HIPPO: Accelerating Video Large Language Models Inference via Holistic-aware Parallel Speculative Decoding
作者: Qitan Lv, Tianyu Liu, Wen Wu, Xuenan Xu, Bowen Zhou, Feng Wu, Chao Zhang
分类: cs.CV, cs.AI
发布日期: 2026-01-13
💡 一句话要点
HIPPO:通过整体感知并行推测解码加速视频大语言模型推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频大语言模型 推测解码 并行计算 视觉token剪枝 语义感知 推理加速
📋 核心要点
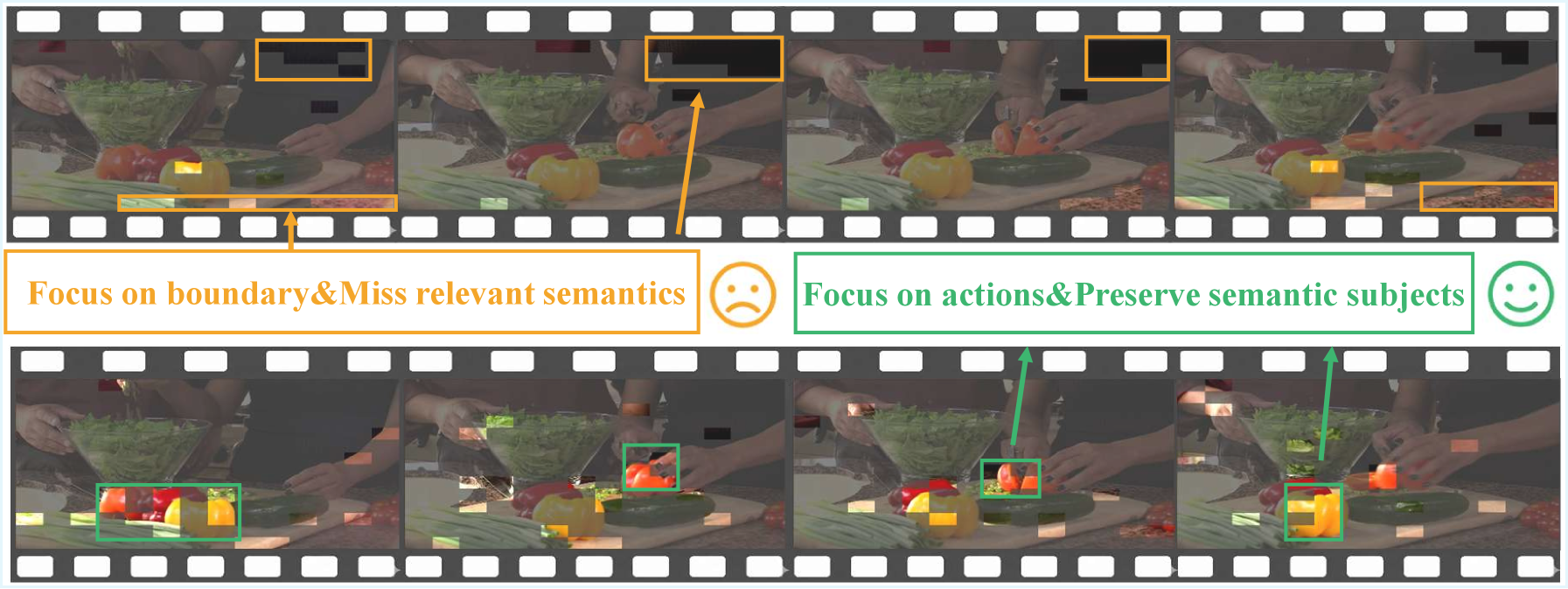
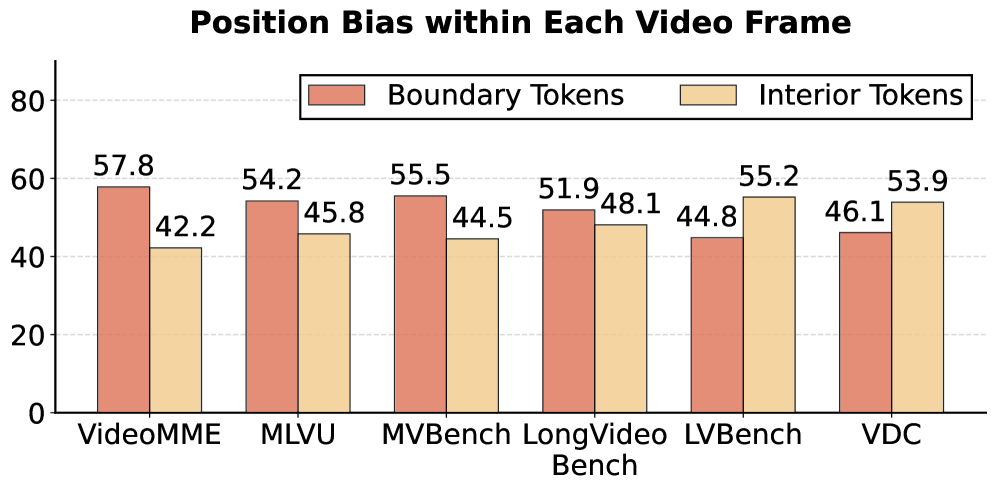
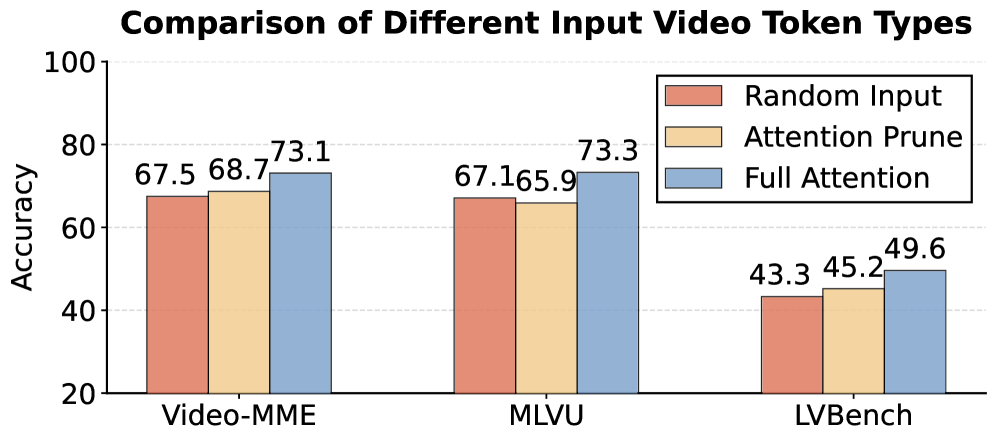
- 现有视频LLM的推测解码方法在视觉token修剪后,语义信息保留不足,导致草稿质量下降。
- HIPPO框架通过融合全局注意力与局部语义,实现语义感知的token保留,提升草稿质量。
- HIPPO采用视频并行推测解码算法,解耦草稿生成和目标验证,进一步提升推理速度,实验表明加速比可达3.51倍。
📝 摘要(中文)
推测解码(SD)已成为一种有前景的方法,可以在不牺牲输出质量的情况下加速LLM推理。现有的为视频LLM量身定制的SD方法主要集中在修剪冗余的视觉tokens,以减轻大量视觉输入的计算负担。然而,现有方法并没有实现与纯文本LLM相当的推理加速。我们从大量实验中观察到,这种现象主要源于两个限制:(i)它们的修剪策略未能充分保留视觉语义tokens,从而降低了草稿质量和接受率;(ii)即使采用激进的修剪(例如,移除90%的视觉tokens),草稿模型剩余的推理成本也限制了整体加速。为了解决这些限制,我们提出了HIPPO,一个通用的整体感知并行推测解码框架。具体来说,HIPPO提出了(i)一种语义感知的token保留方法,该方法融合了全局注意力分数和局部视觉语义,以在高修剪率下保留语义信息;(ii)一种视频并行SD算法,该算法解耦并重叠了草稿生成和目标验证阶段。在六个基准测试中对四个视频LLM进行的实验证明了HIPPO的有效性,与vanilla自回归解码相比,产生了高达3.51倍的加速。
🔬 方法详解
问题定义:现有视频大语言模型(Video-LLM)的推测解码方法,虽然通过剪枝冗余视觉tokens来降低计算量,但存在两个主要痛点:一是剪枝策略无法有效保留关键的视觉语义信息,导致生成的草稿质量不高,接受率低;二是即使进行了大幅度的剪枝,草稿模型的推理成本仍然较高,限制了整体的加速效果。
核心思路:HIPPO的核心思路是提出一种整体感知的并行推测解码框架,旨在解决现有方法在视觉token剪枝过程中语义信息丢失以及草稿模型推理成本过高的问题。通过语义感知的token保留方法,尽可能保留重要的视觉语义信息,提高草稿质量;同时,采用并行推测解码算法,将草稿生成和目标验证阶段解耦并重叠,从而进一步提升推理速度。
技术框架:HIPPO框架主要包含两个核心模块:语义感知的token保留模块和视频并行推测解码模块。语义感知的token保留模块负责在视觉token剪枝过程中,融合全局注意力分数和局部视觉语义信息,以保留重要的语义信息。视频并行推测解码模块则将草稿生成和目标验证阶段解耦,并采用并行计算的方式,从而提高推理速度。整体流程为:首先,对输入视频进行视觉特征提取;然后,利用语义感知的token保留模块进行视觉token剪枝;接着,利用草稿模型并行生成草稿;最后,利用目标模型并行验证草稿,并进行自回归解码。
关键创新:HIPPO的关键创新在于:(1) 提出了一种语义感知的token保留方法,该方法能够有效地保留视觉语义信息,提高草稿质量,从而提高接受率;(2) 提出了一种视频并行推测解码算法,该算法能够将草稿生成和目标验证阶段解耦并重叠,从而进一步提高推理速度。与现有方法相比,HIPPO能够在保证输出质量的前提下,显著提高视频LLM的推理速度。
关键设计:语义感知的token保留模块的关键设计在于融合全局注意力分数和局部视觉语义信息。具体来说,该模块首先计算每个视觉token的全局注意力分数,然后利用局部视觉语义信息对注意力分数进行加权,从而得到每个视觉token的重要性评分。根据重要性评分,选择保留最重要的视觉token。视频并行推测解码模块的关键设计在于将草稿生成和目标验证阶段解耦。具体来说,该模块首先利用草稿模型并行生成多个草稿,然后利用目标模型并行验证这些草稿。如果草稿被接受,则直接将草稿添加到输出序列中;否则,利用目标模型进行自回归解码。
🖼️ 关键图片
📊 实验亮点
HIPPO在六个基准测试中对四个视频LLM进行了评估,实验结果表明,与vanilla自回归解码相比,HIPPO能够实现高达3.51倍的加速。这表明HIPPO能够有效地提高视频LLM的推理速度,并且具有良好的泛化能力。
🎯 应用场景
HIPPO框架可广泛应用于各种需要快速视频理解和生成的场景,例如智能监控、自动驾驶、视频摘要、视频问答等。该研究成果能够显著提升视频LLM的推理效率,降低计算成本,使得视频LLM能够更好地应用于实际场景中,具有重要的实际价值和广阔的应用前景。
📄 摘要(原文)
Speculative decoding (SD) has emerged as a promising approach to accelerate LLM inference without sacrificing output quality. Existing SD methods tailored for video-LLMs primarily focus on pruning redundant visual tokens to mitigate the computational burden of massive visual inputs. However, existing methods do not achieve inference acceleration comparable to text-only LLMs. We observe from extensive experiments that this phenomenon mainly stems from two limitations: (i) their pruning strategies inadequately preserve visual semantic tokens, degrading draft quality and acceptance rates; (ii) even with aggressive pruning (e.g., 90% visual tokens removed), the draft model's remaining inference cost limits overall speedup. To address these limitations, we propose HIPPO, a general holistic-aware parallel speculative decoding framework. Specifically, HIPPO proposes (i) a semantic-aware token preservation method, which fuses global attention scores with local visual semantics to retain semantic information at high pruning ratios; (ii) a video parallel SD algorithm that decouples and overlaps draft generation and target verification phases. Experiments on four video-LLMs across six benchmarks demonstrate HIPPO's effectiveness, yielding up to 3.51x speedup compared to vanilla auto-regressive decoding.