MMLGNet: Cross-Modal Alignment of Remote Sensing Data using CLIP
作者: Aditya Chaudhary, Sneha Barman, Mainak Singha, Ankit Jha, Girish Mishra, Biplab Banerjee
分类: cs.CV
发布日期: 2026-01-13
备注: Accepted at InGARSS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
MMLGNet:利用CLIP进行遥感数据跨模态对齐,实现语义理解
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 遥感图像 视觉-语言模型 对比学习 语义理解 高光谱图像 激光雷达
📋 核心要点
- 现有遥感数据融合方法难以有效融合多源异构数据,缺乏语义层面的理解能力。
- MMLGNet利用CLIP的视觉-语言模型,通过对比学习将遥感数据与自然语言语义对齐。
- 实验表明,MMLGNet在两个基准数据集上优于多种纯视觉方法,验证了语言监督的有效性。
📝 摘要(中文)
本文提出了一种新颖的多模态框架——多模态语言引导网络(MMLGNet),旨在利用CLIP等视觉-语言模型,将高光谱成像(HSI)和激光雷达(LiDAR)等异构遥感模态与自然语言语义对齐。随着多模态地球观测数据的日益普及,迫切需要能够有效融合光谱、空间和几何信息,并实现语义级理解的方法。MMLGNet采用模态特定的编码器,并通过双向对比学习,在共享潜在空间中将视觉特征与手工制作的文本嵌入对齐。受CLIP训练范式的启发,我们的方法弥合了高维遥感数据和语言引导解释之间的差距。值得注意的是,MMLGNet通过简单的基于CNN的编码器实现了强大的性能,在两个基准数据集上优于几种已建立的多模态纯视觉方法,证明了语言监督的显著优势。代码可在https://github.com/AdityaChaudhary2913/CLIP_HSI 获取。
🔬 方法详解
问题定义:遥感领域存在大量多模态数据,如高光谱图像和激光雷达数据,如何有效地融合这些异构数据,并赋予其语义理解能力是一个关键问题。现有的多模态遥感数据融合方法通常依赖于纯视觉特征,缺乏与自然语言的关联,难以进行高级语义推理和理解。
核心思路:本文的核心思路是借鉴CLIP的视觉-语言对齐能力,将遥感图像的视觉特征与自然语言描述的语义信息对齐。通过学习一个共享的潜在空间,使得视觉特征和文本特征能够相互关联,从而实现对遥感数据的语义理解。这种方法利用了自然语言的先验知识,可以有效地提高遥感数据分析的准确性和可解释性。
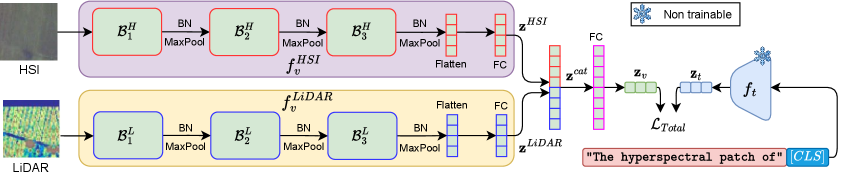
技术框架:MMLGNet的整体框架包括以下几个主要模块:1) 模态特定编码器:分别用于提取高光谱图像和激光雷达数据的视觉特征。这些编码器可以是简单的CNN结构,也可以是更复杂的深度学习模型。2) 文本编码器:用于将自然语言描述转换为文本嵌入。本文采用手工制作的文本嵌入。3) 对比学习模块:通过双向对比学习,将视觉特征和文本嵌入对齐到共享的潜在空间中。该模块使用对比损失函数,鼓励相似的视觉-文本对在潜在空间中靠近,而不相似的视觉-文本对远离。
关键创新:MMLGNet的关键创新在于将CLIP的视觉-语言对齐思想引入到遥感领域,并成功地应用于多模态遥感数据的融合和语义理解。与传统的纯视觉方法相比,MMLGNet利用了自然语言的语义信息,可以更好地理解遥感图像的内容和含义。此外,MMLGNet采用简单的CNN编码器,也能取得良好的性能,表明了语言监督的有效性。
关键设计:MMLGNet的关键设计包括:1) 双向对比学习:同时学习视觉到文本和文本到视觉的映射关系,从而提高对齐的准确性。2) 对比损失函数:使用InfoNCE损失函数,鼓励相似的视觉-文本对在潜在空间中靠近,而不相似的视觉-文本对远离。3) 模态特定编码器:针对不同的遥感模态,设计不同的编码器结构,以更好地提取各自的特征。
🖼️ 关键图片
📊 实验亮点
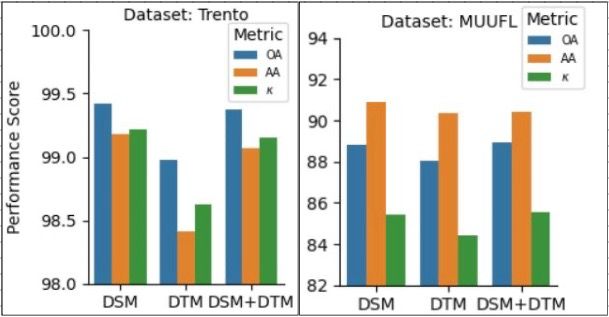
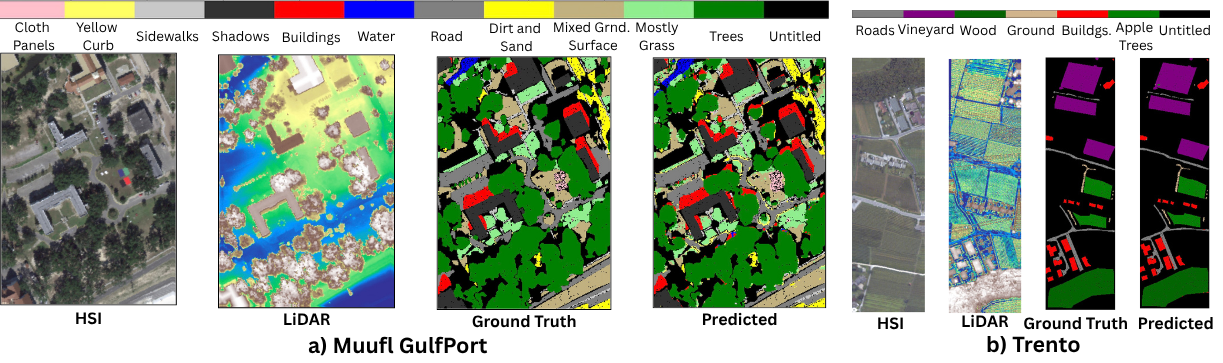
MMLGNet在两个基准数据集上取得了优于多种纯视觉方法的性能。实验结果表明,即使使用简单的CNN编码器,MMLGNet也能有效地将遥感数据与自然语言语义对齐,证明了语言监督在遥感数据分析中的重要作用。该方法为多模态遥感数据融合提供了一种新的思路。
🎯 应用场景
MMLGNet可应用于智慧城市建设、环境监测、农业估产等领域。通过将遥感数据与自然语言描述相结合,可以实现更智能化的遥感图像解译和分析,例如自动识别农作物类型、监测森林火灾、评估城市绿化覆盖率等。该研究有助于提升遥感技术的应用价值,为相关领域的决策提供更可靠的依据。
📄 摘要(原文)
In this paper, we propose a novel multimodal framework, Multimodal Language-Guided Network (MMLGNet), to align heterogeneous remote sensing modalities like Hyperspectral Imaging (HSI) and LiDAR with natural language semantics using vision-language models such as CLIP. With the increasing availability of multimodal Earth observation data, there is a growing need for methods that effectively fuse spectral, spatial, and geometric information while enabling semantic-level understanding. MMLGNet employs modality-specific encoders and aligns visual features with handcrafted textual embeddings in a shared latent space via bi-directional contrastive learning. Inspired by CLIP's training paradigm, our approach bridges the gap between high-dimensional remote sensing data and language-guided interpretation. Notably, MMLGNet achieves strong performance with simple CNN-based encoders, outperforming several established multimodal visual-only methods on two benchmark datasets, demonstrating the significant benefit of language supervision. Codes are available at https://github.com/AdityaChaudhary2913/CLIP_HSI.