Enhancing Image Quality Assessment Ability of LMMs via Retrieval-Augmented Generation
作者: Kang Fu, Huiyu Duan, Zicheng Zhang, Yucheng Zhu, Jun Zhao, Xiongkuo Min, Jia Wang, Guangtao Zhai
分类: cs.CV, cs.AI
发布日期: 2026-01-13
💡 一句话要点
提出IQARAG,通过检索增强生成提升大模型在图像质量评估任务中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像质量评估 大型多模态模型 检索增强生成 零样本学习 视觉感知
📋 核心要点
- 现有LMM在图像质量评估中需要昂贵的微调以对齐质量相关token分布。
- IQARAG利用检索增强生成,通过检索相似但质量不同的参考图像来提升LMM的IQA能力。
- 实验表明IQARAG在多个IQA数据集上有效提升LMM性能,提供了一种资源高效的替代方案。
📝 摘要(中文)
大型多模态模型(LMMs)最近在低级视觉感知任务中展现出卓越的潜力,特别是在图像质量评估(IQA)方面,表现出强大的零样本能力。然而,要达到最先进的性能通常需要计算成本高昂的微调方法,这些方法旨在使输出中与质量相关的token分布与图像质量水平对齐。受到最近LMM的免训练工作的启发,我们引入了IQARAG,这是一种新颖的免训练框架,可增强LMM的IQA能力。IQARAG利用检索增强生成(RAG)来检索一些语义相似但质量不同的参考图像,以及输入图像对应的平均意见得分(MOS)。这些检索到的图像和输入图像被集成到一个特定的提示中。检索到的图像为LMM提供了IQA任务的视觉感知锚点。IQARAG包含三个关键阶段:检索特征提取、图像检索以及集成与质量得分生成。在包括KADID、KonIQ、LIVE Challenge和SPAQ在内的多个不同IQA数据集上进行的大量实验表明,所提出的IQARAG有效地提高了LMM的IQA性能,为质量评估提供了一种资源高效的微调替代方案。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型(LMMs)在图像质量评估(IQA)任务中,需要大量计算资源进行微调才能达到state-of-the-art性能的问题。现有微调方法的痛点在于计算成本高昂,且需要针对特定数据集进行调整,泛化能力受限。
核心思路:论文的核心思路是利用检索增强生成(RAG)框架,通过检索与输入图像语义相似但质量不同的参考图像,为LMM提供视觉感知锚点,从而提升其IQA能力。这种方法无需对LMM进行微调,降低了计算成本,并提高了泛化能力。通过引入参考图像及其质量信息,引导LMM更好地理解输入图像的质量。
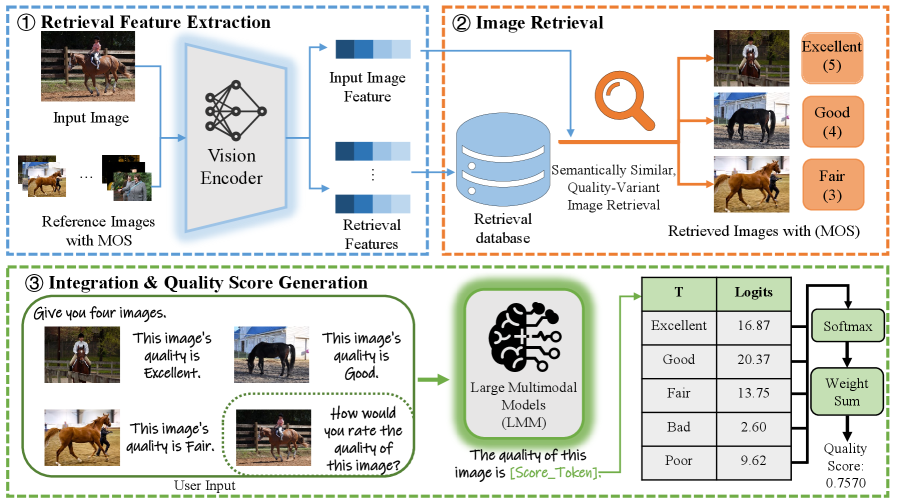
技术框架:IQARAG框架包含三个主要阶段:1)检索特征提取:提取输入图像和数据库中所有图像的视觉特征,用于后续的图像检索。2)图像检索:基于提取的视觉特征,检索数据库中与输入图像语义相似且质量不同的参考图像,并获取其对应的平均意见得分(MOS)。3)集成与质量得分生成:将检索到的参考图像及其MOS与输入图像一起整合到特定的提示(prompt)中,输入到LMM中,由LMM生成最终的图像质量得分。
关键创新:该方法最重要的创新点在于利用RAG框架,在不进行微调的情况下,显著提升了LMM在IQA任务中的性能。通过检索质量不同的参考图像,为LMM提供了一个可比较的视觉上下文,使其能够更准确地评估图像质量。这种方法避免了传统微调方法的高计算成本和过拟合风险。
关键设计:在检索特征提取阶段,论文使用了预训练的视觉模型(具体模型未知)提取图像特征。在图像检索阶段,使用了余弦相似度等度量方法来衡量图像之间的相似性。在集成与质量得分生成阶段,设计了特定的prompt模板,将输入图像、参考图像及其MOS整合到一起,输入到LMM中。具体的prompt模板内容未知,但其设计对最终的IQA性能至关重要。
🖼️ 关键图片


📊 实验亮点
实验结果表明,IQARAG在KADID、KonIQ、LIVE Challenge和SPAQ等多个IQA数据集上显著提升了LMM的性能。相较于不使用RAG的baseline方法,IQARAG在多个数据集上取得了明显的性能提升,证明了其有效性。具体的性能提升幅度在摘要中没有给出明确的数据,但强调了其作为微调的资源高效替代方案的优势。
🎯 应用场景
该研究成果可广泛应用于图像处理、计算机视觉、多媒体等领域。例如,可以用于自动图像质量监控、图像增强算法的评估、图像压缩算法的优化等。该方法无需微调的特性使其易于部署和应用,具有很高的实际应用价值和潜力。未来,可以进一步探索如何利用更先进的检索和生成技术来提升IQA性能。
📄 摘要(原文)
Large Multimodal Models (LMMs) have recently shown remarkable promise in low-level visual perception tasks, particularly in Image Quality Assessment (IQA), demonstrating strong zero-shot capability. However, achieving state-of-the-art performance often requires computationally expensive fine-tuning methods, which aim to align the distribution of quality-related token in output with image quality levels. Inspired by recent training-free works for LMM, we introduce IQARAG, a novel, training-free framework that enhances LMMs' IQA ability. IQARAG leverages Retrieval-Augmented Generation (RAG) to retrieve some semantically similar but quality-variant reference images with corresponding Mean Opinion Scores (MOSs) for input image. These retrieved images and input image are integrated into a specific prompt. Retrieved images provide the LMM with a visual perception anchor for IQA task. IQARAG contains three key phases: Retrieval Feature Extraction, Image Retrieval, and Integration & Quality Score Generation. Extensive experiments across multiple diverse IQA datasets, including KADID, KonIQ, LIVE Challenge, and SPAQ, demonstrate that the proposed IQARAG effectively boosts the IQA performance of LMMs, offering a resource-efficient alternative to fine-tuning for quality assessment.