Beyond External Guidance: Unleashing the Semantic Richness Inside Diffusion Transformers for Improved Training
作者: Lingchen Sun, Rongyuan Wu, Zhengqiang Zhang, Ruibin Li, Yujing Sun, Shuaizheng Liu, Lei Zhang
分类: cs.CV
发布日期: 2026-01-12
🔗 代码/项目: GITHUB
💡 一句话要点
提出Self-Transcendence方法,仅用内部特征监督加速Diffusion Transformer训练,无需外部指导。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 扩散模型 Diffusion Transformer 自监督学习 内部特征监督 图像生成
📋 核心要点
- 现有DiT训练依赖外部语义特征指导,引入额外依赖,限制了灵活性。
- 提出Self-Transcendence方法,利用DiT自身学习的内部特征进行监督,加速训练。
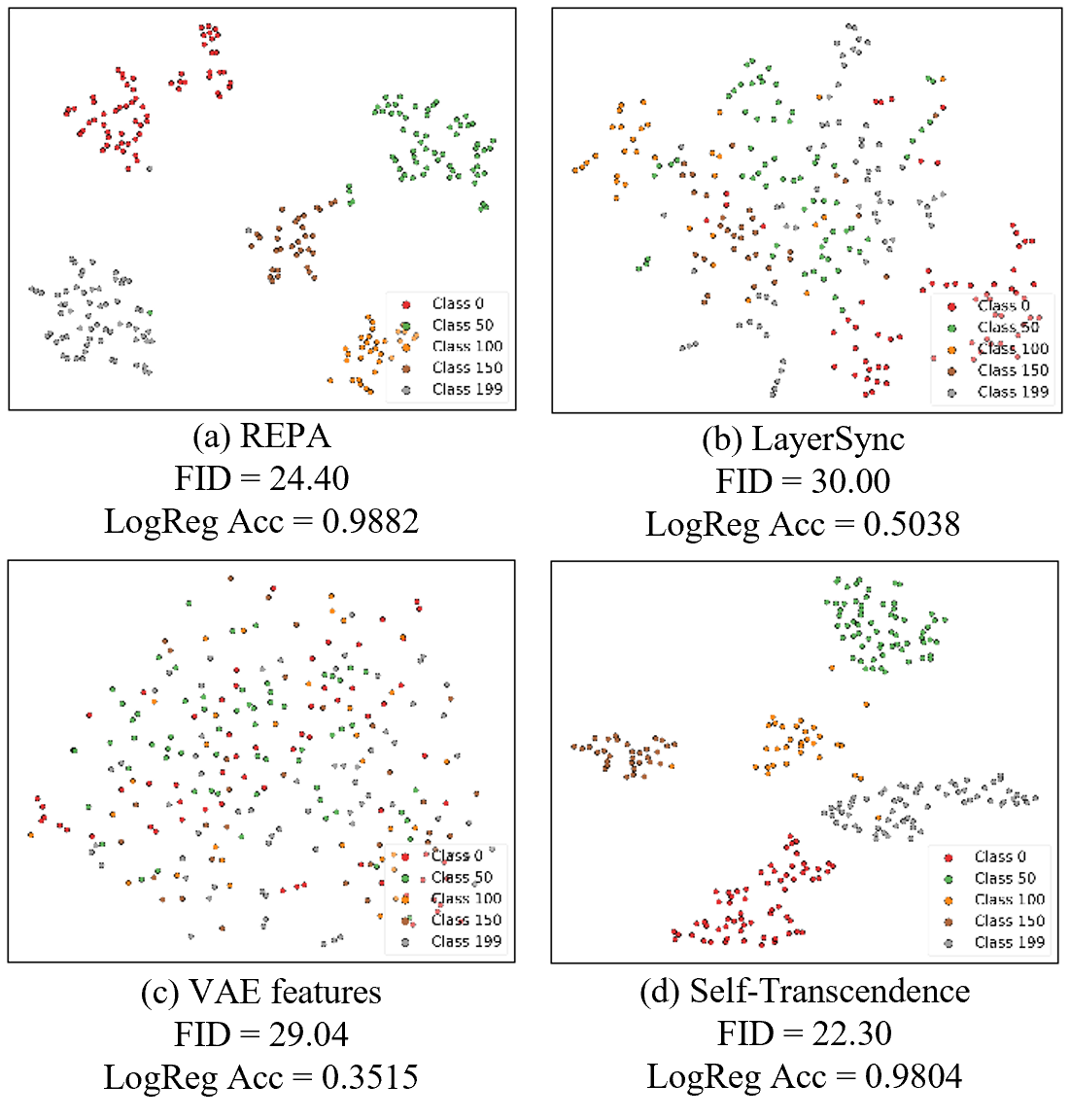
- 实验表明,该方法在生成质量和收敛速度上超越现有自包含方法,甚至优于REPA。
📝 摘要(中文)
REPA等工作表明,使用外部语义特征(如DINO)指导扩散模型可以显著加速Diffusion Transformer (DiT) 的训练。然而,这需要使用预训练的外部网络,引入了额外的依赖并降低了灵活性。本文提出Self-Transcendence,一种简单而有效的方法,仅使用内部特征监督即可实现快速收敛。研究发现,DiT训练中收敛缓慢的主要原因是浅层表示学习的困难。为了解决这个问题,首先通过将DiT模型的浅层特征与预训练VAE的潜在表示对齐进行短时训练(如40个epoch),然后应用无分类器指导来增强中间特征的判别能力和语义表达能力。这些完全在模型内部学习到的丰富的内部特征被用作监督信号,以指导新的DiT训练。与现有的自包含方法相比,该方法带来了显著的性能提升,甚至在生成质量和收敛速度方面超过了REPA,且不需要任何外部预训练模型。该方法不仅对不同的骨干网络更具灵活性,而且有可能被用于更广泛的基于扩散的生成任务。
🔬 方法详解
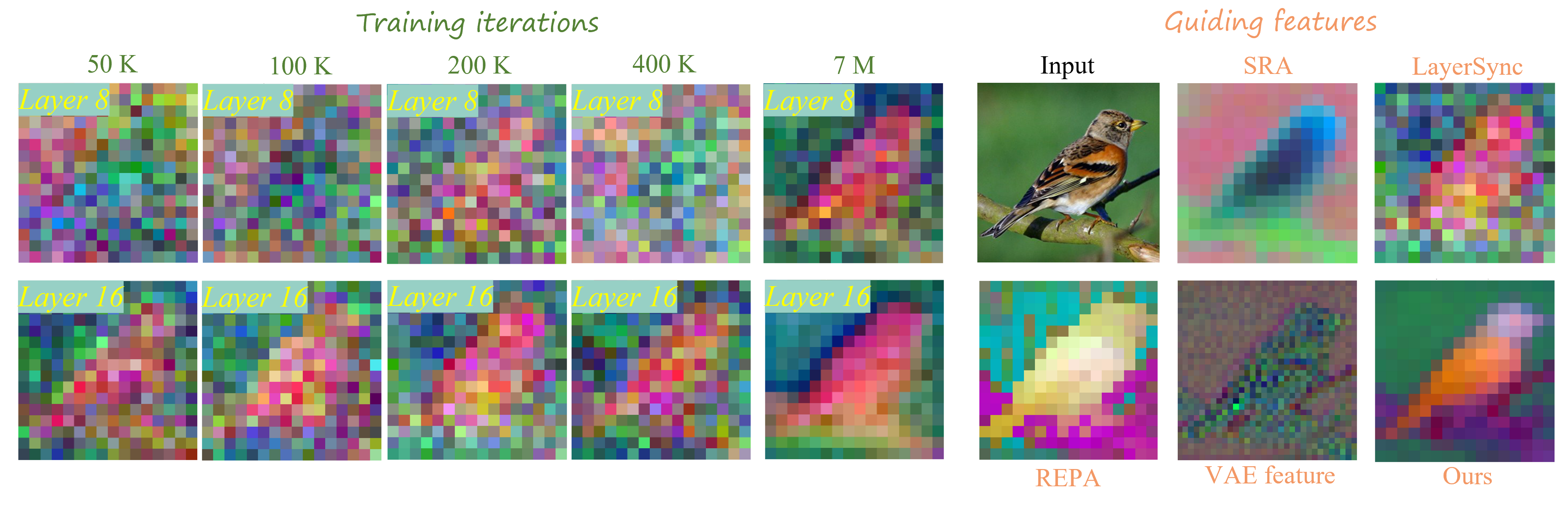
问题定义:论文旨在解决Diffusion Transformer (DiT) 训练过程中收敛速度慢的问题。现有方法,如REPA,依赖于外部预训练模型提取的语义特征来指导DiT的训练,这引入了额外的依赖,限制了模型的灵活性和泛化能力。此外,浅层网络的表示学习能力不足是导致收敛缓慢的关键因素。
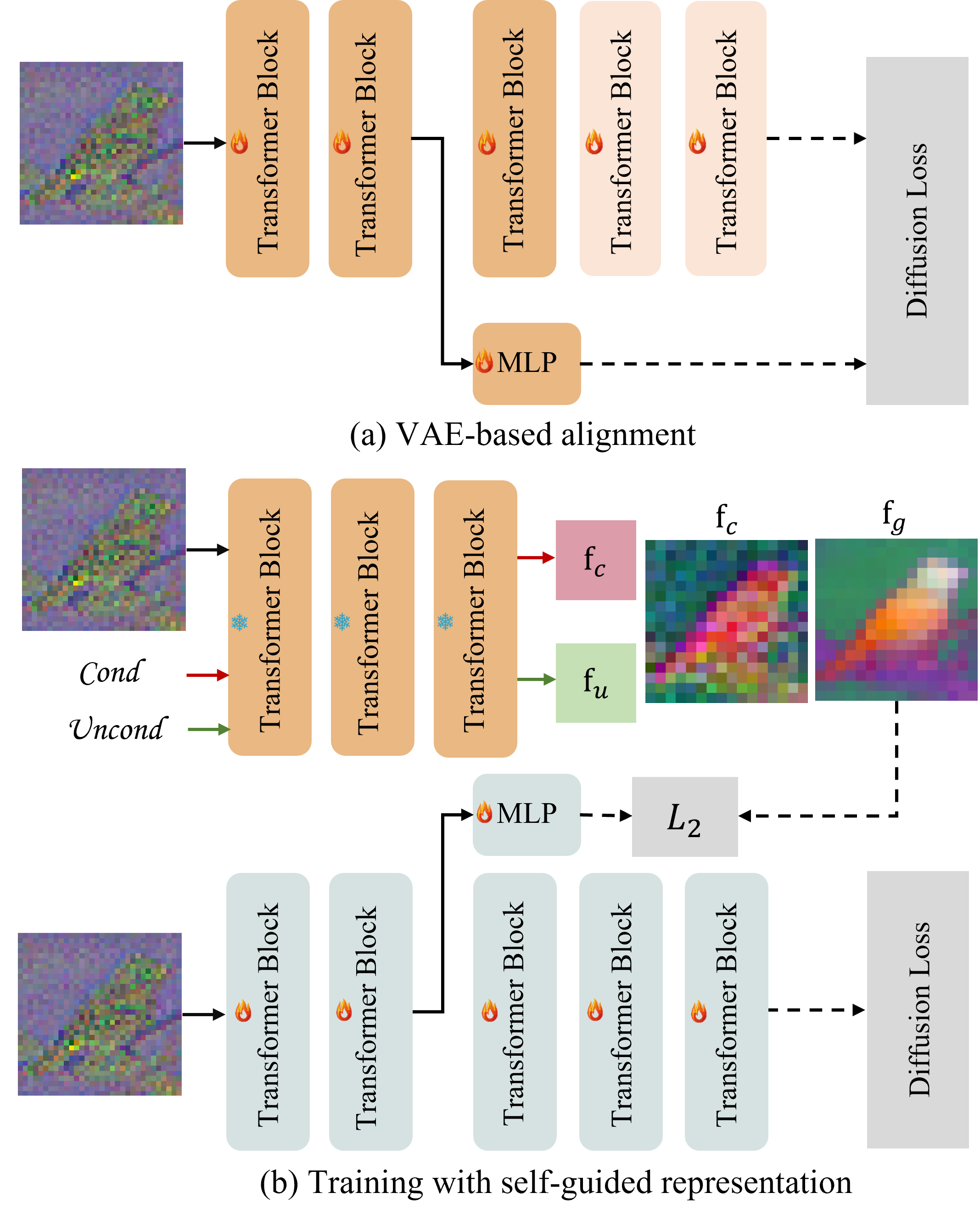
核心思路:论文的核心思路是利用DiT自身学习到的内部特征来指导其训练,从而避免对外部信息的依赖。通过增强DiT中间层的特征表达能力,并将其作为监督信号,可以有效地提升DiT的训练效率和生成质量。这种自监督的方式能够更好地挖掘DiT内部的语义信息,实现更快的收敛和更好的性能。
技术框架:Self-Transcendence方法包含两个主要阶段:1) 浅层特征对齐阶段:首先,使用预训练的VAE的潜在表示来监督DiT浅层网络的训练,使其具备初步的语义表达能力。2) 内部特征监督阶段:然后,应用classifier-free guidance增强DiT中间层特征的判别性和语义表达能力,并将这些增强后的内部特征作为监督信号,用于指导新一轮的DiT训练。整个过程无需任何外部预训练模型。
关键创新:该方法最重要的创新点在于提出了完全基于内部特征监督的DiT训练方法。与依赖外部信息的现有方法不同,Self-Transcendence能够充分利用DiT自身学习到的特征,实现更高效、更灵活的训练。通过增强中间层特征的表达能力,并将其作为监督信号,可以有效地提升DiT的生成质量和收敛速度。
关键设计:在浅层特征对齐阶段,使用MSE损失函数来衡量DiT浅层特征与VAE潜在表示之间的差异。在内部特征监督阶段,使用classifier-free guidance来增强中间层特征的判别能力,具体实现方式与标准classifier-free guidance一致。训练epoch数,浅层对齐epoch数,中间层特征选择等超参数需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Self-Transcendence方法在生成质量和收敛速度方面均优于现有的自包含方法,甚至超越了依赖外部指导的REPA。在相同的训练条件下,Self-Transcendence能够更快地达到更高的FID分数,证明了其在DiT训练方面的有效性。具体性能数据需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于图像生成、视频生成等领域,尤其适用于对模型灵活性和训练效率有较高要求的场景。无需依赖外部预训练模型,降低了部署成本和复杂度,为扩散模型在资源受限环境下的应用提供了可能。未来可进一步探索其在其他生成任务中的潜力,例如文本生成、音频生成等。
📄 摘要(原文)
Recent works such as REPA have shown that guiding diffusion models with external semantic features (e.g., DINO) can significantly accelerate the training of diffusion transformers (DiTs). However, this requires the use of pretrained external networks, introducing additional dependencies and reducing flexibility. In this work, we argue that DiTs actually have the power to guide the training of themselves, and propose \textbf{Self-Transcendence}, a simple yet effective method that achieves fast convergence using internal feature supervision only. It is found that the slow convergence in DiT training primarily stems from the difficulty of representation learning in shallow layers. To address this, we initially train the DiT model by aligning its shallow features with the latent representations from the pretrained VAE for a short phase (e.g., 40 epochs), then apply classifier-free guidance to the intermediate features, enhancing their discriminative capability and semantic expressiveness. These enriched internal features, learned entirely within the model, are used as supervision signals to guide a new DiT training. Compared to existing self-contained methods, our approach brings a significant performance boost. It can even surpass REPA in terms of generation quality and convergence speed, but without the need for any external pretrained models. Our method is not only more flexible for different backbones but also has the potential to be adopted for a wider range of diffusion-based generative tasks. The source code of our method can be found at https://github.com/csslc/Self-Transcendence.