VideoHEDGE: Entropy-Based Hallucination Detection for Video-VLMs via Semantic Clustering and Spatiotemporal Perturbations
作者: Sushant Gautam, Cise Midoglu, Vajira Thambawita, Michael A. Riegler, Pål Halvorsen
分类: cs.CV, cs.AI
发布日期: 2026-01-13
🔗 代码/项目: GITHUB
💡 一句话要点
VideoHEDGE:基于熵的视频VLM幻觉检测,利用语义聚类和时空扰动
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视频视觉语言模型 幻觉检测 语义聚类 时空扰动 熵 可靠性估计 视频问答
📋 核心要点
- 现有视频视觉语言模型(Video-VLMs)存在幻觉问题,且置信度高,传统不确定性指标无法有效识别。
- VideoHEDGE通过引入语义聚类和时空扰动,扩展了基于熵的可靠性估计方法,用于检测视频问答中的幻觉。
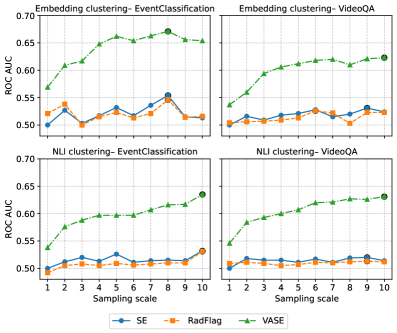
- 实验表明,视觉增强语义熵(VASE)在多个Video-VLMs上取得了最高的ROC-AUC,尤其是在较大扰动下。
📝 摘要(中文)
视频视觉语言模型(Video-VLMs)中的幻觉现象仍然频繁且置信度高,而现有的不确定性指标通常与正确性不一致。我们提出了VideoHEDGE,一个用于视频问答中幻觉检测的模块化框架,它将基于熵的可靠性估计从图像扩展到时间结构化输入。给定一个视频-问题对,VideoHEDGE从干净片段以及光度和时空扰动变体中抽取基线答案和多个高温生成结果,然后使用基于自然语言推理(NLI)或基于嵌入的方法将生成的文本输出聚类成语义假设。聚类级别的概率质量产生三个可靠性分数:语义熵(SE)、RadFlag和视觉增强语义熵(VASE)。我们使用LLM作为裁判在SoccerChat基准上评估VideoHEDGE,以获得二元幻觉标签。在三个7B Video-VLMs(Qwen2-VL、Qwen2.5-VL和一个SoccerChat微调模型)上,VASE始终获得最高的ROC-AUC,尤其是在较大的失真预算下,而SE和RadFlag通常接近随机水平。我们进一步表明,基于嵌入的聚类在检测性能上与基于NLI的聚类相匹配,但计算成本大大降低,并且领域微调降低了幻觉频率,但仅在校准方面产生了适度的改进。hedge-bench PyPI库支持可重现和可扩展的基准测试,完整的代码和实验资源可在https://github.com/Simula/HEDGE#videohedge 获得。
🔬 方法详解
问题定义:论文旨在解决视频视觉语言模型(Video-VLMs)中普遍存在的幻觉问题。现有方法,如直接使用模型置信度或不确定性指标,无法有效区分正确答案和幻觉答案,导致模型在关键应用中不可靠。
核心思路:论文的核心思路是通过引入扰动和语义聚类,来评估模型对视频内容的理解一致性。如果模型对视频的理解是可靠的,那么即使在引入扰动后,生成的答案也应该在语义上保持一致。反之,如果模型产生幻觉,扰动可能会导致答案发生显著变化。
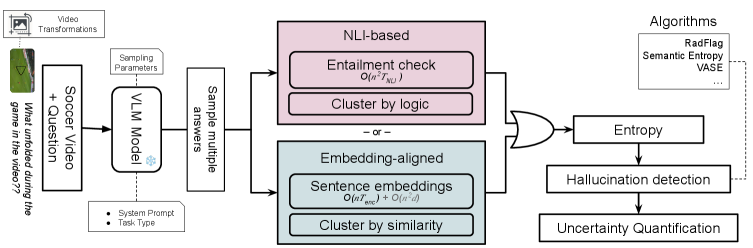
技术框架:VideoHEDGE框架包含以下主要模块:1) 答案生成:对原始视频和经过光度及空时扰动的视频生成多个答案。2) 语义聚类:使用基于自然语言推理(NLI)或嵌入的方法,将生成的答案聚类成不同的语义假设。3) 可靠性评分:基于聚类结果计算语义熵(SE)、RadFlag和视觉增强语义熵(VASE)等可靠性分数。
关键创新:该方法的核心创新在于:1) 将基于熵的可靠性估计从图像扩展到视频,考虑了时间维度。2) 引入了光度和时空扰动,增强了对模型鲁棒性的评估。3) 提出了视觉增强语义熵(VASE),利用视觉信息来提升幻觉检测的准确性。
关键设计:在答案生成阶段,使用了高温采样(high-temperature sampling)来增加答案的多样性。在语义聚类阶段,可以选择基于NLI或嵌入的方法,其中基于嵌入的方法计算成本更低。视觉增强语义熵(VASE)的计算方式未知,但其目标是利用视觉信息来提升幻觉检测的准确性。扰动预算(distortion budgets)的大小会影响VASE的性能。
🖼️ 关键图片
📊 实验亮点
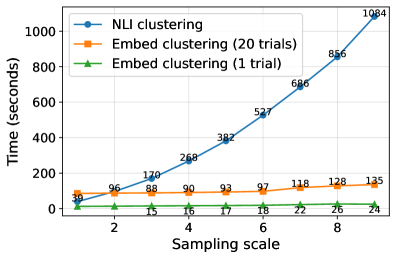
实验结果表明,视觉增强语义熵(VASE)在三个7B Video-VLMs(Qwen2-VL、Qwen2.5-VL和一个SoccerChat微调模型)上始终获得最高的ROC-AUC,尤其是在较大的扰动预算下。基于嵌入的聚类在检测性能上与基于NLI的聚类相匹配,但计算成本大大降低。领域微调降低了幻觉频率,但仅在校准方面产生了适度的改进。
🎯 应用场景
VideoHEDGE可应用于各种需要可靠视频理解的场景,如视频监控、自动驾驶、医疗影像分析和教育视频分析等。通过检测和减少视频VLM中的幻觉,可以提高这些应用的安全性和可靠性,并为用户提供更准确的信息。
📄 摘要(原文)
Hallucinations in video-capable vision-language models (Video-VLMs) remain frequent and high-confidence, while existing uncertainty metrics often fail to align with correctness. We introduce VideoHEDGE, a modular framework for hallucination detection in video question answering that extends entropy-based reliability estimation from images to temporally structured inputs. Given a video-question pair, VideoHEDGE draws a baseline answer and multiple high-temperature generations from both clean clips and photometrically and spatiotemporally perturbed variants, then clusters the resulting textual outputs into semantic hypotheses using either Natural Language Inference (NLI)-based or embedding-based methods. Cluster-level probability masses yield three reliability scores: Semantic Entropy (SE), RadFlag, and Vision-Amplified Semantic Entropy (VASE). We evaluate VideoHEDGE on the SoccerChat benchmark using an LLM-as-a-judge to obtain binary hallucination labels. Across three 7B Video-VLMs (Qwen2-VL, Qwen2.5-VL, and a SoccerChat-finetuned model), VASE consistently achieves the highest ROC-AUC, especially at larger distortion budgets, while SE and RadFlag often operate near chance. We further show that embedding-based clustering matches NLI-based clustering in detection performance at substantially lower computational cost, and that domain fine-tuning reduces hallucination frequency but yields only modest improvements in calibration. The hedge-bench PyPI library enables reproducible and extensible benchmarking, with full code and experimental resources available at https://github.com/Simula/HEDGE#videohedge .