Seeing Right but Saying Wrong: Inter- and Intra-Layer Refinement in MLLMs without Training
作者: Shezheng Song, Shasha Li, Jie Yu
分类: cs.CV, cs.AI
发布日期: 2026-01-12
💡 一句话要点
提出DualPD,无需训练即可提升MLLM层间一致性,解决“知行不一”问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉语言理解 注意力机制 层间一致性 无训练优化
📋 核心要点
- MLLM深层网络关注正确视觉区域,但浅层噪声注意力会误导最终预测,导致模型“知行不一”。
- DualPD通过层间对比logits和层内注意力头过滤,在不训练的情况下提升视觉理解能力。
- 实验表明,DualPD在多个多模态基准测试中,无需训练即可持续提高LLaVA和Qwen-VL模型的准确性。
📝 摘要(中文)
多模态大型语言模型(MLLMs)在各种视觉-语言任务中表现出强大的能力。然而,它们的内部推理常常表现出一种关键的不一致性:尽管更深层可能关注正确的视觉区域,但最终的预测常常被早期层中嘈杂的注意力所误导。这导致了模型内部理解和最终表达之间的脱节,我们将其描述为“知行不一”。为了解决这个问题,我们提出了一种双视角解码优化策略DualPD,它可以在没有任何额外训练的情况下增强视觉理解。DualPD由两个部分组成。(1)逐层注意力引导的对比logits模块,通过比较注意力变化最大的层之间的输出logits,来捕捉对正确答案的置信度是如何演变的。(2)头部级信息过滤模块,抑制关注不相关区域的低贡献注意力头,从而提高每层内的注意力质量。在LLaVA和Qwen-VL模型家族上进行的跨多个多模态基准的实验表明,DualPD在没有训练的情况下始终提高准确性,证实了其有效性和泛化性。代码将在发布后公开。
🔬 方法详解
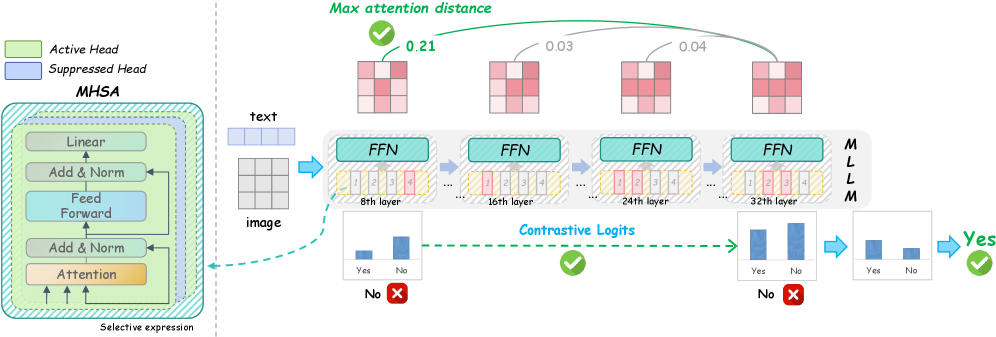
问题定义:MLLM在视觉-语言任务中表现出色,但存在“知行不一”的问题。即模型深层网络可能已经关注到正确的视觉区域,但由于浅层网络的噪声注意力干扰,最终的预测结果却不准确。现有方法通常需要大量的训练数据来调整模型参数,以提高模型的一致性,但成本较高。
核心思路:DualPD的核心思路是通过双视角解码优化策略,在不进行额外训练的情况下,提升MLLM的视觉理解能力。它从层间和层内两个角度出发,分别对模型的输出logits和注意力机制进行优化,从而提高模型的一致性和准确性。
技术框架:DualPD包含两个主要模块:(1)逐层注意力引导的对比logits模块:该模块通过比较注意力变化最大的层之间的输出logits,来捕捉模型对正确答案的置信度是如何演变的。具体来说,它计算不同层之间的logits差异,并利用注意力权重来引导对比学习,从而增强模型对正确答案的置信度。(2)头部级信息过滤模块:该模块抑制关注不相关区域的低贡献注意力头,从而提高每层内的注意力质量。具体来说,它计算每个注意力头对最终预测的贡献度,并根据贡献度对注意力头进行过滤,从而减少噪声注意力的干扰。
关键创新:DualPD的关键创新在于它提出了一种无需训练的优化策略,可以有效地解决MLLM中的“知行不一”问题。与现有方法相比,DualPD不需要大量的训练数据,因此可以降低训练成本。此外,DualPD从层间和层内两个角度出发,对模型的输出logits和注意力机制进行优化,从而更全面地提升模型的一致性和准确性。
关键设计:在逐层注意力引导的对比logits模块中,关键在于如何选择注意力变化最大的层。论文中可能采用了一种基于注意力权重差异的策略来选择这些层。在头部级信息过滤模块中,关键在于如何计算每个注意力头对最终预测的贡献度。论文中可能采用了一种基于梯度或注意力权重的策略来计算贡献度。具体的损失函数和网络结构细节需要在论文原文中查找。
🖼️ 关键图片


📊 实验亮点
DualPD在LLaVA和Qwen-VL模型家族上进行了实验,并在多个多模态基准测试中取得了显著的性能提升。实验结果表明,DualPD在没有训练的情况下,能够持续提高模型的准确性,验证了其有效性和泛化性。具体的性能提升幅度需要在论文原文中查找。
🎯 应用场景
DualPD可应用于各种视觉-语言任务,如图像描述、视觉问答、目标检测等。该研究成果有助于提升多模态大语言模型在实际应用中的可靠性和准确性,例如在智能客服、自动驾驶、医疗诊断等领域,可以提高人机交互的自然性和效率,并降低错误决策的风险。未来,该方法可以进一步扩展到其他多模态模型和任务中。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have demonstrated strong capabilities across a variety of vision-language tasks. However, their internal reasoning often exhibits a critical inconsistency: although deeper layers may attend to the correct visual regions, final predictions are frequently misled by noisy attention from earlier layers. This results in a disconnect between what the model internally understands and what it ultimately expresses, a phenomenon we describe as seeing it right but saying it wrong. To address this issue, we propose DualPD, a dual-perspective decoding refinement strategy that enhances the visual understanding without any additional training. DualPD consists of two components. (1) The layer-wise attention-guided contrastive logits module captures how the belief in the correct answer evolves by comparing output logits between layers that exhibit the largest attention shift. (2) The head-wise information filtering module suppresses low-contribution attention heads that focus on irrelevant regions, thereby improving attention quality within each layer. Experiments conducted on both the LLaVA and Qwen-VL model families across multiple multimodal benchmarks demonstrate that DualPD consistently improves accuracy without training, confirming its effectiveness and generalizability. The code will be released upon publication.