CD^2: Constrained Dataset Distillation for Few-Shot Class-Incremental Learning
作者: Kexin Bao, Daichi Zhang, Hansong Zhang, Yong Li, Yutao Yue, Shiming Ge
分类: cs.CV, cs.AI
发布日期: 2026-01-13
期刊: International Joint Conferences on Artificial Intelligence (IJCAI) 2025
💡 一句话要点
提出CD^2框架,通过约束数据集蒸馏解决少样本类增量学习中的灾难性遗忘问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 少样本学习 类增量学习 灾难性遗忘 数据集蒸馏 知识迁移
📋 核心要点
- FSCIL面临灾难性遗忘问题,现有方法无法有效保存先前学习的重要知识。
- CD^2框架通过数据集蒸馏模块(DDM)和蒸馏约束模块(DCM)解决该问题。
- 实验结果表明,CD^2在三个公共数据集上优于其他先进方法。
📝 摘要(中文)
少样本类增量学习(FSCIL)受到广泛关注,它旨在利用少量训练样本持续进行分类,但面临着关键的灾难性遗忘问题。现有方法通常采用外部记忆来存储先前的知识,并平等地对待增量类,这无法适当地保存先前的重要知识。为了解决这个问题,并受到知识迁移中数据集蒸馏工作的启发,我们提出了一个名为约束数据集蒸馏(CD$^2$)的框架来促进FSCIL,该框架包括一个数据集蒸馏模块(DDM)和一个蒸馏约束模块(DCM)。具体来说,DDM在分类器的指导下合成高度浓缩的样本,迫使模型从少量的增量样本中学习紧凑的、与类相关的关键线索。DCM引入了一个设计的损失来约束先前学习的类分布,这可以更充分地保存蒸馏知识。在三个公共数据集上的大量实验表明,我们的方法优于其他最先进的竞争对手。
🔬 方法详解
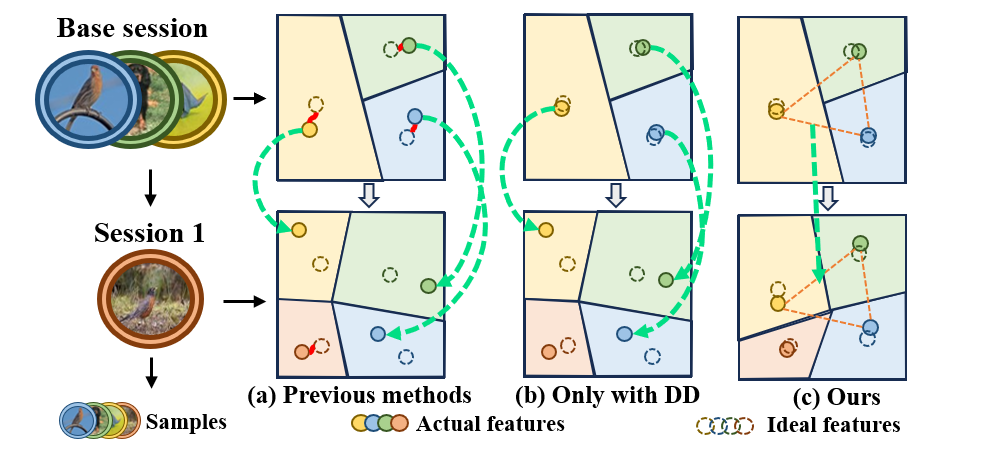
问题定义:论文旨在解决少样本类增量学习(FSCIL)中存在的灾难性遗忘问题。现有的FSCIL方法通常使用外部记忆来存储先前学习的知识,但这些方法平等地对待所有类别,导致先前学习到的重要知识无法得到充分保留,从而影响模型的整体性能。
核心思路:论文的核心思路是利用数据集蒸馏技术,从少量增量样本中提取并浓缩关键的类别相关信息,同时通过蒸馏约束来保留先前学习到的知识分布。通过这种方式,模型可以更有效地学习新知识,同时最大限度地减少对先前知识的遗忘。
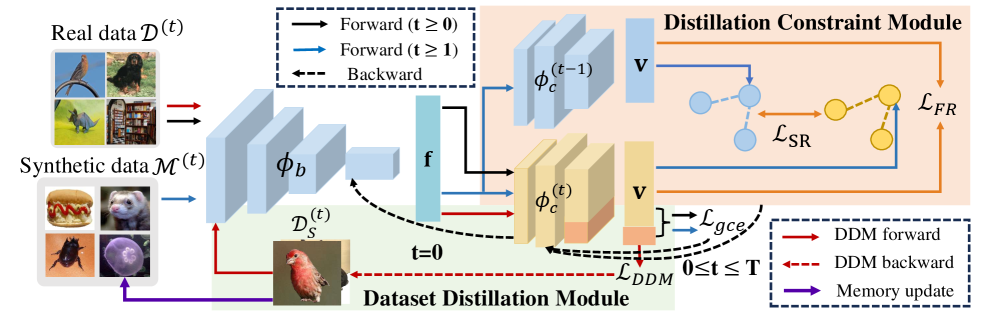
技术框架:CD$^2$框架包含两个主要模块:数据集蒸馏模块(DDM)和蒸馏约束模块(DCM)。DDM负责生成高度浓缩的合成样本,这些样本能够代表增量类别的核心特征。DCM则通过设计的损失函数,约束模型对先前学习到的类别分布的预测,从而保留已有的知识。整体流程是,首先利用DDM生成合成样本,然后利用这些样本和DCM的约束,对模型进行训练。
关键创新:该论文的关键创新在于将数据集蒸馏技术与蒸馏约束相结合,应用于少样本类增量学习。与传统的外部记忆方法不同,CD$^2$通过合成具有代表性的样本来学习新知识,并通过约束先前知识的分布来缓解灾难性遗忘。这种方法能够更有效地利用少量样本,并更好地保留先前学习到的知识。
关键设计:DDM的设计目标是生成能够代表每个类别核心特征的合成样本。具体实现细节未知,但可以推测其利用分类器指导合成过程,确保合成样本能够最大程度地激活对应类别的特征。DCM的关键在于设计的损失函数,该损失函数用于约束模型对先前学习到的类别分布的预测。损失函数的具体形式未知,但其目标是使模型在学习新知识的同时,尽可能保持对先前知识的预测一致性。
🖼️ 关键图片
📊 实验亮点
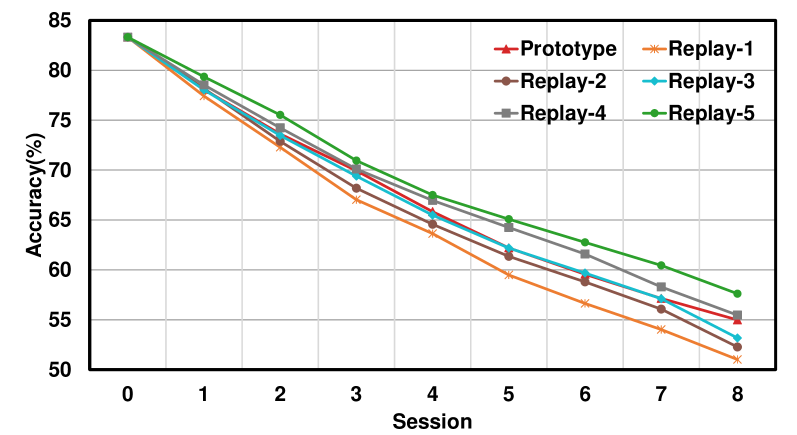
论文在三个公共数据集上进行了大量实验,结果表明CD$^2$框架显著优于其他最先进的FSCIL方法。具体的性能数据和提升幅度在摘要中未给出,但强调了CD$^2$在缓解灾难性遗忘和提高整体分类精度方面的优势。
🎯 应用场景
该研究成果可应用于需要持续学习新类别,但训练样本有限的场景,例如:智能监控系统需要不断识别新的目标,医疗诊断系统需要识别新的疾病类型,以及自动驾驶系统需要识别新的交通标志等。该研究有助于提升这些系统在实际应用中的适应性和鲁棒性。
📄 摘要(原文)
Few-shot class-incremental learning (FSCIL) receives significant attention from the public to perform classification continuously with a few training samples, which suffers from the key catastrophic forgetting problem. Existing methods usually employ an external memory to store previous knowledge and treat it with incremental classes equally, which cannot properly preserve previous essential knowledge. To solve this problem and inspired by recent distillation works on knowledge transfer, we propose a framework termed \textbf{C}onstrained \textbf{D}ataset \textbf{D}istillation (\textbf{CD$^2$}) to facilitate FSCIL, which includes a dataset distillation module (\textbf{DDM}) and a distillation constraint module~(\textbf{DCM}). Specifically, the DDM synthesizes highly condensed samples guided by the classifier, forcing the model to learn compacted essential class-related clues from a few incremental samples. The DCM introduces a designed loss to constrain the previously learned class distribution, which can preserve distilled knowledge more sufficiently. Extensive experiments on three public datasets show the superiority of our method against other state-of-the-art competitors.