KidVis: Do Multimodal Large Language Models Possess the Visual Perceptual Capabilities of a 6-Year-Old?
作者: Xianfeng Wang, Kaiwei Zhang, Qi Jia, Zijian Chen, Guangtao Zhai, Xiongkuo Min
分类: cs.CV
发布日期: 2026-01-13
💡 一句话要点
KidVis:评估多模态大语言模型是否具备6岁儿童的视觉感知能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉感知 基准测试 视觉智能 缩放定律 人类视觉发展 人工智能
📋 核心要点
- 现有MLLM在高级推理任务中表现出色,但缺乏对基础视觉感知的系统性评估。
- KidVis基准将视觉智能分解为六种原子能力,并设计了相应的低语义依赖视觉任务。
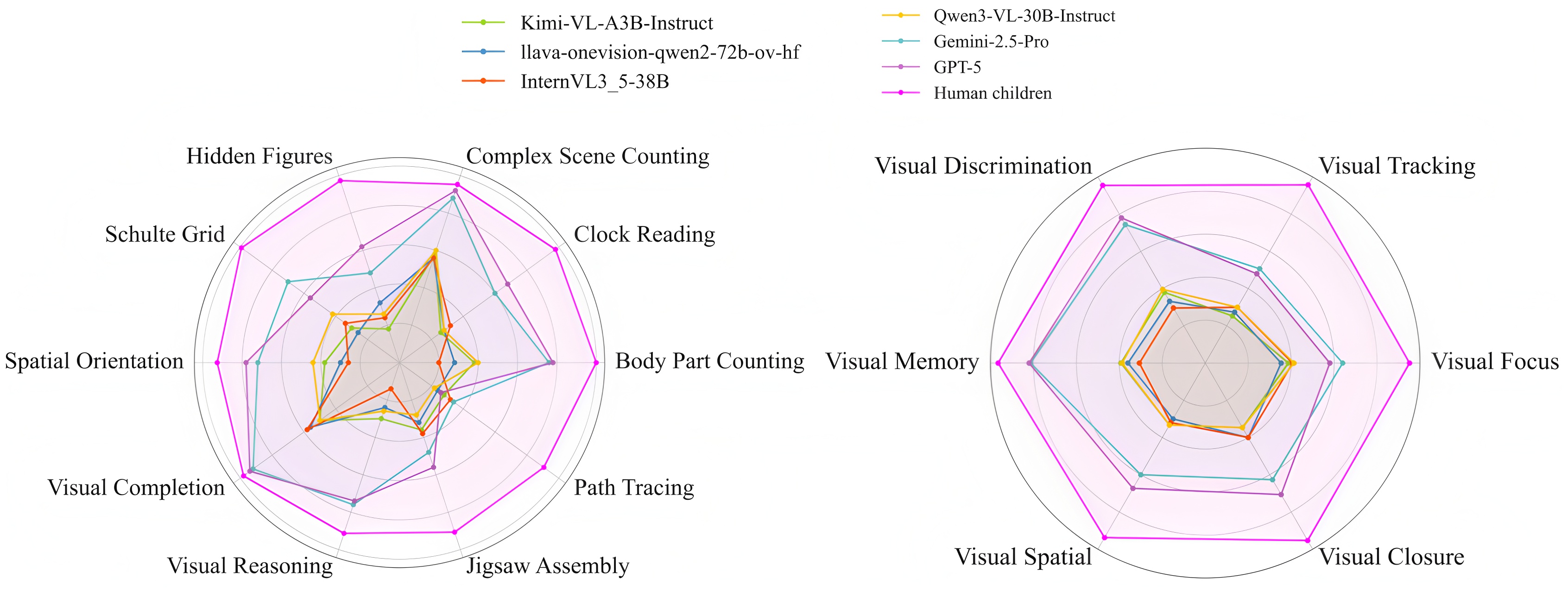
- 实验表明,现有MLLM在KidVis上的表现远低于人类儿童,且存在“缩放定律悖论”。
📝 摘要(中文)
多模态大语言模型(MLLMs)在高层次推理任务(如复杂图表理解)中表现出令人印象深刻的能力,但它们是否具备与人类直觉相当的基本视觉感知能力仍是一个开放性问题。为了研究这一点,我们提出了KidVis,这是一个基于人类视觉发展理论的新基准。KidVis将视觉智能分解为六种原子能力——专注力、追踪能力、辨别能力、记忆力、空间能力和闭合能力——这些能力6-7岁的儿童已经具备,包含10类低语义依赖的视觉任务。对20个最先进的MLLM进行评估,并与人类生理基线进行比较,结果显示出明显的性能差距。结果表明,虽然人类儿童的平均得分接近完美,达到95.32,但最先进的GPT-5仅达到67.33。至关重要的是,我们观察到一种“缩放定律悖论”:简单地增加模型参数并不能线性地提高这些基本视觉能力。这项研究证实,目前的MLLM,尽管具有强大的推理能力,但缺乏通用视觉智能所需的基本生理感知基元。
🔬 方法详解
问题定义:论文旨在评估当前多模态大语言模型(MLLMs)是否具备与6岁儿童相当的基础视觉感知能力。现有方法主要关注MLLMs的高级推理能力,缺乏对底层视觉感知能力的系统性评估,无法判断MLLMs是否真正理解视觉信息,还是仅仅依赖于语言知识进行推理。
核心思路:论文的核心思路是借鉴人类视觉发展理论,将视觉智能分解为若干原子能力(如专注力、追踪能力、辨别能力等),并设计相应的视觉任务来评估MLLMs在这些原子能力上的表现。通过与人类生理基线进行对比,可以更客观地了解MLLMs的视觉感知能力。
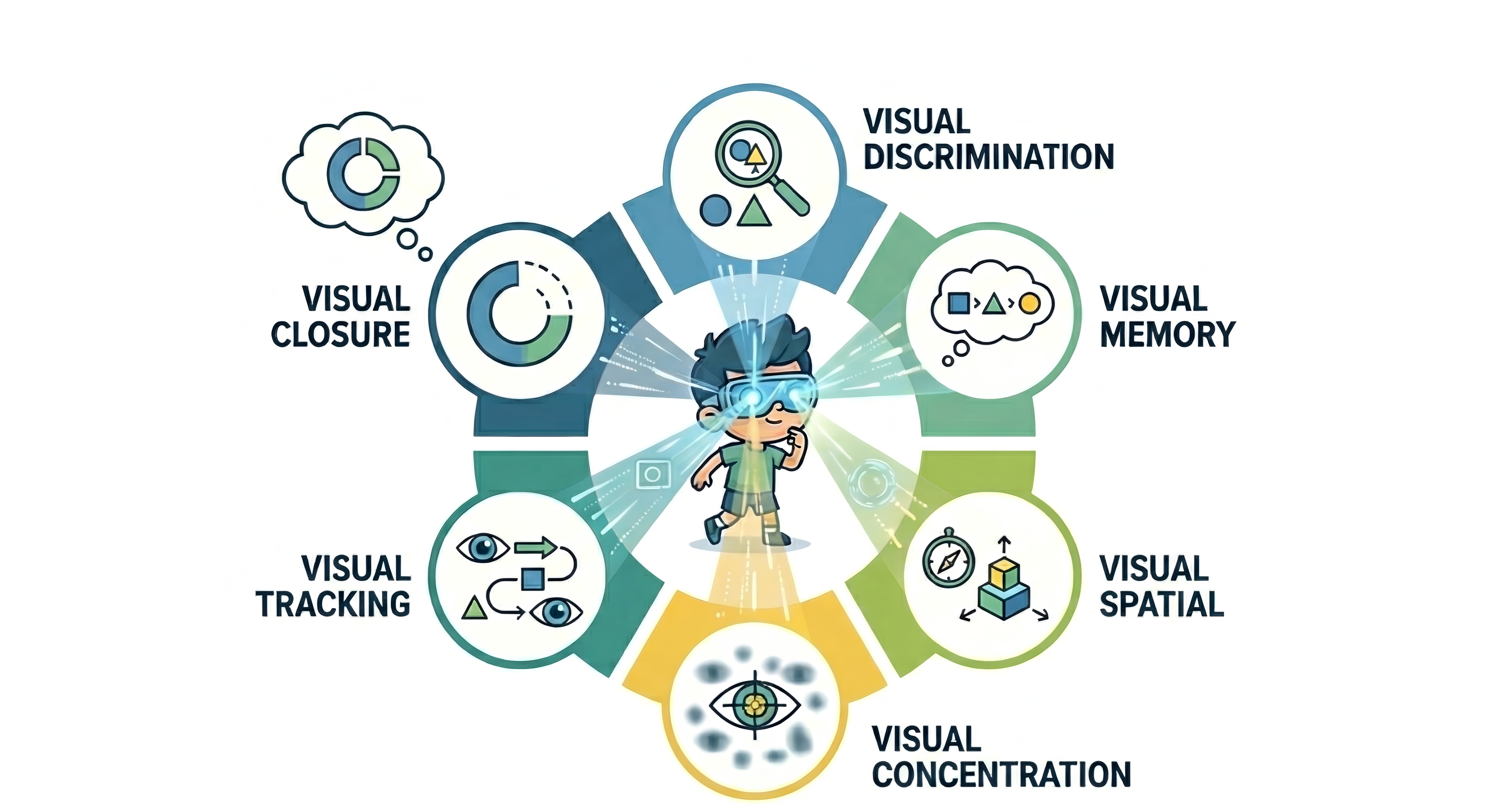
技术框架:KidVis基准包含六种原子视觉能力:专注力(Concentration)、追踪能力(Tracking)、辨别能力(Discrimination)、记忆力(Memory)、空间能力(Spatial)和闭合能力(Closure)。针对每种能力,设计了若干视觉任务,例如,追踪能力的任务包括追踪运动物体的轨迹,辨别能力的任务包括区分相似的图像。整个评估流程包括:1) 给定一个视觉任务;2) MLLM接收图像作为输入;3) MLLM输出答案;4) 将MLLM的答案与正确答案进行比较,计算得分。
关键创新:论文的关键创新在于提出了KidVis基准,该基准基于人类视觉发展理论,能够更全面、更客观地评估MLLMs的视觉感知能力。此外,论文还发现了“缩放定律悖论”,即简单地增加模型参数并不能线性地提高MLLMs的基础视觉能力。
关键设计:KidVis基准中的视觉任务设计尽量减少语义依赖,以确保评估的是MLLMs的纯粹视觉感知能力。例如,任务中的物体形状、颜色等都是随机生成的,避免MLLMs利用已有的知识进行作弊。此外,论文还采用了人类生理基线作为对比,以更客观地评估MLLMs的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,当前最先进的MLLM(GPT-5)在KidVis上的平均得分仅为67.33,远低于人类儿童的95.32。此外,研究还发现,简单地增加模型参数并不能线性地提高MLLMs的基础视觉能力,这表明需要更深入地研究MLLMs的视觉感知机制,并设计更有效的训练方法。
🎯 应用场景
该研究成果可应用于评估和改进多模态大语言模型的视觉感知能力,推动通用人工智能的发展。通过KidVis基准,可以更好地了解MLLMs的优势和不足,从而指导模型设计和训练,使其具备更强的视觉理解能力。此外,该研究还可以应用于机器人视觉、自动驾驶等领域,提高机器在复杂环境中的感知能力。
📄 摘要(原文)
While Multimodal Large Language Models (MLLMs) have demonstrated impressive proficiency in high-level reasoning tasks, such as complex diagrammatic interpretation, it remains an open question whether they possess the fundamental visual primitives comparable to human intuition. To investigate this, we introduce KidVis, a novel benchmark grounded in the theory of human visual development. KidVis deconstructs visual intelligence into six atomic capabilities - Concentration, Tracking, Discrimination, Memory, Spatial, and Closure - already possessed by 6-7 year old children, comprising 10 categories of low-semantic-dependent visual tasks. Evaluating 20 state-of-the-art MLLMs against a human physiological baseline reveals a stark performance disparity. Results indicate that while human children achieve a near-perfect average score of 95.32, the state-of-the-art GPT-5 attains only 67.33. Crucially, we observe a "Scaling Law Paradox": simply increasing model parameters fails to yield linear improvements in these foundational visual capabilities. This study confirms that current MLLMs, despite their reasoning prowess, lack the essential physiological perceptual primitives required for generalized visual intelligence.