A Multimodal Dataset of Student Oral Presentations with Sensors and Evaluation Data
作者: Alvaro Becerra, Ruth Cobos, Roberto Daza
分类: cs.HC, cs.CV
发布日期: 2026-01-12
备注: Article under review in the journal Scientific Data. GitHub repository of the dataset at: https://github.com/dataGHIA/SOPHIAS
💡 一句话要点
SOPHIAS:一个用于口头报告评估的多模态数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 口头报告评估 教育数据挖掘 传感器数据 行为分析
📋 核心要点
- 现有口头报告评估数据集缺乏多模态信息,难以全面捕捉学生表现和行为。
- SOPHIAS数据集同步记录多种传感器数据,包括音视频、眼动、生理信号和交互行为,提供更丰富的评估维度。
- 该数据集包含教师、同伴和自我评估,以及上下文标注,可用于开发自动反馈和多模态学习分析工具。
📝 摘要(中文)
本文提出了SOPHIAS,一个包含12小时的多模态数据集,用于研究学生的口头报告表现。该数据集包含来自马德里自治大学65名本科生和硕士生进行的50次口头报告(10-15分钟的报告和5-15分钟的问答环节)的记录。SOPHIAS集成了来自高清网络摄像头、环境和摄像头音频、眼动追踪眼镜、智能手表生理传感器以及点击器、键盘和鼠标交互的八个同步传感器流。此外,该数据集还包括幻灯片、教师、同伴和自我评估的基于评分标准的评估,以及带时间戳的上下文注释。该数据集捕捉了真实课堂环境中的演示,保留了真实的学生行为、互动和生理反应。SOPHIAS支持探索多模态行为和生理信号与演示表现之间的关系,支持同伴评估研究,并为开发自动反馈和多模态学习分析工具提供基准。该数据集通过GitHub和Science Data Bank公开提供研究使用。
🔬 方法详解
问题定义:目前缺乏包含多模态信息的学生口头报告数据集,这限制了对学生表现的全面分析和自动评估工具的开发。现有的数据集通常只关注音视频信息,忽略了学生的生理反应、眼动行为和交互行为等重要信息。
核心思路:本文的核心思路是通过同步记录多种传感器数据,构建一个包含丰富多模态信息的学生口头报告数据集。通过分析这些多模态数据,可以更全面地了解学生的表现,并开发更有效的自动评估和反馈工具。
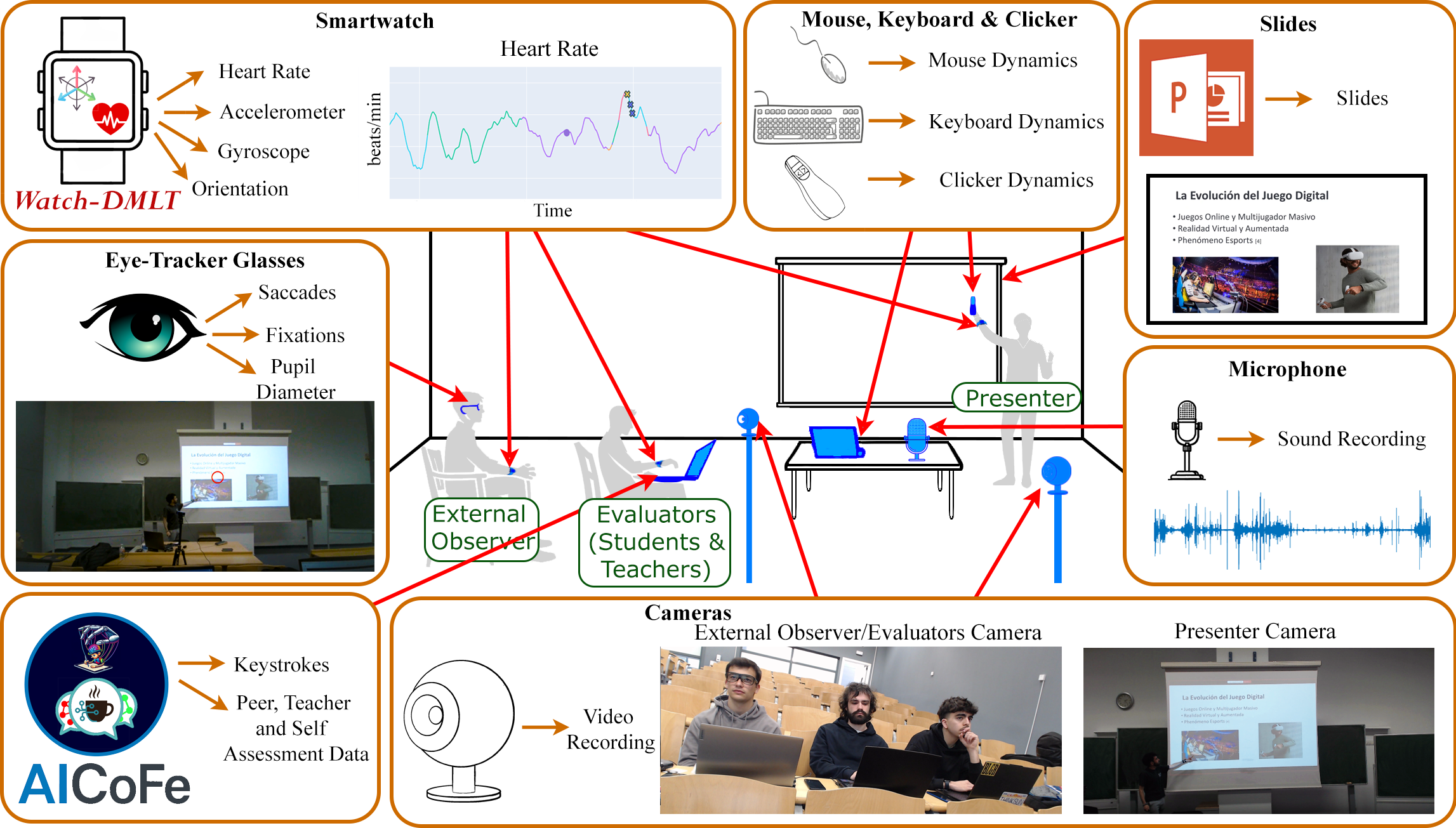
技术框架:SOPHIAS数据集的构建流程主要包括以下几个阶段: 1. 数据采集:使用高清网络摄像头、环境和摄像头音频、眼动追踪眼镜、智能手表生理传感器以及点击器、键盘和鼠标等设备,同步记录学生的口头报告过程。 2. 数据标注:对采集到的数据进行标注,包括时间戳、上下文信息、教师、同伴和自我评估等。 3. 数据存储和共享:将采集到的数据存储在GitHub和Science Data Bank上,供研究人员使用。
关键创新:SOPHIAS数据集的关键创新在于其多模态性。它不仅包含音视频信息,还包括学生的生理反应、眼动行为和交互行为等多种模态的信息。这使得研究人员可以更全面地了解学生的表现,并开发更有效的自动评估和反馈工具。
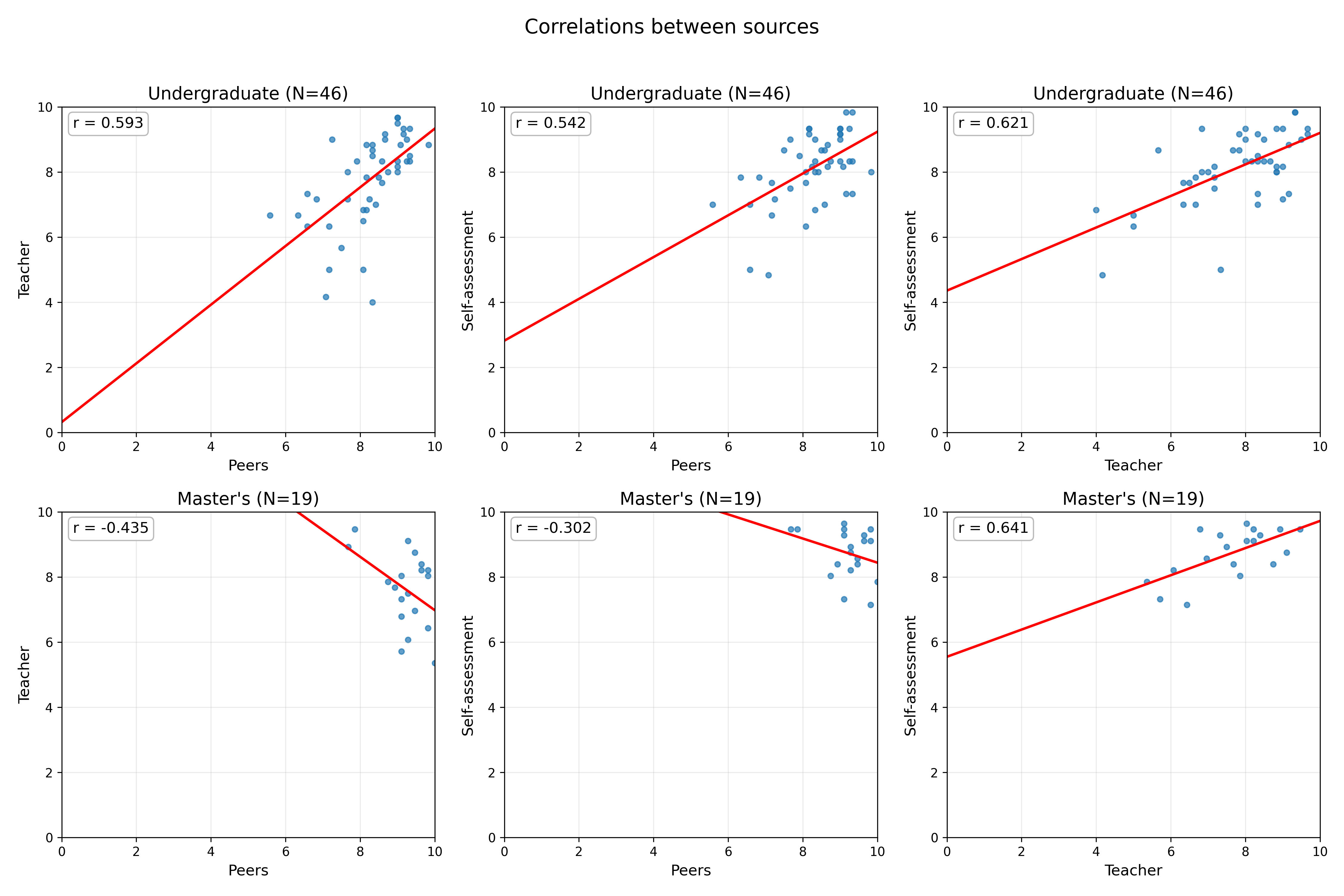
关键设计:数据集包含8个同步传感器流,包括高清网络摄像头、环境和摄像头音频、眼动追踪眼镜、智能手表生理传感器、点击器、键盘和鼠标交互。评估数据包括教师、同伴和自我评估,采用基于评分标准的评估方法。数据集还包含带时间戳的上下文注释,例如报告主题、问题类型等。
🖼️ 关键图片

📊 实验亮点
SOPHIAS数据集包含50次口头报告,由65名学生完成,总时长达12小时。数据集集成了8个同步传感器流,并包含教师、同伴和自我评估等多种评估数据。该数据集是目前最大的公开可用的多模态口头报告数据集,为相关研究提供了宝贵资源。
🎯 应用场景
该研究成果可应用于教育领域,用于开发自动化的口头报告评估和反馈系统。通过分析多模态数据,可以为学生提供个性化的反馈,帮助他们提高口头表达能力。此外,该数据集还可以用于研究同伴评估的有效性,以及不同模态信息对评估结果的影响。
📄 摘要(原文)
Oral presentation skills are a critical component of higher education, yet comprehensive datasets capturing real-world student performance across multiple modalities remain scarce. To address this gap, we present SOPHIAS (Student Oral Presentation monitoring for Holistic Insights & Analytics using Sensors), a 12-hour multimodal dataset containing recordings of 50 oral presentations (10-15-minute presentation followed by 5-15-minute Q&A) delivered by 65 undergraduate and master's students at the Universidad Autonoma de Madrid. SOPHIAS integrates eight synchronized sensor streams from high-definition webcams, ambient and webcam audio, eye-tracking glasses, smartwatch physiological sensors, and clicker, keyboard, and mouse interactions. In addition, the dataset includes slides and rubric-based evaluations from teachers, peers, and self-assessments, along with timestamped contextual annotations. The dataset captures presentations conducted in real classroom settings, preserving authentic student behaviors, interactions, and physiological responses. SOPHIAS enables the exploration of relationships between multimodal behavioral and physiological signals and presentation performance, supports the study of peer assessment, and provides a benchmark for developing automated feedback and Multimodal Learning Analytics tools. The dataset is publicly available for research through GitHub and Science Data Bank.