Mon3tr: Monocular 3D Telepresence with Pre-built Gaussian Avatars as Amortization
作者: Fangyu Lin, Yingdong Hu, Zhening Liu, Yufan Zhuang, Zehong Lin, Jun Zhang
分类: cs.CV, cs.AI
发布日期: 2026-01-12
💡 一句话要点
Mon3tr:利用预构建高斯人像的单目3D远程呈现
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 远程呈现 3D高斯溅射 单目视觉 参数化人体建模 实时渲染 AR/VR WebRTC
📋 核心要点
- 现有远程呈现系统依赖多摄像头和高带宽,限制了移动设备上的实时性能。
- Mon3tr利用单目相机驱动基于3D高斯溅射的参数化人体模型,降低系统复杂度和带宽需求。
- 实验表明,Mon3tr在新姿势下PSNR>28dB,端到端延迟约80ms,带宽降低>1000倍。
📝 摘要(中文)
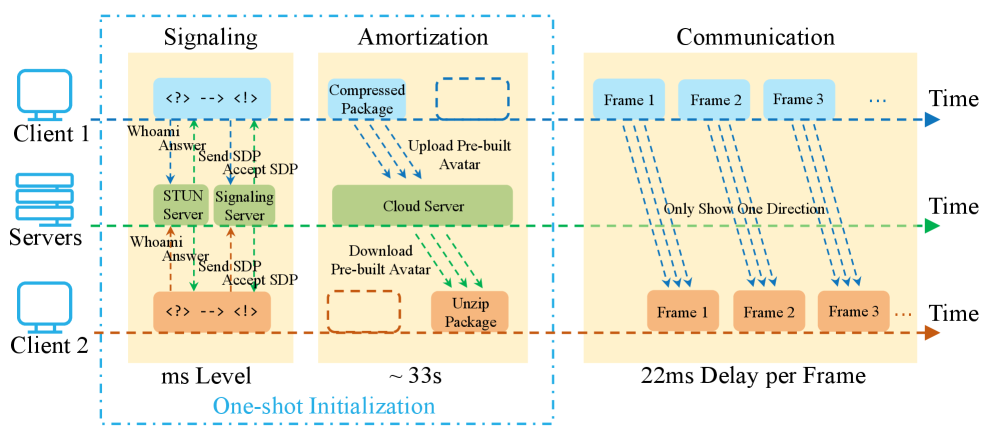
沉浸式远程呈现旨在通过逼真的全身全息表示来增强远程协作,从而改变AR/VR应用中的人机交互。然而,现有的系统依赖于硬件密集型的多摄像头设置,并需要高带宽进行体数据流传输,限制了其在移动设备上的实时性能。为了克服这些挑战,我们提出了Mon3tr,这是一种新颖的单目3D远程呈现框架,首次将基于3D高斯溅射(3DGS)的参数化人体建模集成到远程呈现中。Mon3tr采用了一种分摊计算策略,将过程分为一次性的离线多视图重建阶段(用于构建用户特定的化身)和在线单目推理阶段(在实时远程呈现会话期间)。使用单个单目RGB摄像头实时捕捉身体运动和面部表情,以驱动基于3DGS的参数化人体模型,从而显著降低了系统复杂性和成本。提取的运动和外观特征通过WebRTC的数据通道以< 0.2 Mbps的速率传输,从而能够稳健地适应网络波动。在接收端(例如,Meta Quest 3),我们开发了一个轻量级的3DGS属性变形网络,以在预构建的化身上动态生成校正性的3DGS属性调整,从而以约60 FPS的速度合成逼真的运动和外观。大量的实验表明了我们方法的先进性能,对于新姿势实现了> 28 dB的PSNR,端到端延迟约为80 ms,并且与点云流传输相比,带宽降低了> 1000倍,同时支持来自各种场景中单目输入的实时操作。我们的演示可以在https://mon3tr3d.github.io找到。
🔬 方法详解
问题定义:现有远程呈现系统通常依赖于复杂的多摄像头设置和高带宽的体数据流传输,这使得它们难以在移动设备上实现实时、低延迟的沉浸式体验。这些系统的高成本和复杂性也限制了其广泛应用。因此,需要一种更轻量级、更高效的解决方案,能够在单目视觉输入下实现高质量的3D远程呈现。
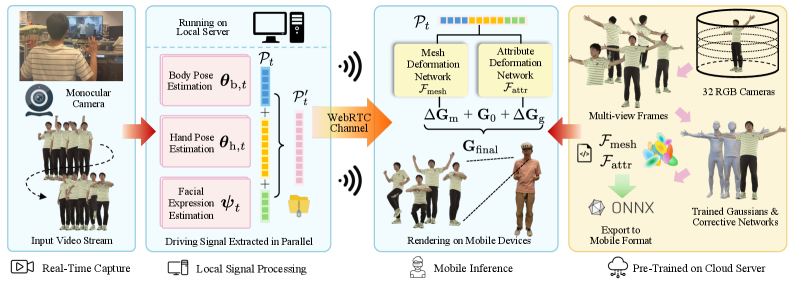
核心思路:Mon3tr的核心思路是采用一种分摊计算策略,将远程呈现过程分解为离线化身构建和在线单目推理两个阶段。离线阶段使用多视图数据构建用户特定的3D高斯人像,在线阶段则利用单目RGB相机捕捉运动和表情,驱动预构建的人像。这种方法显著降低了在线推理的计算负担和带宽需求,使其能够在移动设备上实时运行。
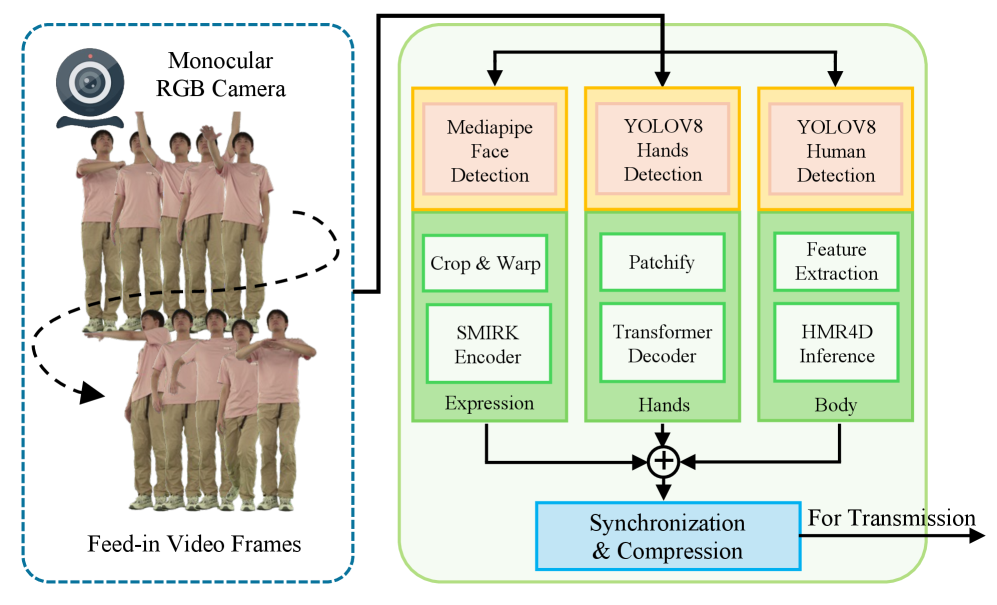
技术框架:Mon3tr的整体框架包括以下几个主要模块:1) 离线化身构建:使用多视图图像重建用户特定的3D高斯人像。2) 单目运动捕捉:使用单目RGB相机实时捕捉用户的身体运动和面部表情。3) 特征传输:将提取的运动和外观特征通过WebRTC的数据通道传输到接收端。4) 3DGS属性变形网络:在接收端,使用轻量级的3DGS属性变形网络,根据接收到的特征动态调整预构建人像的3DGS属性,生成逼真的运动和外观。
关键创新:Mon3tr最重要的技术创新点在于将3D高斯溅射(3DGS)技术引入到远程呈现领域,并采用分摊计算策略。与传统的基于点云或网格的远程呈现方法相比,3DGS具有更高的渲染效率和更低的带宽需求。此外,Mon3tr的单目输入和轻量级网络设计使其能够在移动设备上实现实时运行。
关键设计:Mon3tr的关键设计包括:1) 使用3DGS作为参数化人体模型的表示形式,以实现高效的渲染和传输。2) 设计轻量级的3DGS属性变形网络,以在接收端动态调整人像的3DGS属性。3) 优化特征提取和传输流程,以实现低延迟和低带宽的通信。4) 采用WebRTC的数据通道进行特征传输,以实现稳健的网络适应性。
🖼️ 关键图片
📊 实验亮点
Mon3tr在实验中表现出色,对于新姿势实现了超过28 dB的PSNR,端到端延迟约为80 ms,与点云流传输相比,带宽降低了超过1000倍。这些结果表明,Mon3tr在保证高质量渲染效果的同时,显著降低了系统复杂性和带宽需求,使其能够在移动设备上实现实时运行。该方法在多个场景下进行了测试,验证了其鲁棒性和泛化能力。
🎯 应用场景
Mon3tr具有广泛的应用前景,包括AR/VR远程协作、虚拟会议、远程教育、虚拟社交等。该技术可以实现更逼真、更自然的远程人机交互,提高沟通效率和沉浸感。未来,Mon3tr有望应用于各种移动设备和AR/VR头显,实现随时随地的沉浸式远程呈现体验。
📄 摘要(原文)
Immersive telepresence aims to transform human interaction in AR/VR applications by enabling lifelike full-body holographic representations for enhanced remote collaboration. However, existing systems rely on hardware-intensive multi-camera setups and demand high bandwidth for volumetric streaming, limiting their real-time performance on mobile devices. To overcome these challenges, we propose Mon3tr, a novel Monocular 3D telepresence framework that integrates 3D Gaussian splatting (3DGS) based parametric human modeling into telepresence for the first time. Mon3tr adopts an amortized computation strategy, dividing the process into a one-time offline multi-view reconstruction phase to build a user-specific avatar and a monocular online inference phase during live telepresence sessions. A single monocular RGB camera is used to capture body motions and facial expressions in real time to drive the 3DGS-based parametric human model, significantly reducing system complexity and cost. The extracted motion and appearance features are transmitted at < 0.2 Mbps over WebRTC's data channel, allowing robust adaptation to network fluctuations. On the receiver side, e.g., Meta Quest 3, we develop a lightweight 3DGS attribute deformation network to dynamically generate corrective 3DGS attribute adjustments on the pre-built avatar, synthesizing photorealistic motion and appearance at ~ 60 FPS. Extensive experiments demonstrate the state-of-the-art performance of our method, achieving a PSNR of > 28 dB for novel poses, an end-to-end latency of ~ 80 ms, and > 1000x bandwidth reduction compared to point-cloud streaming, while supporting real-time operation from monocular inputs across diverse scenarios. Our demos can be found at https://mon3tr3d.github.io.