PARL: Position-Aware Relation Learning Network for Document Layout Analysis
作者: Fuyuan Liu, Dianyu Yu, He Ren, Nayu Liu, Xiaomian Kang, Delai Qiu, Fa Zhang, Genpeng Zhen, Shengping Liu, Jiaen Liang, Wei Huang, Yining Wang, Junnan Zhu
分类: cs.CV
发布日期: 2026-01-12
💡 一句话要点
提出PARL:一种位置感知关系学习网络,用于提升文档布局分析性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文档布局分析 纯视觉方法 位置感知 关系学习 图神经网络
📋 核心要点
- 现有文档布局分析方法依赖OCR,导致错误传播和计算开销大,限制了鲁棒性和实用性。
- PARL通过位置敏感性和关系结构建模文档布局,无需OCR,仅依赖视觉信息。
- PARL在DocLayNet上建立了新的纯视觉基准,并在M6Doc上超越了强大的多模态模型,参数量更少。
📝 摘要(中文)
文档布局分析旨在检测和分类扫描或数字文档中的结构元素(例如,标题、表格、图形)。现有方法通常依赖于高质量的光学字符识别(OCR)来融合视觉特征与提取的文本。这种依赖性引入了两个主要缺点:文本识别错误的传播和大量的计算开销,限制了多模态方法的鲁棒性和实际应用性。与流行的多模态趋势相反,我们认为有效的布局分析并不依赖于文本-视觉融合,而是依赖于对文档内在视觉结构的深刻理解。为此,我们提出了一种新的无OCR、纯视觉框架PARL(位置感知关系学习网络),该框架通过位置敏感性和关系结构来建模布局。具体来说,我们首先引入一个双向空间位置引导的可变形注意力模块,将布局元素之间的显式位置依赖性直接嵌入到视觉特征中。其次,我们设计了一个图细化分类器(GRC),通过动态构建的布局图来建模上下文关系,从而细化预测。大量实验表明,PARL取得了最先进的结果。它在DocLayNet上为纯视觉方法建立了一个新的基准,并且值得注意的是,在M6Doc上甚至超过了强大的多模态模型。至关重要的是,PARL(65M)非常高效,使用的参数大约是大型多模态模型(256M)的四分之一,这表明复杂的视觉结构建模可以比多模态融合更有效和更鲁棒。
🔬 方法详解
问题定义:文档布局分析旨在识别文档中的结构元素,如标题、表格和图像。现有方法依赖OCR提取文本信息,并与视觉特征融合。然而,OCR的错误会传递到布局分析中,且OCR本身计算开销大,影响效率和准确性。
核心思路:论文的核心在于摆脱对OCR的依赖,仅通过视觉信息理解文档布局。核心思想是文档的布局本身蕴含丰富的位置和关系信息,通过建模这些信息可以有效进行布局分析。因此,论文着重于设计能够捕捉位置依赖和关系结构的模块。
技术框架:PARL的整体框架包含以下几个主要模块:1) 特征提取网络(backbone,具体网络结构未知);2) 双向空间位置引导的可变形注意力模块(Bidirectional Spatial Position-Guided Deformable Attention module),用于嵌入位置依赖;3) 图细化分类器(Graph Refinement Classifier, GRC),用于建模上下文关系并细化预测。框架首先提取视觉特征,然后通过位置引导的注意力机制增强特征,最后利用图神经网络进行关系建模和分类。
关键创新:PARL的关键创新在于其纯视觉的布局分析方法,以及针对性地设计了位置感知和关系学习模块。与现有方法的本质区别在于,PARL避免了OCR带来的错误和计算开销,直接从视觉角度理解文档布局。
关键设计:双向空间位置引导的可变形注意力模块的具体实现细节未知,但其核心在于利用可变形卷积和位置编码,使网络能够自适应地关注不同位置的特征,并学习位置之间的依赖关系。图细化分类器(GRC)通过动态构建布局图,利用图神经网络建模元素之间的关系,从而细化分类结果。损失函数和具体的网络参数设置未知。
🖼️ 关键图片


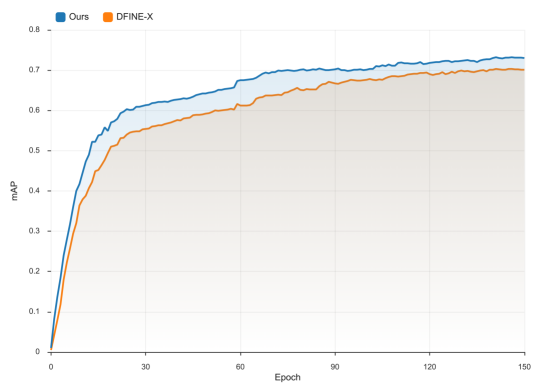
📊 实验亮点
PARL在DocLayNet数据集上取得了state-of-the-art的纯视觉方法结果,并在M6Doc数据集上超越了强大的多模态模型。PARL模型参数量仅为65M,远小于多模态模型(256M),证明了其高效性。这些实验结果表明,通过精巧的视觉结构建模,可以实现比多模态融合更优的文档布局分析性能。
🎯 应用场景
PARL可应用于自动化文档处理、信息提取、数字图书馆建设等领域。通过高效准确地分析文档布局,可以提升文档检索、内容理解和信息管理的效率。该研究为OCR受限或不可用的场景提供了有效的解决方案,具有广泛的应用前景。
📄 摘要(原文)
Document layout analysis aims to detect and categorize structural elements (e.g., titles, tables, figures) in scanned or digital documents. Popular methods often rely on high-quality Optical Character Recognition (OCR) to merge visual features with extracted text. This dependency introduces two major drawbacks: propagation of text recognition errors and substantial computational overhead, limiting the robustness and practical applicability of multimodal approaches. In contrast to the prevailing multimodal trend, we argue that effective layout analysis depends not on text-visual fusion, but on a deep understanding of documents' intrinsic visual structure. To this end, we propose PARL (Position-Aware Relation Learning Network), a novel OCR-free, vision-only framework that models layout through positional sensitivity and relational structure. Specifically, we first introduce a Bidirectional Spatial Position-Guided Deformable Attention module to embed explicit positional dependencies among layout elements directly into visual features. Second, we design a Graph Refinement Classifier (GRC) to refine predictions by modeling contextual relationships through a dynamically constructed layout graph. Extensive experiments show PARL achieves state-of-the-art results. It establishes a new benchmark for vision-only methods on DocLayNet and, notably, surpasses even strong multimodal models on M6Doc. Crucially, PARL (65M) is highly efficient, using roughly four times fewer parameters than large multimodal models (256M), demonstrating that sophisticated visual structure modeling can be both more efficient and robust than multimodal fusion.