How Do Optical Flow and Textual Prompts Collaborate to Assist in Audio-Visual Semantic Segmentation?
作者: Peng Gao, Yujian Lee, Yongqi Xu, Wentao Fan
分类: cs.CV, cs.AI
发布日期: 2026-01-13
💡 一句话要点
提出SSP框架,融合光流与文本提示,提升音视频语义分割精度
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 音视频语义分割 光流 文本提示 跨模态融合 视觉-文本对齐
📋 核心要点
- 现有音视频语义分割方法缺乏对运动信息和场景语义的有效利用,导致分割精度受限。
- SSP框架通过光流捕获运动信息,并结合文本提示提供场景语义,从而辅助分割过程。
- 实验结果表明,SSP在音视频语义分割任务上优于现有方法,实现了性能提升。
📝 摘要(中文)
音视频语义分割(AVSS)是音视频分割(AVS)任务的扩展,它不仅需要在视觉像素级别识别发声物体,还需要对音视频场景进行语义理解。本文提出一种新颖的协作框架——Stepping Stone Plus (SSP),它将AVSS任务分解为两个离散的子任务,首先提供一个提示分割掩码,以促进后续的语义分析。SSP集成了光流和文本提示来辅助分割过程。在声音源经常与移动物体共存的场景中,SSP利用光流捕获运动动态,为精确分割提供重要的时间上下文。针对静态发声物体(如闹钟)的挑战,SSP结合了两个特定的文本提示:一个识别发声物体的类别,另一个提供更广泛的场景描述。此外,我们实现了一个视觉-文本对齐模块(VTA)来促进跨模态融合,从而提供更连贯和上下文相关的语义解释。我们的训练方案涉及一种后掩码技术,旨在迫使模型学习光流图。实验结果表明,SSP优于现有的AVS方法,提供了高效和精确的分割结果。
🔬 方法详解
问题定义:音视频语义分割(AVSS)旨在识别图像中与声音相关的像素,并赋予其语义标签。现有方法在处理复杂场景,特别是当声音源与运动物体共存或声音源静止时,分割精度较低。痛点在于如何有效融合视觉、听觉信息,并充分利用场景的上下文信息,从而提升分割的准确性和鲁棒性。
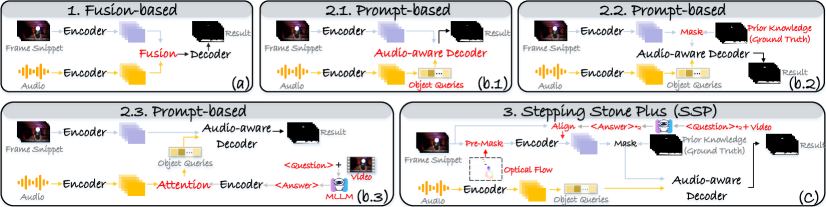
核心思路:本文的核心思路是将AVSS任务分解为两个阶段:首先,利用光流和文本提示生成一个初步的分割掩码;然后,基于该掩码进行语义分析,得到最终的分割结果。这种分解策略能够有效利用运动信息和场景语义,从而提升分割精度。
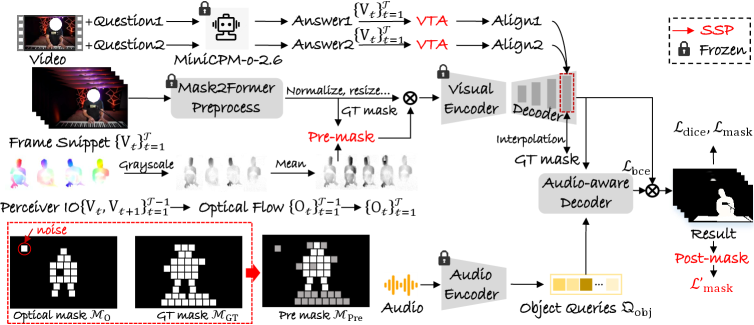
技术框架:SSP框架包含以下主要模块:1) 光流模块:用于捕获图像中的运动信息。2) 文本提示模块:接收两种文本提示,分别描述声音源的类别和场景的整体描述。3) 视觉-文本对齐模块(VTA):用于融合视觉特征和文本特征,从而实现跨模态信息的有效交互。4) 分割模块:基于融合后的特征生成分割掩码。训练过程采用后掩码技术,迫使模型学习光流图。
关键创新:SSP的关键创新在于:1) 提出了一种基于光流和文本提示的预分割掩码生成方法,能够有效利用运动信息和场景语义。2) 引入了视觉-文本对齐模块(VTA),实现了跨模态信息的有效融合。3) 采用后掩码训练技术,提升了模型对光流信息的利用能力。与现有方法相比,SSP能够更准确地分割出与声音相关的像素,并赋予其正确的语义标签。
关键设计:光流模块采用成熟的光流估计算法,如RAFT。文本提示模块使用预训练的文本编码器,如BERT,将文本转换为向量表示。VTA模块采用Transformer结构,实现视觉特征和文本特征的对齐。损失函数包括分割损失和对齐损失,用于优化分割性能和跨模态对齐效果。后掩码训练技术通过在训练过程中引入噪声掩码,迫使模型学习光流图的特征。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SSP框架在音视频语义分割任务上取得了显著的性能提升,优于现有的AVS方法。具体而言,SSP在多个数据集上实现了更高的分割精度和更低的错误率,证明了其有效性和优越性。性能提升主要归功于光流信息和文本提示的有效融合,以及视觉-文本对齐模块的跨模态信息交互能力。
🎯 应用场景
该研究成果可应用于智能监控、自动驾驶、机器人导航等领域。例如,在智能监控中,可以利用音视频语义分割技术识别异常声音事件,并定位相关物体。在自动驾驶中,可以帮助车辆理解周围环境,识别潜在的危险因素。在机器人导航中,可以使机器人更好地感知环境,并做出合理的决策。
📄 摘要(原文)
Audio-visual semantic segmentation (AVSS) represents an extension of the audio-visual segmentation (AVS) task, necessitating a semantic understanding of audio-visual scenes beyond merely identifying sound-emitting objects at the visual pixel level. Contrary to a previous methodology, by decomposing the AVSS task into two discrete subtasks by initially providing a prompted segmentation mask to facilitate subsequent semantic analysis, our approach innovates on this foundational strategy. We introduce a novel collaborative framework, \textit{S}tepping \textit{S}tone \textit{P}lus (SSP), which integrates optical flow and textual prompts to assist the segmentation process. In scenarios where sound sources frequently coexist with moving objects, our pre-mask technique leverages optical flow to capture motion dynamics, providing essential temporal context for precise segmentation. To address the challenge posed by stationary sound-emitting objects, such as alarm clocks, SSP incorporates two specific textual prompts: one identifies the category of the sound-emitting object, and the other provides a broader description of the scene. Additionally, we implement a visual-textual alignment module (VTA) to facilitate cross-modal integration, delivering more coherent and contextually relevant semantic interpretations. Our training regimen involves a post-mask technique aimed at compelling the model to learn the diagram of the optical flow. Experimental results demonstrate that SSP outperforms existing AVS methods, delivering efficient and precise segmentation results.