HiVid-Narrator: Hierarchical Video Narrative Generation with Scene-Primed ASR-anchored Compression
作者: Haoxuan Li, Mengyan Li, Junjun Zheng
分类: cs.CV
发布日期: 2026-01-12
💡 一句话要点
HiVid-Narrator:提出基于场景的ASR锚定压缩的分层视频叙事生成框架,用于电商视频。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频叙事生成 电商视频 分层模型 多模态压缩 ASR锚定 E-HVC数据集 场景理解
📋 核心要点
- 现有视频叙事模型难以兼顾细粒度视觉理解和高层次故事组织,尤其是在信息密集的电商视频场景下。
- HiVid-Narrator通过分阶段构建叙事,首先收集语言和视觉证据,然后细化章节边界和标题,实现基于事实和时间对齐的叙事。
- 提出的SPA-Compressor利用ASR语义线索压缩多模态token,减少输入量,提高训练效率,并最终提升叙事质量。
📝 摘要(中文)
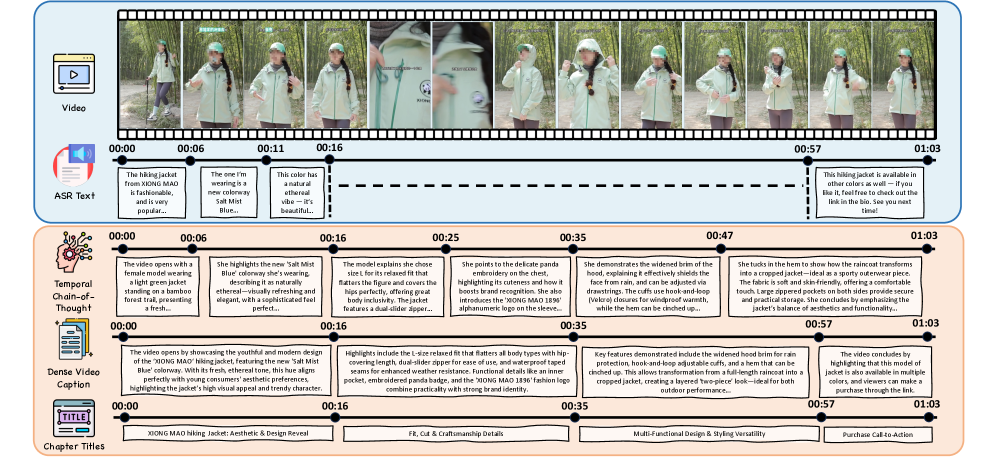
为真实电商视频生成结构化叙事需要模型理解细粒度的视觉细节,并将其组织成连贯的、高层次的故事,而现有方法难以统一这些能力。我们引入了电商分层视频字幕(E-HVC)数据集,该数据集具有双粒度、时间对齐的标注:时间链式思考(Temporal Chain-of-Thought),锚定事件级别的观察;章节摘要(Chapter Summary),将它们组合成简洁的、以故事为中心的摘要。我们没有直接提示章节,而是采用分阶段构建的方式,首先通过精心设计的ASR和帧级别描述收集可靠的语言和视觉证据,然后根据时间链式思考细化粗略的标注,得到精确的章节边界和标题,从而产生基于事实、时间对齐的叙事。我们还观察到,电商视频节奏快、信息密度高,视觉token在输入序列中占主导地位。为了实现高效训练并减少输入token,我们提出了基于场景的ASR锚定压缩器(SPA-Compressor),它在ASR语义线索的指导下,将多模态token压缩成层次化的场景和事件表示。基于这些设计,我们的HiVid-Narrator框架与现有方法相比,以更少的输入token实现了卓越的叙事质量。
🔬 方法详解
问题定义:论文旨在解决电商视频叙事生成问题,现有方法难以同时捕捉细粒度的视觉信息并将其组织成连贯的故事。电商视频节奏快、信息密度高,视觉token占据主导地位,导致模型训练效率低下,叙事质量难以保证。
核心思路:论文的核心思路是分层构建视频叙事,并利用ASR信息引导多模态信息的压缩。通过分阶段的方式,首先收集可靠的语言和视觉证据,然后细化章节边界和标题,从而生成高质量的叙事。同时,利用ASR信息对多模态信息进行压缩,减少输入token,提高训练效率。
技术框架:HiVid-Narrator框架主要包含以下几个阶段:1) 数据收集与标注:构建E-HVC数据集,包含时间链式思考和章节摘要两种粒度的标注。2) 证据收集:利用ASR和帧级别描述收集语言和视觉证据。3) 章节细化:根据时间链式思考细化章节边界和标题。4) 叙事生成:生成最终的视频叙事。其中,SPA-Compressor用于压缩多模态token,减少输入量。
关键创新:论文的关键创新点在于:1) 提出了E-HVC数据集,包含双粒度、时间对齐的标注。2) 提出了分阶段构建叙事的方法,首先收集证据,然后细化章节,从而生成高质量的叙事。3) 提出了SPA-Compressor,利用ASR信息引导多模态信息的压缩,减少输入token,提高训练效率。与现有方法相比,HiVid-Narrator能够以更少的输入token生成更高质量的叙事。
关键设计:SPA-Compressor的关键设计在于利用ASR信息作为语义线索,指导多模态token的压缩。具体来说,SPA-Compressor首先将视频帧和ASR文本编码成多模态特征,然后利用注意力机制将这些特征压缩成层次化的场景和事件表示。损失函数的设计旨在保证压缩后的表示能够保留原始视频的关键信息,并与ASR信息对齐。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
HiVid-Narrator框架在E-HVC数据集上取得了显著的性能提升。与现有方法相比,该框架能够以更少的输入token生成更高质量的叙事。具体的性能数据和对比基线在论文的实验部分有详细描述,实验结果表明,提出的SPA-Compressor能够有效地压缩多模态信息,提高训练效率,并最终提升叙事质量。
🎯 应用场景
该研究成果可应用于电商视频的自动叙事生成,提升用户体验,帮助用户快速了解商品信息。此外,该方法还可以推广到其他类型的视频,如新闻视频、教育视频等,实现视频内容的自动摘要和叙事,具有广泛的应用前景和实际价值。未来,可以进一步研究如何利用更丰富的多模态信息,如音频、用户行为等,提升叙事质量。
📄 摘要(原文)
Generating structured narrations for real-world e-commerce videos requires models to perceive fine-grained visual details and organize them into coherent, high-level stories--capabilities that existing approaches struggle to unify. We introduce the E-commerce Hierarchical Video Captioning (E-HVC) dataset with dual-granularity, temporally grounded annotations: a Temporal Chain-of-Thought that anchors event-level observations and Chapter Summary that compose them into concise, story-centric summaries. Rather than directly prompting chapters, we adopt a staged construction that first gathers reliable linguistic and visual evidence via curated ASR and frame-level descriptions, then refines coarse annotations into precise chapter boundaries and titles conditioned on the Temporal Chain-of-Thought, yielding fact-grounded, time-aligned narratives. We also observe that e-commerce videos are fast-paced and information-dense, with visual tokens dominating the input sequence. To enable efficient training while reducing input tokens, we propose the Scene-Primed ASR-anchored Compressor (SPA-Compressor), which compresses multimodal tokens into hierarchical scene and event representations guided by ASR semantic cues. Built upon these designs, our HiVid-Narrator framework achieves superior narrative quality with fewer input tokens compared to existing methods.