SDHSI-Net: Learning Better Representations for Hyperspectral Images via Self-Distillation
作者: Prachet Dev Singh, Shyamsundar Paramasivam, Sneha Barman, Mainak Singha, Ankit Jha, Girish Mishra, Biplab Banerjee
分类: cs.CV
发布日期: 2026-01-12
备注: Accepted at InGARSS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
SDHSI-Net:通过自蒸馏学习高光谱图像的更优表征
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 高光谱图像分类 自蒸馏 知识蒸馏 深度学习 光谱-空间特征
📋 核心要点
- 高光谱图像分类面临高维度和小样本问题,传统深度学习模型易过拟合且计算成本高昂。
- 论文提出基于自蒸馏的SDHSI-Net,利用网络自身预测作为软目标,提升特征空间类内紧凑性和类间可分性。
- 在两个基准数据集上验证,SDHSI-Net显著提升了分类精度和鲁棒性,证明了自蒸馏在高光谱图像学习中的有效性。
📝 摘要(中文)
高光谱图像(HSI)分类由于其高光谱维度和有限的标记数据而面临独特的挑战。传统的深度学习模型通常遭受过拟合和高计算成本的困扰。自蒸馏(SD)是知识蒸馏的一种变体,其中网络从自身的预测中学习,最近已成为一种有前途的策略,可以在不需要外部教师网络的情况下提高模型性能。在这项工作中,我们探索了SD在HSI中的应用,将早期输出视为软目标,从而加强中间预测和最终预测之间的一致性。这个过程改善了学习到的特征空间中的类内紧凑性和类间可分性。我们的方法在两个基准HSI数据集上得到了验证,并证明了分类精度和鲁棒性的显著提高,突出了SD在光谱-空间学习中的有效性。
🔬 方法详解
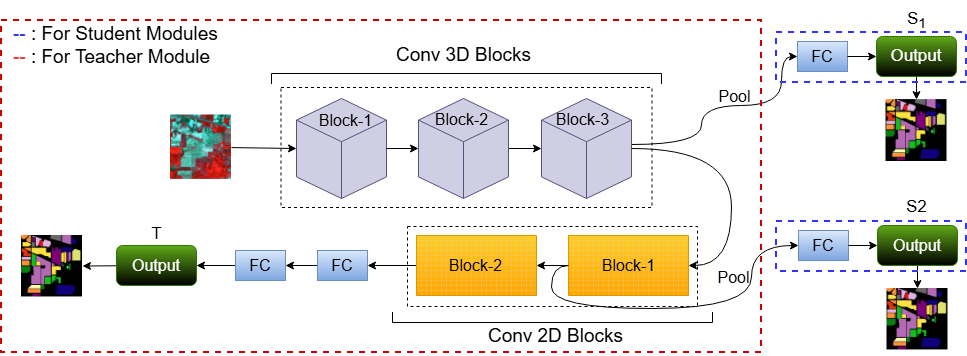
问题定义:高光谱图像(HSI)分类任务面临的挑战在于其高光谱维度和有限的标记数据。传统深度学习方法,如直接训练深层网络,容易出现过拟合现象,并且计算复杂度较高,难以有效利用光谱-空间信息。现有方法在提升模型泛化能力和降低计算成本方面存在不足。
核心思路:论文的核心思路是利用自蒸馏(Self-Distillation, SD)技术,让网络从自身的预测中学习。具体来说,将网络中间层的输出作为软目标,指导最终输出层的学习,从而在网络内部建立知识传递机制。这种方法无需额外的教师网络,能够有效提升模型的泛化能力和鲁棒性。
技术框架:SDHSI-Net的整体框架是一个深度神经网络,其关键在于自蒸馏模块的引入。网络包含多个卷积层和池化层,用于提取高光谱图像的光谱-空间特征。在网络的中间层,引入自蒸馏模块,将该层的输出作为软目标,与最终输出层的预测结果进行比较,计算蒸馏损失。最终的损失函数由分类损失和蒸馏损失加权组成。
关键创新:论文的关键创新在于将自蒸馏技术应用于高光谱图像分类任务,并设计了一种有效的自蒸馏策略。与传统的知识蒸馏方法不同,SDHSI-Net不需要额外的教师网络,而是利用网络自身的预测作为软目标,从而降低了计算成本和模型复杂度。此外,通过在中间层引入自蒸馏模块,可以更好地利用高光谱图像的光谱-空间信息,提升模型的泛化能力。
关键设计:SDHSI-Net的关键设计包括:1) 选择合适的网络结构,例如卷积神经网络,以有效提取高光谱图像的光谱-空间特征;2) 设计合适的蒸馏损失函数,例如KL散度损失,以衡量中间层输出和最终输出之间的差异;3) 确定合适的权重系数,平衡分类损失和蒸馏损失之间的贡献;4) 调整网络深度和宽度,以获得最佳的性能和计算效率。
🖼️ 关键图片

📊 实验亮点
SDHSI-Net在两个公开高光谱数据集上取得了显著的性能提升。实验结果表明,相比于传统的深度学习方法,SDHSI-Net在分类精度上取得了明显的提高,并且具有更强的鲁棒性。具体性能数据在论文中给出,证明了自蒸馏策略在高光谱图像分类中的有效性。
🎯 应用场景
该研究成果可应用于遥感图像分析、精准农业、环境监测、地质勘探等领域。通过提升高光谱图像分类的精度和鲁棒性,可以更准确地识别地物类型、评估农作物健康状况、监测环境污染程度等,为相关领域的决策提供更可靠的依据。未来,该方法有望推广到其他高维数据分析任务中。
📄 摘要(原文)
Hyperspectral image (HSI) classification presents unique challenges due to its high spectral dimensionality and limited labeled data. Traditional deep learning models often suffer from overfitting and high computational costs. Self-distillation (SD), a variant of knowledge distillation where a network learns from its own predictions, has recently emerged as a promising strategy to enhance model performance without requiring external teacher networks. In this work, we explore the application of SD to HSI by treating earlier outputs as soft targets, thereby enforcing consistency between intermediate and final predictions. This process improves intra-class compactness and inter-class separability in the learned feature space. Our approach is validated on two benchmark HSI datasets and demonstrates significant improvements in classification accuracy and robustness, highlighting the effectiveness of SD for spectral-spatial learning. Codes are available at https://github.com/Prachet-Dev-Singh/SDHSI.