Representation Learning with Semantic-aware Instance and Sparse Token Alignments
作者: Phuoc-Nguyen Bui, Toan Duc Nguyen, Junghyun Bum, Duc-Tai Le, Hyunseung Choo
分类: cs.CV
发布日期: 2026-01-13
备注: Under review, 8 pages
💡 一句话要点
提出SISTA框架,通过语义感知的实例和稀疏token对齐提升医学VLP表征学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 医学视觉语言预训练 对比学习 表征学习 语义对齐 多模态学习
📋 核心要点
- 医学VLP中,直接将未配对的图像-报告作为负例会引入假阴性,损害表征学习。
- SISTA框架通过引入报告相似性度量来减少假阴性,并进行图像patch和文本token的对齐。
- 实验表明,SISTA在图像分类、分割和检测任务上均有提升,尤其在小样本细粒度任务中表现突出。
📝 摘要(中文)
医学对比视觉-语言预训练(VLP)在提升下游任务性能方面展现出巨大潜力。传统方法通常采用对比学习,将配对的图像-报告样本视为正例,未配对的样本视为负例。然而,在医学数据集中,不同患者的图像或报告之间可能存在显著相似性。将所有未配对的样本都严格视为负例,可能会破坏潜在的语义结构,并对学习到的表征质量产生负面影响。本文提出了一种多层次对齐框架,即具有语义感知实例和稀疏token对齐的表征学习(SISTA),通过在图像-报告和patch-word两个层面上利用医学图像和放射报告之间的语义对应关系。具体来说,我们通过结合报告间的相似性来消除假阴性,从而改进了传统的对比学习,并引入了一种有效的方法来对齐图像patch和相关的word token。实验结果表明,所提出的框架在图像分类、图像分割和目标检测三个下游任务的不同数据集上,均能有效提高迁移性能。值得注意的是,即使在标记数据有限的情况下,我们的框架也能在细粒度任务中取得显著的改进。代码和预训练模型将会开源。
🔬 方法详解
问题定义:医学视觉-语言预训练(VLP)旨在学习医学图像和放射报告的联合表征。现有方法主要采用对比学习,将配对的图像-报告视为正例,未配对的视为负例。然而,医学数据集中存在大量语义相似的图像和报告,简单地将未配对样本视为负例会引入大量假阴性,导致学习到的表征质量下降。现有方法忽略了医学报告之间的语义相似性,以及图像局部区域与报告中特定词语之间的对应关系。
核心思路:SISTA框架的核心思路是利用医学图像和放射报告之间的多层次语义对应关系,减少假阴性样本的影响,并增强图像和文本之间的细粒度对齐。通过引入报告相似性度量,区分真正的负例和语义相似的样本,避免模型将相似样本错误地推开。同时,通过图像patch和文本token的对齐,学习更细粒度的图像-文本对应关系,提升模型对细微病灶的识别能力。
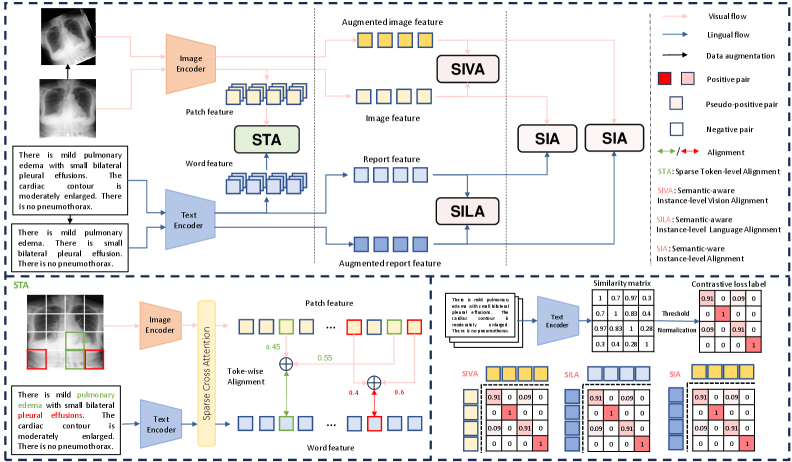
技术框架:SISTA框架包含以下几个主要模块:1) 图像编码器:用于提取医学图像的视觉特征。2) 文本编码器:用于提取放射报告的文本特征。3) 实例级对齐模块:利用报告相似性度量改进对比学习,减少假阴性样本的影响。4) Token级对齐模块:将图像划分为多个patch,并将报告中的文本划分为多个token,学习图像patch和文本token之间的对应关系。5) 损失函数:包括对比损失和token对齐损失,用于优化模型参数。
关键创新:SISTA框架的关键创新在于:1) 提出了语义感知的实例级对齐方法,通过引入报告相似性度量,减少了对比学习中的假阴性问题。2) 提出了稀疏token对齐方法,通过学习图像patch和文本token之间的对应关系,增强了图像和文本之间的细粒度对齐。3) 将实例级和token级对齐相结合,构建了一个多层次的对齐框架,能够更有效地学习医学图像和放射报告的联合表征。
关键设计:在实例级对齐中,使用余弦相似度计算报告之间的相似性,并根据相似度调整对比损失的权重。在token级对齐中,使用注意力机制学习图像patch和文本token之间的对应关系,并使用KL散度损失优化对齐结果。图像编码器可以使用预训练的ResNet或ViT模型,文本编码器可以使用预训练的BERT或BioBERT模型。损失函数采用对比损失和token对齐损失的加权和,权重系数需要根据实验结果进行调整。
🖼️ 关键图片
📊 实验亮点
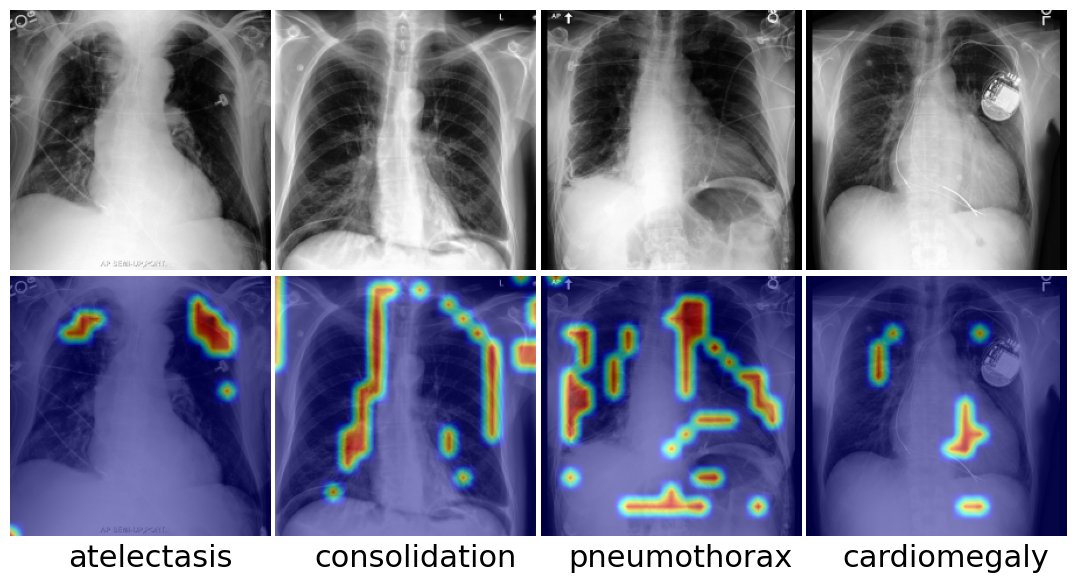
实验结果表明,SISTA框架在图像分类、图像分割和目标检测三个下游任务上均取得了显著的提升。例如,在图像分类任务中,SISTA框架相比于基线方法提升了3-5个百分点。在细粒度任务中,SISTA框架的提升更为显著,表明其能够更好地学习图像和文本之间的细粒度对应关系。即使在标记数据有限的情况下,SISTA框架也能取得较好的性能,表明其具有较强的泛化能力。
🎯 应用场景
SISTA框架可应用于多种医学影像分析任务,如疾病诊断、病灶定位、报告生成等。通过学习高质量的医学图像和放射报告联合表征,可以提升计算机辅助诊断系统的准确性和可靠性,辅助医生进行更快速、更准确的诊断,并有望在远程医疗、智能影像分析等领域发挥重要作用。
📄 摘要(原文)
Medical contrastive vision-language pre-training (VLP) has demonstrated significant potential in improving performance on downstream tasks. Traditional approaches typically employ contrastive learning, treating paired image-report samples as positives and unpaired ones as negatives. However, in medical datasets, there can be substantial similarities between images or reports from different patients. Rigidly treating all unpaired samples as negatives, can disrupt the underlying semantic structure and negatively impact the quality of the learned representations. In this paper, we propose a multi-level alignment framework, Representation Learning with Semantic-aware Instance and Sparse Token Alignments (SISTA) by exploiting the semantic correspondence between medical image and radiology reports at two levels, i.e., image-report and patch-word levels. Specifically, we improve the conventional contrastive learning by incorporating inter-report similarity to eliminate the false negatives and introduce a method to effectively align image patches with relevant word tokens. Experimental results demonstrate the effectiveness of the proposed framework in improving transfer performance across different datasets on three downstream tasks: image classification, image segmentation, and object detection. Notably, our framework achieves significant improvements in fine-grained tasks even with limited labeled data. Codes and pre-trained models will be made available.