OSCAR: Open-Set CAD Retrieval from a Language Prompt and a Single Image
作者: Tessa Pulli, Jean-Baptiste Weibel, Peter Hönig, Matthias Hirschmanner, Markus Vincze, Andreas Holzinger
分类: cs.CV, cs.RO
发布日期: 2026-01-12
💡 一句话要点
OSCAR:一种基于语言提示和单张图像的开放集CAD模型检索方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: CAD模型检索 零样本学习 6D姿态估计 多模态融合 图像描述 开放集识别
📋 核心要点
- 现有零样本物体姿态估计依赖CAD模型,但实际部署中模型难以获取,且物体集合不断变化,难以可靠识别目标实例。
- OSCAR通过语言提示和单张图像,从无标签3D对象数据库中检索匹配的CAD模型,无需针对特定对象进行训练。
- 实验表明,OSCAR在MI3DOR基准上优于现有方法,并在YCB-V数据集上实现了90.48%的平均检索精度,可用于姿态估计。
📝 摘要(中文)
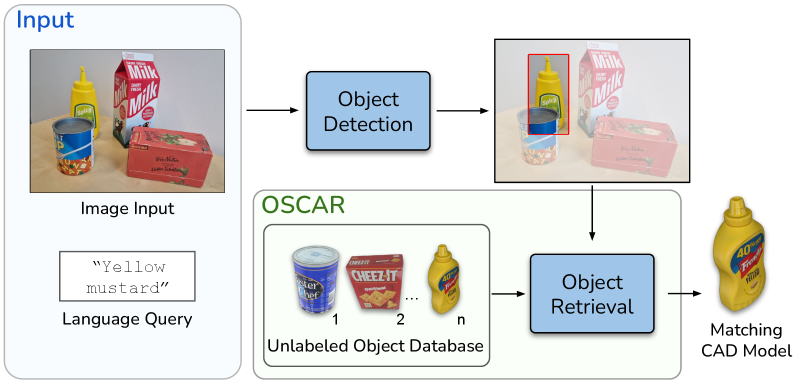
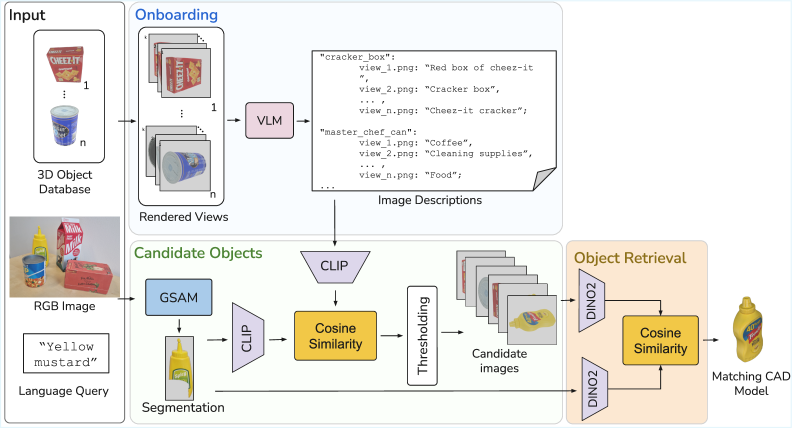
本文提出了一种名为OSCAR的免训练方法,用于从无标签的3D对象数据库中检索匹配的对象模型。该方法旨在解决零样本6D物体姿态估计中,难以获取CAD模型以及物体集合不断变化的问题。在模型入库阶段,OSCAR生成数据库模型的多视角渲染图,并使用图像描述模型为它们添加描述性文本。在推理阶段,GroundedSAM检测输入图像中的目标对象,并为感兴趣区域和数据库描述文本计算多模态嵌入。OSCAR采用两阶段检索:首先使用CLIP进行基于文本的过滤,识别候选模型;然后使用DINOv2进行基于图像的细化,选择视觉上最相似的对象。实验表明,OSCAR在跨域3D模型检索基准MI3DOR上优于所有最先进的方法。此外,OSCAR可以直接应用于自动化对象模型采购,用于6D对象姿态估计。当无法获得精确的实例模型时,可以使用最相似的对象模型进行姿态估计。在YCB-V对象数据集上,OSCAR在对象检索中实现了90.48%的平均精度。此外,使用Megapose进行姿态估计时,最相似的对象模型可以获得比基于重建的方法更好的结果。
🔬 方法详解
问题定义:论文旨在解决在开放场景下,零样本6D物体姿态估计中CAD模型难以获取的问题。现有方法依赖于预先准备好的CAD模型,但实际应用中,物体种类繁多且不断变化,难以维护一个完整的CAD模型库。此外,精确的实例模型可能无法获得,导致姿态估计精度下降。
核心思路:论文的核心思路是利用语言提示和单张图像,从一个包含大量未标注CAD模型的数据库中检索出与目标物体最匹配的模型。通过结合文本和图像信息,实现对目标物体的精确识别和检索,从而为后续的姿态估计提供可靠的模型基础。
技术框架:OSCAR包含两个主要阶段:模型入库阶段和推理阶段。在模型入库阶段,对数据库中的每个CAD模型进行多视角渲染,并使用图像描述模型生成描述性文本。在推理阶段,首先使用GroundedSAM检测输入图像中的目标对象,然后计算目标区域和数据库描述文本的多模态嵌入。接着,使用CLIP进行基于文本的初步过滤,筛选出候选模型。最后,使用DINOv2进行基于图像的细化,选择视觉上最相似的对象模型。
关键创新:OSCAR的关键创新在于结合了语言和视觉信息进行CAD模型检索,并采用两阶段检索策略。通过利用图像描述模型生成CAD模型的文本描述,实现了基于文本的初步过滤,缩小了搜索范围。然后,利用DINOv2提取图像特征,进行视觉相似度匹配,从而选择最合适的CAD模型。这种方法有效地利用了多模态信息,提高了检索精度。
关键设计:OSCAR的关键设计包括:1) 使用GroundedSAM进行目标检测,提取感兴趣区域;2) 使用CLIP进行文本嵌入和相似度计算,实现初步过滤;3) 使用DINOv2提取图像特征,进行视觉相似度匹配;4) 采用两阶段检索策略,先文本后图像,提高检索效率和精度。具体参数设置和损失函数等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
OSCAR在跨域3D模型检索基准MI3DOR上优于所有最先进的方法。在YCB-V对象数据集上,OSCAR在对象检索中实现了90.48%的平均精度。此外,使用Megapose进行姿态估计时,基于OSCAR检索到的最相似对象模型可以获得比基于重建的方法更好的结果,表明了OSCAR在实际应用中的有效性。
🎯 应用场景
OSCAR可广泛应用于机器人、增强现实等领域,尤其是在需要处理不断变化物体集合的场景中。例如,机器人可以利用OSCAR自动识别和检索未知物体,从而进行抓取、操作等任务。在增强现实中,OSCAR可以用于快速识别用户拍摄的物体,并提供相关的3D模型和信息。该研究有助于降低6D物体姿态估计对精确CAD模型的依赖,提高系统的鲁棒性和适应性。
📄 摘要(原文)
6D object pose estimation plays a crucial role in scene understanding for applications such as robotics and augmented reality. To support the needs of ever-changing object sets in such context, modern zero-shot object pose estimators were developed to not require object-specific training but only rely on CAD models. Such models are hard to obtain once deployed, and a continuously changing and growing set of objects makes it harder to reliably identify the instance model of interest. To address this challenge, we introduce an Open-Set CAD Retrieval from a Language Prompt and a Single Image (OSCAR), a novel training-free method that retrieves a matching object model from an unlabeled 3D object database. During onboarding, OSCAR generates multi-view renderings of database models and annotates them with descriptive captions using an image captioning model. At inference, GroundedSAM detects the queried object in the input image, and multi-modal embeddings are computed for both the Region-of-Interest and the database captions. OSCAR employs a two-stage retrieval: text-based filtering using CLIP identifies candidate models, followed by image-based refinement using DINOv2 to select the most visually similar object. In our experiments we demonstrate that OSCAR outperforms all state-of-the-art methods on the cross-domain 3D model retrieval benchmark MI3DOR. Furthermore, we demonstrate OSCAR's direct applicability in automating object model sourcing for 6D object pose estimation. We propose using the most similar object model for pose estimation if the exact instance is not available and show that OSCAR achieves an average precision of 90.48\% during object retrieval on the YCB-V object dataset. Moreover, we demonstrate that the most similar object model can be utilized for pose estimation using Megapose achieving better results than a reconstruction-based approach.