Closed-Loop LLM Discovery of Non-Standard Channel Priors in Vision Models
作者: Tolgay Atinc Uzun, Dmitry Ignatov, Radu Timofte
分类: cs.CV
发布日期: 2026-01-13
💡 一句话要点
提出基于闭环LLM的通道先验发现方法,提升视觉模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经架构搜索 大型语言模型 通道配置 抽象语法树 代码生成 深度学习 模型优化
📋 核心要点
- 传统神经架构搜索方法在通道配置优化方面面临组合爆炸和计算资源限制。
- 利用LLM对架构代码结构的推理能力,通过闭环反馈优化通道配置。
- 通过AST变异生成大量有效架构数据,训练LLM学习通道配置与性能之间的关系,并在CIFAR-100上验证有效性。
📝 摘要(中文)
本文提出了一种基于大型语言模型(LLM)的神经架构搜索(NAS)框架,用于解决深度神经网络中通道配置搜索问题。该问题涉及优化层规范(如层宽度),面临张量形状兼容性和计算预算的复杂组合挑战。该方法将搜索过程建模为一系列条件代码生成任务,LLM根据性能遥测数据优化架构规范。通过抽象语法树(AST)突变生成大量有效的、形状一致的架构,解决了数据稀缺问题。实验结果表明,该模型在CIFAR-100数据集上取得了显著的精度提升,验证了该方法的有效性。分析表明,LLM成功地学习了领域特定的架构先验知识,优于随机搜索,突显了语言驱动设计在深度学习中的巨大潜力。
🔬 方法详解
问题定义:论文旨在解决深度神经网络中通道配置的优化问题,即如何自动搜索每一层合适的通道数(层宽度)。现有方法,如随机搜索或基于规则的启发式方法,难以有效探索庞大的搜索空间,且无法充分利用架构的内在结构信息。
核心思路:论文的核心思路是利用大型语言模型(LLM)对代码结构的理解能力,将神经架构搜索过程建模为代码生成任务。通过让LLM学习大量有效架构的结构和性能之间的关系,使其能够生成具有良好性能的通道配置。
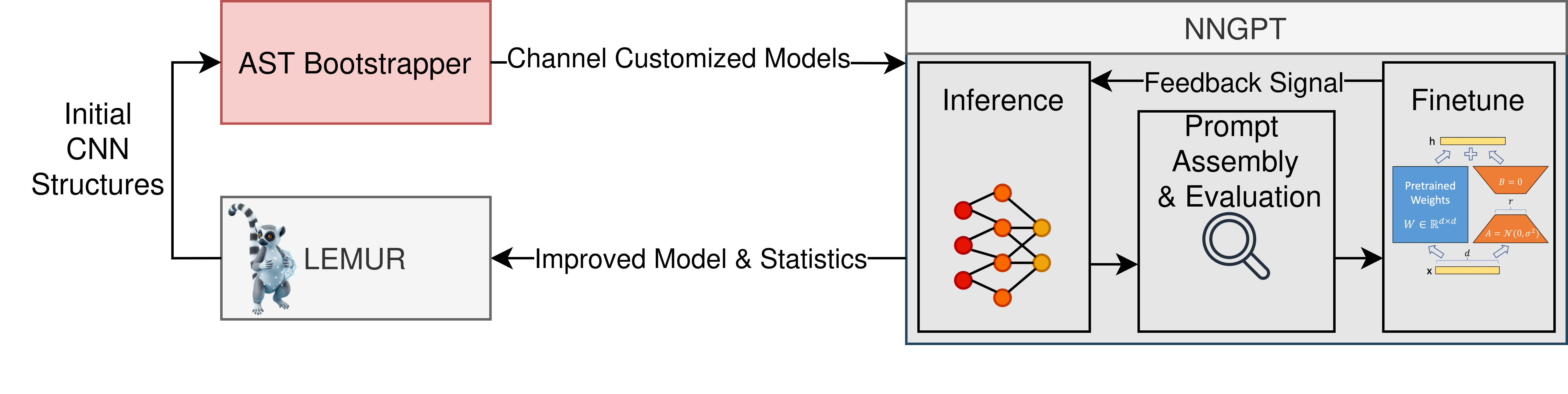
技术框架:整体框架是一个闭环优化流程。首先,通过抽象语法树(AST)变异生成大量有效的、形状一致的神经网络架构,并评估其性能。然后,将架构代码和性能数据输入LLM进行训练,使LLM学习架构先验知识。最后,利用训练好的LLM生成新的架构,并根据性能反馈不断优化,形成闭环。
关键创新:关键创新在于利用LLM进行神经架构搜索,并采用AST变异生成大量训练数据。与传统NAS方法相比,该方法能够更好地利用架构的结构信息,并克服数据稀缺问题。LLM能够学习到复杂的架构设计模式,从而优化特征提取策略。
关键设计:AST变异用于生成大量有效的架构代码,确保生成的架构在张量形状上是兼容的。LLM被训练以预测给定架构的性能,并生成新的、更优的架构。损失函数的设计需要考虑架构的有效性和性能,具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
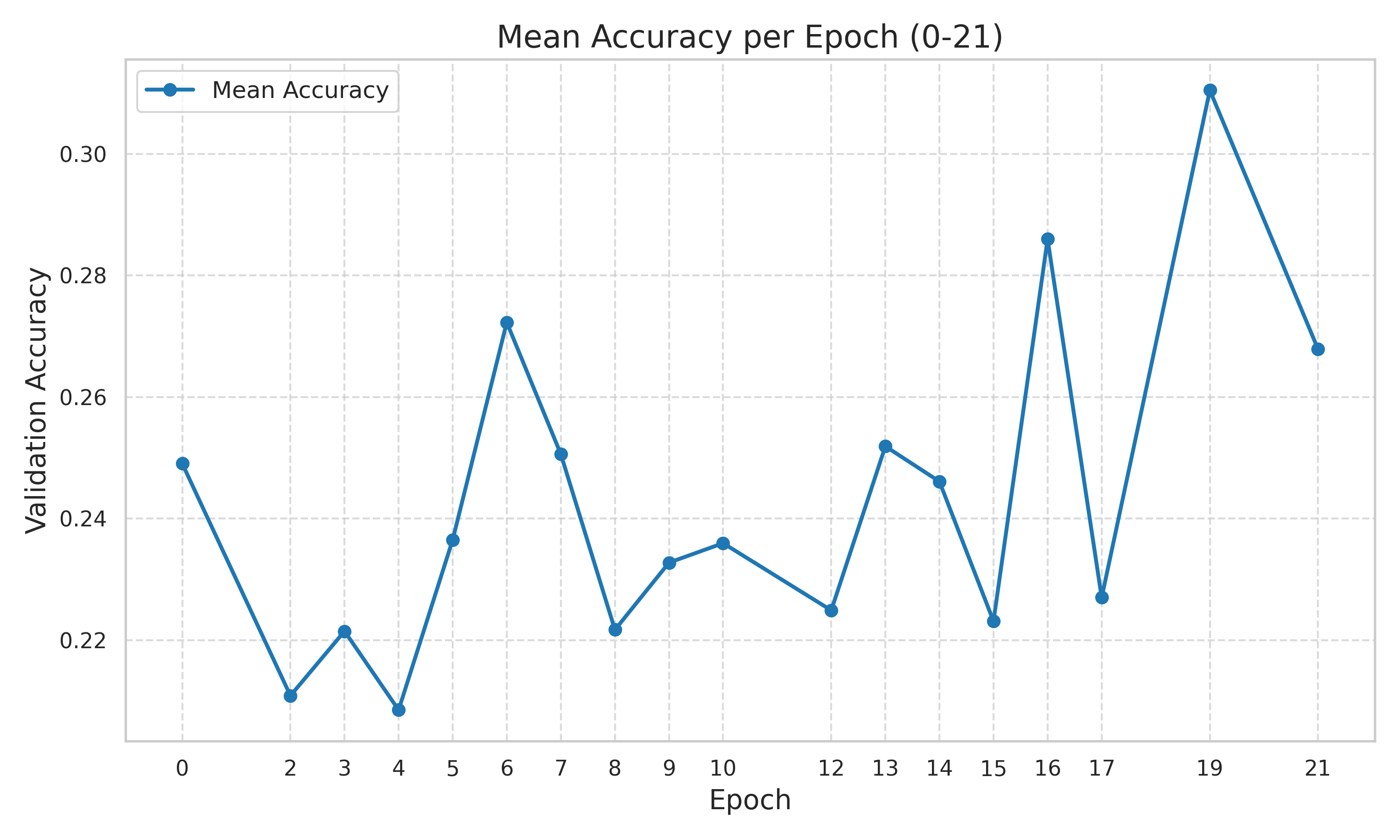
在CIFAR-100数据集上的实验结果表明,该方法能够显著提高模型的精度,优于随机搜索等基线方法。具体提升幅度未知,但论文强调了统计显著性。实验结果验证了LLM学习领域特定架构先验知识的有效性,并突出了语言驱动设计在深度学习中的潜力。
🎯 应用场景
该研究成果可应用于各种计算机视觉任务,例如图像分类、目标检测和图像分割。通过自动优化神经网络的通道配置,可以提高模型的性能和效率,降低人工设计成本。该方法还可推广到其他类型的神经网络架构搜索问题,例如层类型的选择和连接方式的优化,具有广阔的应用前景。
📄 摘要(原文)
Channel configuration search the optimization of layer specifications such as layer widths in deep neural networks presents a complex combinatorial challenge constrained by tensor shape compatibility and computational budgets. We posit that Large Language Models (LLMs) offer a transformative approach to Neural Architecture Search (NAS), capable of reasoning about architectural code structure in ways that traditional heuristics cannot. In this paper, we investigate the application of an LLM-driven NAS framework to the problem of channel configuration. We formulate the search as a sequence of conditional code generation tasks, where an LLM refines architectural specifications based on performance telemetry. Crucially, we address the data scarcity problem by generating a vast corpus of valid, shape-consistent architectures via Abstract Syntax Tree (AST) mutations. While these mutated networks are not necessarily high-performing, they provide the critical volume of structural data required for the LLM to learn the latent relationship between channel configurations and model performance. This allows the LLM to internalize complex design patterns and apply them to optimize feature extraction strategies. Experimental results on CIFAR-100 validate the efficacy of this approach, demonstrating that the model yields statistically significant improvements in accuracy. Our analysis confirms that the LLM successfully acquires domain-specific architectural priors, distinguishing this method from random search and highlighting the immense potential of language-driven design in deep learning.