Instruction-Driven 3D Facial Expression Generation and Transition
作者: Anh H. Vo, Tae-Seok Kim, Hulin Jin, Soo-Mi Choi, Yong-Guk Kim
分类: cs.CV, cs.AI, cs.GR, cs.LG, cs.MM
发布日期: 2026-01-13
期刊: IEEE Transactions on Multimedia, 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出指令驱动的3D面部表情生成与过渡框架,实现逼真表情模拟。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D人脸表情生成 指令驱动 多模态学习 表情过渡 人机交互
📋 核心要点
- 现有3D人脸表情通常仅限于六种基本表情,难以模拟真实情感的细微变化和表情间的自然过渡。
- 提出Instruction-driven Facial Expression Decomposer (IFED)和Instruction to Facial Expression Transition (I2FET)方法,利用文本指令驱动表情生成和过渡。
- 实验结果表明,该方法在CK+和CelebV-HQ数据集上优于现有方法,能够根据文本指令生成逼真的面部表情序列。
📝 摘要(中文)
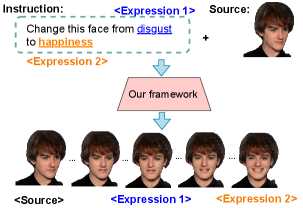
本研究提出了一种新的指令驱动的面部表情生成框架,该框架能够生成3D人脸,并根据指令将人脸表情从一种指定表情转换为另一种表情。该框架引入了指令驱动的面部表情分解器(IFED)模块,以促进多模态数据学习并捕获文本描述和面部表情特征之间的相关性。此外,提出了指令到面部表情过渡(I2FET)方法,该方法利用IFED和顶点重建损失函数来细化潜在向量的语义理解,从而根据给定的指令生成面部表情序列。最后,提出了面部表情过渡模型,以生成面部表情之间的平滑过渡。在CK+和CelebV-HQ数据集上的大量评估表明,所提出的模型优于最先进的方法。结果表明,该框架可以根据文本指令生成面部表情轨迹。考虑到文本提示允许我们对人类的情绪状态进行多样化的描述,面部表情的范围以及它们之间的过渡可以大大扩展。我们期望我们的框架能够找到各种实际应用。
🔬 方法详解
问题定义:现有3D人脸建模方法通常只关注静态表情的生成,缺乏对表情之间动态过渡的建模能力。此外,控制表情生成的方式有限,难以根据用户的意图进行灵活调整。因此,如何实现根据指令驱动的、平滑自然的3D面部表情生成与过渡是一个关键问题。
核心思路:论文的核心思路是利用文本指令作为桥梁,连接面部表情的语义信息和3D人脸的几何表示。通过学习文本指令与面部表情特征之间的对应关系,可以实现根据文本描述生成相应的3D面部表情,并控制表情之间的平滑过渡。
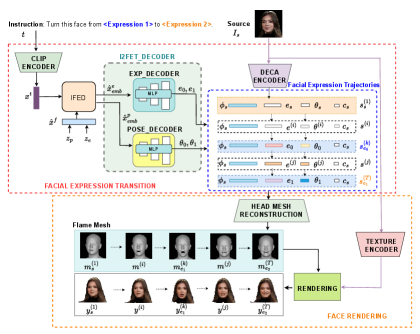
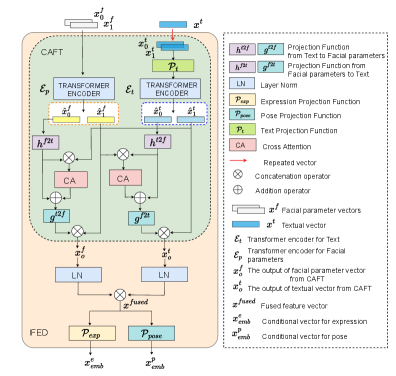
技术框架:整体框架包含两个主要模块:Instruction-driven Facial Expression Decomposer (IFED) 和 Instruction to Facial Expression Transition (I2FET)。IFED模块负责学习文本指令和面部表情特征之间的关联,将文本指令编码为潜在向量。I2FET模块则利用IFED的输出,结合顶点重建损失函数,生成与指令对应的面部表情序列。最后,使用一个面部表情过渡模型来平滑表情之间的过渡。
关键创新:该论文的关键创新在于提出了一个完整的指令驱动的3D面部表情生成与过渡框架。通过引入IFED模块,实现了多模态数据(文本和3D人脸)的有效融合,并学习了文本指令与面部表情特征之间的复杂关系。此外,I2FET模块利用顶点重建损失函数,进一步提升了生成表情的质量和真实感。
关键设计:IFED模块的具体实现细节未知,但推测可能使用了Transformer或类似的注意力机制来建模文本指令和面部表情特征之间的关系。I2FET模块的关键在于顶点重建损失函数的设计,该损失函数旨在保证生成的3D人脸的几何结构与目标表情一致。面部表情过渡模型可能采用了插值或生成对抗网络(GAN)等技术,以实现表情之间的平滑过渡。具体参数设置和网络结构细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在CK+和CelebV-HQ数据集上取得了优于现有方法的性能。具体提升幅度未知,但论文强调该框架能够根据文本指令生成更逼真、更自然的3D面部表情序列,并实现表情之间的平滑过渡。这些结果验证了该框架的有效性和优越性。
🎯 应用场景
该研究成果可应用于虚拟现实、游戏开发、人机交互等领域。例如,可以根据用户的语音或文本指令,实时生成具有丰富情感的3D虚拟形象,从而提升用户体验。此外,该技术还可以用于心理学研究,例如模拟不同情绪状态下的面部表情,以帮助人们更好地理解和识别情绪。
📄 摘要(原文)
A 3D avatar typically has one of six cardinal facial expressions. To simulate realistic emotional variation, we should be able to render a facial transition between two arbitrary expressions. This study presents a new framework for instruction-driven facial expression generation that produces a 3D face and, starting from an image of the face, transforms the facial expression from one designated facial expression to another. The Instruction-driven Facial Expression Decomposer (IFED) module is introduced to facilitate multimodal data learning and capture the correlation between textual descriptions and facial expression features. Subsequently, we propose the Instruction to Facial Expression Transition (I2FET) method, which leverages IFED and a vertex reconstruction loss function to refine the semantic comprehension of latent vectors, thus generating a facial expression sequence according to the given instruction. Lastly, we present the Facial Expression Transition model to generate smooth transitions between facial expressions. Extensive evaluation suggests that the proposed model outperforms state-of-the-art methods on the CK+ and CelebV-HQ datasets. The results show that our framework can generate facial expression trajectories according to text instruction. Considering that text prompts allow us to make diverse descriptions of human emotional states, the repertoire of facial expressions and the transitions between them can be expanded greatly. We expect our framework to find various practical applications More information about our project can be found at https://vohoanganh.github.io/tg3dfet/