Focal Guidance: Unlocking Controllability from Semantic-Weak Layers in Video Diffusion Models
作者: Yuanyang Yin, Yufan Deng, Shenghai Yuan, Kaipeng Zhang, Xiao Yang, Feng Zhao
分类: cs.CV
发布日期: 2026-01-12
💡 一句话要点
提出Focal Guidance以解决视频扩散模型中的语义弱层控制问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像到视频生成 扩散模型 多模态学习 语义指导 注意力机制 文本遵循 条件隔离 CLIP模型
📋 核心要点
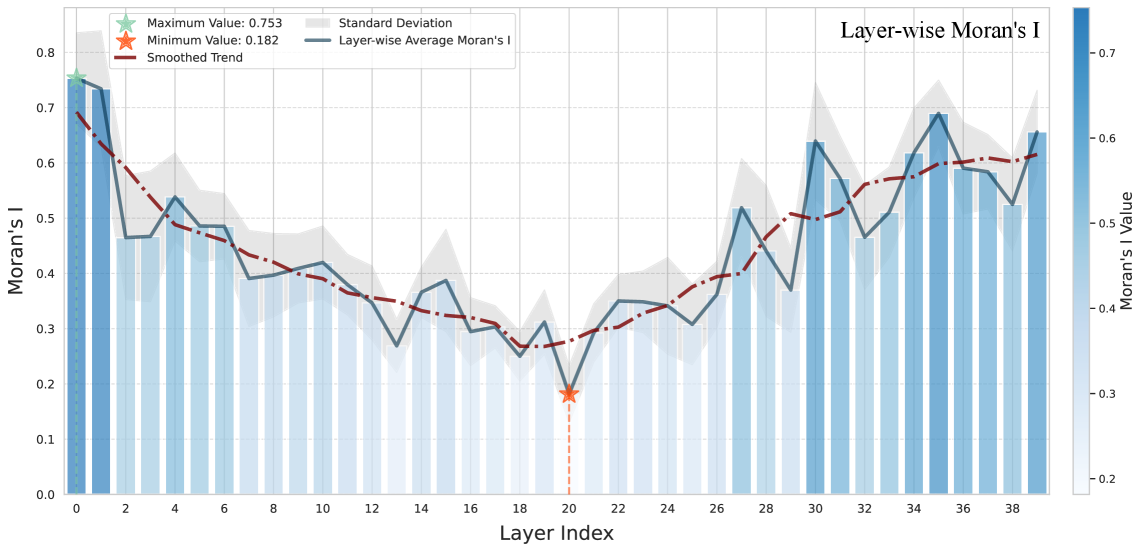
- 现有I2V模型在视觉一致性方面表现良好,但对文本提示的遵循能力不足,尤其在某些中间层的语义响应较弱。
- 本文提出Focal Guidance,通过细粒度语义指导和注意力缓存机制,增强语义弱层的控制能力,从而提高文本遵循性。
- 在新提出的基准测试中,Focal Guidance显著提升了模型性能,Wan2.1-I2V总分提高了3.97%,HunyuanVideo-I2V提升了7.44%。
📝 摘要(中文)
图像到视频生成(I2V)任务旨在根据参考图像和文本提示合成视频。现有I2V模型在视觉一致性上表现良好,但如何有效结合视觉和文本指导以确保对文本提示的强遵循仍未得到充分探索。本文观察到在基于扩散变换器的I2V模型中,某些中间层表现出弱语义响应,导致视觉特征与文本指导之间的注意力部分脱离。为了解决这一问题,提出了Focal Guidance(FG),通过细粒度语义指导和注意力缓存机制增强了对语义弱层的控制。实验结果表明,FG在Wan2.1-I2V基准上提升了3.97%,在MMDiT基础的HunyuanVideo-I2V上提升了7.44%。
🔬 方法详解
问题定义:本文旨在解决图像到视频生成模型中,某些中间层(语义弱层)对文本提示的响应不足的问题。现有方法在视觉一致性上表现良好,但在文本遵循性上存在明显短板,尤其是受到条件隔离现象的影响。
核心思路:提出Focal Guidance(FG),通过细粒度语义指导(FSG)和注意力缓存机制,增强语义弱层的控制能力。FSG利用CLIP模型识别参考帧中的关键区域,并将其作为锚点引导语义弱层,而注意力缓存则将语义响应层的注意力图转移到语义弱层,从而减轻其对视觉先验的过度依赖。
技术框架:FG的整体架构包括两个主要模块:细粒度语义指导和注意力缓存。细粒度语义指导模块通过CLIP识别关键区域并进行引导,而注意力缓存模块则负责将有效的注意力信息传递给语义弱层。
关键创新:最重要的创新点在于通过细粒度语义指导和注意力缓存机制,解决了语义弱层对文本提示响应不足的问题。这一方法与现有方法的本质区别在于其增强了模型的可控性和文本遵循能力。
关键设计:在设计上,FG采用了CLIP模型进行关键区域识别,并通过特定的损失函数来优化语义弱层的输出。此外,注意力缓存的实现需要精确的注意力图转移策略,以确保信息的有效传递。
🖼️ 关键图片

📊 实验亮点
实验结果显示,Focal Guidance在Wan2.1-I2V基准上总分提升了3.97%,达到0.7250,同时在MMDiT基础的HunyuanVideo-I2V上提升了7.44%,达到0.5571。这些结果表明FG在提升模型性能和文本遵循性方面的有效性和广泛适用性。
🎯 应用场景
该研究的潜在应用领域包括视频生成、内容创作和多模态交互等。通过增强模型对文本提示的遵循能力,Focal Guidance可以在影视制作、游戏开发和虚拟现实等领域发挥重要作用,提升用户体验和创作效率。未来,该技术可能会推动更复杂的多模态生成任务的发展。
📄 摘要(原文)
The task of Image-to-Video (I2V) generation aims to synthesize a video from a reference image and a text prompt. This requires diffusion models to reconcile high-frequency visual constraints and low-frequency textual guidance during the denoising process. However, while existing I2V models prioritize visual consistency, how to effectively couple this dual guidance to ensure strong adherence to the text prompt remains underexplored. In this work, we observe that in Diffusion Transformer (DiT)-based I2V models, certain intermediate layers exhibit weak semantic responses (termed Semantic-Weak Layers), as indicated by a measurable drop in text-visual similarity. We attribute this to a phenomenon called Condition Isolation, where attention to visual features becomes partially detached from text guidance and overly relies on learned visual priors. To address this, we propose Focal Guidance (FG), which enhances the controllability from Semantic-Weak Layers. FG comprises two mechanisms: (1) Fine-grained Semantic Guidance (FSG) leverages CLIP to identify key regions in the reference frame and uses them as anchors to guide Semantic-Weak Layers. (2) Attention Cache transfers attention maps from semantically responsive layers to Semantic-Weak Layers, injecting explicit semantic signals and alleviating their over-reliance on the model's learned visual priors, thereby enhancing adherence to textual instructions. To further validate our approach and address the lack of evaluation in this direction, we introduce a benchmark for assessing instruction following in I2V models. On this benchmark, Focal Guidance proves its effectiveness and generalizability, raising the total score on Wan2.1-I2V to 0.7250 (+3.97\%) and boosting the MMDiT-based HunyuanVideo-I2V to 0.5571 (+7.44\%).