Instance-Aligned Captions for Explainable Video Anomaly Detection
作者: Inpyo Song, Minjun Joo, Joonhyung Kwon, Eunji Jeon, Jangwon Lee
分类: cs.CV
发布日期: 2026-01-13
💡 一句话要点
提出实例对齐的视频异常检测字幕,增强可解释性和空间定位能力
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 视频异常检测 可解释性 空间定位 实例对齐 字幕生成
📋 核心要点
- 现有可解释视频异常检测方法缺乏空间定位能力,难以验证,尤其在多实体交互场景下表现不佳。
- 提出实例对齐的字幕,将文本描述与特定对象实例关联,捕捉异常事件中的“谁”、“什么”、“影响谁”和“在哪里”。
- 构建了VIEW360+数据集,包含更多场景和异常类型,实验表明现有方法存在局限性,并为未来研究提供基准。
📝 摘要(中文)
可解释的视频异常检测(VAD)对于安全关键应用至关重要,但现有研究在空间定位方面存在不足,导致解释难以验证。尤其是在多实体交互中,现有方法生成的描述不完整或视觉上错位,降低了可信度。为了解决这些问题,我们引入了实例对齐的字幕,将每个文本声明与具有外观和运动属性的特定对象实例相关联。我们的框架能够捕捉谁导致了异常,每个实体在做什么,影响了谁,以及解释的空间位置,从而实现可验证和可操作的推理。我们标注了八个广泛使用的VAD基准,并通过增加868个视频、八个地点和四种新的异常类型来扩展360度自我中心数据集VIEW360,创建了VIEW360+,这是一个用于可解释VAD的综合测试平台。实验表明,我们的实例级空间定位字幕揭示了当前基于LLM和VLM的方法的局限性,并为未来可信和可解释的异常检测研究提供了强大的基准。
🔬 方法详解
问题定义:现有可解释视频异常检测方法生成的解释缺乏空间定位,难以验证,尤其是在涉及多个实体交互的复杂场景中。现有方法通常产生不完整或视觉上错位的描述,降低了其可信度。因此,需要一种能够提供更精确、可验证的异常解释的方法。
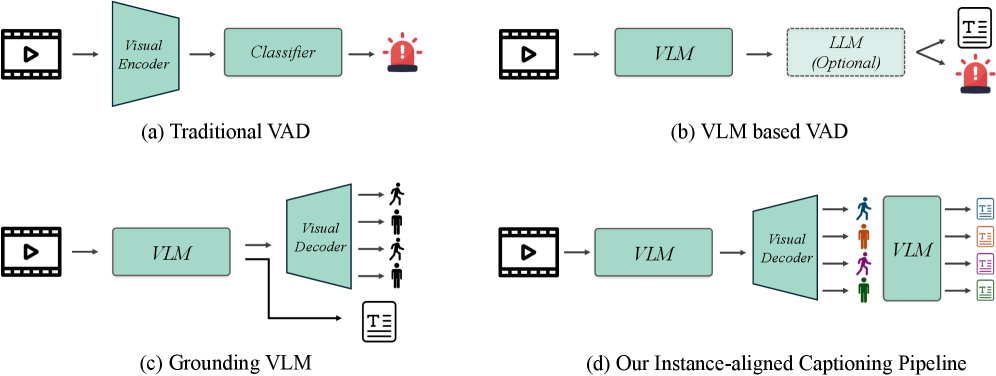
核心思路:论文的核心思路是将文本描述与视频中的特定对象实例对齐,从而提供空间定位的解释。通过捕捉异常事件中涉及的实体及其行为,以及这些行为的影响对象和发生位置,可以实现更可信和可操作的异常检测。
技术框架:该框架的核心是生成实例对齐的字幕,这些字幕将文本描述与视频中的特定对象实例相关联。具体流程可能包括:1) 对象检测与跟踪,识别视频中的实体;2) 行为识别,分析每个实体的动作;3) 关系推理,确定实体之间的交互关系;4) 字幕生成,将上述信息整合为自然语言描述,并与相应的对象实例对齐。
关键创新:最重要的创新点在于实例对齐的字幕,它将文本解释与视频中的特定对象实例联系起来,从而提供了空间定位的解释。这种方法与现有方法的主要区别在于,它不仅提供了异常的描述,还提供了异常发生的位置和涉及的实体,从而增强了可解释性和可验证性。
关键设计:论文的关键设计包括:1) 设计合适的字幕模板,能够清晰地描述异常事件中的“谁”、“什么”、“影响谁”和“在哪里”;2) 开发或利用现有的对象检测、跟踪和行为识别算法,提取必要的视觉信息;3) 设计合适的损失函数,鼓励字幕与对象实例之间的对齐;4) 构建大规模数据集VIEW360+,用于训练和评估模型。
🖼️ 关键图片


📊 实验亮点
论文构建了VIEW360+数据集,包含更多场景和异常类型,为可解释视频异常检测研究提供了新的基准。实验表明,现有基于LLM和VLM的方法在实例对齐和空间定位方面存在局限性,突显了该研究的价值。该研究为未来可信和可解释的异常检测研究奠定了基础。
🎯 应用场景
该研究成果可应用于智能监控、自动驾驶、机器人安全等领域。通过提供可解释的异常检测结果,可以帮助安全人员快速定位问题,采取有效措施,提高系统的安全性和可靠性。未来,该技术有望应用于更广泛的场景,例如医疗诊断、工业质检等。
📄 摘要(原文)
Explainable video anomaly detection (VAD) is crucial for safety-critical applications, yet even with recent progress, much of the research still lacks spatial grounding, making the explanations unverifiable. This limitation is especially pronounced in multi-entity interactions, where existing explainable VAD methods often produce incomplete or visually misaligned descriptions, reducing their trustworthiness. To address these challenges, we introduce instance-aligned captions that link each textual claim to specific object instances with appearance and motion attributes. Our framework captures who caused the anomaly, what each entity was doing, whom it affected, and where the explanationis grounded, enabling verifiable and actionable reasoning. We annotate eight widely used VAD benchmarks and extend the 360-degree egocentric dataset, VIEW360, with 868 additional videos, eight locations, and four new anomaly types, creating VIEW360+, a comprehensive testbed for explainable VAD. Experiments show that our instance-level spatially grounded captions reveal significant limitations in current LLM- and VLM-based methods while providing a robust benchmark for future research in trustworthy and interpretable anomaly detection.