UM-Text: A Unified Multimodal Model for Image Understanding
作者: Lichen Ma, Xiaolong Fu, Gaojing Zhou, Zipeng Guo, Ting Zhu, Yichun Liu, Yu Shi, Jason Li, Junshi Huang
分类: cs.CV
发布日期: 2026-01-13
💡 一句话要点
UM-Text:提出统一多模态模型,解决图像理解中的视觉文本编辑与风格一致性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉文本编辑 多模态模型 图像理解 风格一致性 视觉语言模型
📋 核心要点
- 现有视觉文本编辑方法在指定文本内容和属性时步骤复杂,且难以保证与参考图像的风格一致性。
- UM-Text通过VLM理解指令和参考图像,利用UM-Encoder融合多模态信息,实现风格一致的视觉文本编辑。
- 实验结果表明,UM-Text在多个基准测试中取得了SOTA性能,并贡献了大规模视觉文本数据集UM-DATA-200K。
📝 摘要(中文)
本文提出了一种统一的多模态模型UM-Text,用于通过自然语言指令进行上下文理解和视觉文本编辑。该模型利用视觉语言模型(VLM)处理指令和参考图像,从而根据上下文信息精心设计文本内容和布局。为了生成准确且和谐的视觉文本图像,进一步提出了UM-Encoder来组合各种条件信息的嵌入,VLM根据输入指令自动配置组合方式。在训练过程中,设计了区域一致性损失,为潜在空间和RGB空间中的字形生成提供更有效的监督,并采用定制的三阶段训练策略来进一步提高模型性能。此外,还贡献了一个大规模视觉文本图像数据集UM-DATA-200K,用于模型训练。在多个公共基准测试上的大量定性和定量结果表明,该方法达到了最先进的性能。
🔬 方法详解
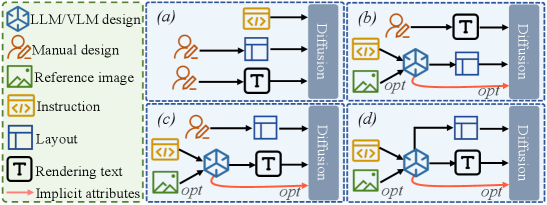
问题定义:论文旨在解决视觉文本编辑任务中,现有方法难以保证生成文本与参考图像风格一致性的问题。现有方法通常需要复杂的步骤来指定文本内容和属性,例如字体大小、颜色和布局,而忽略了与参考图像的整体风格协调。
核心思路:论文的核心思路是利用视觉语言模型(VLM)来理解自然语言指令和参考图像,从而根据上下文信息自动设计文本内容和布局,并使用UM-Encoder融合多模态信息,确保生成的视觉文本在风格上与参考图像保持一致。
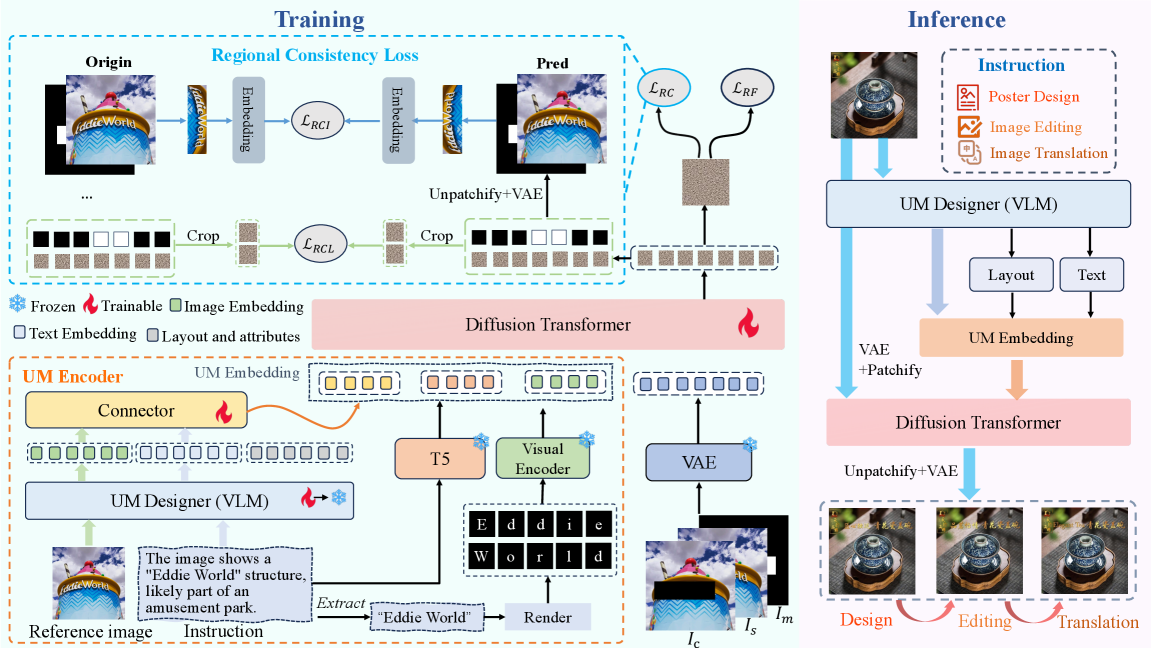
技术框架:UM-Text模型主要包含VLM和UM-Encoder两个核心模块。VLM负责处理指令和参考图像,输出文本内容和布局信息。UM-Encoder负责融合VLM的输出以及其他条件信息,生成最终的视觉文本图像。训练过程采用三阶段训练策略,并引入区域一致性损失来提升字形生成的质量。
关键创新:论文的关键创新在于提出了一个统一的多模态模型UM-Text,该模型能够通过VLM理解上下文信息,并利用UM-Encoder融合多模态信息,从而生成风格一致的视觉文本。此外,区域一致性损失和三阶段训练策略也为模型性能的提升做出了贡献。
关键设计:UM-Encoder的具体结构未知,但其核心功能是根据VLM的输出以及其他条件信息,自适应地调整各种信息的组合方式。区域一致性损失在潜在空间和RGB空间上对字形生成进行监督,确保生成的字形在风格上与参考图像保持一致。三阶段训练策略的具体细节未知,但其目的是逐步提升模型的性能。
🖼️ 关键图片

📊 实验亮点
UM-Text在多个公共基准测试中取得了最先进的性能。论文贡献了一个大规模视觉文本图像数据集UM-DATA-200K,包含多样化的场景,为模型训练提供了充足的数据支持。具体的性能数据和对比基线在摘要中未给出,属于未知信息。
🎯 应用场景
UM-Text具有广泛的应用前景,例如图像编辑、广告设计、社交媒体内容生成等。它可以帮助用户快速生成具有特定风格的视觉文本,提高内容创作的效率和质量。未来,该技术有望应用于更复杂的场景,例如视频编辑和三维内容生成。
📄 摘要(原文)
With the rapid advancement of image generation, visual text editing using natural language instructions has received increasing attention. The main challenge of this task is to fully understand the instruction and reference image, and thus generate visual text that is style-consistent with the image. Previous methods often involve complex steps of specifying the text content and attributes, such as font size, color, and layout, without considering the stylistic consistency with the reference image. To address this, we propose UM-Text, a unified multimodal model for context understanding and visual text editing by natural language instructions. Specifically, we introduce a Visual Language Model (VLM) to process the instruction and reference image, so that the text content and layout can be elaborately designed according to the context information. To generate an accurate and harmonious visual text image, we further propose the UM-Encoder to combine the embeddings of various condition information, where the combination is automatically configured by VLM according to the input instruction. During training, we propose a regional consistency loss to offer more effective supervision for glyph generation on both latent and RGB space, and design a tailored three-stage training strategy to further enhance model performance. In addition, we contribute the UM-DATA-200K, a large-scale visual text image dataset on diverse scenes for model training. Extensive qualitative and quantitative results on multiple public benchmarks demonstrate that our method achieves state-of-the-art performance.