts. To address these, we propose a framework called SfMamba to fully explore the stable dependency in source-free model transfer. SfMamba introduces Channel-wise Visual State-Space block that enables channel-sequence scanning for domain-invariant feature extraction. In addition, SfMamba involves a Semantic-Consistent Shuffle strategy that disrupts background patch sequences in 2D selective scan while preserving prediction consistency to mitigate error accumulation. Comprehensive evaluations across multiple benchmarks show that SfMamba achieves consistently stronger performance than existing methods while maintaining favorable parameter efficiency, offering a practical solution for SFDA. Our code is available at https://github.com/chenxi52/SfMamba.