PALUM: Part-based Attention Learning for Unified Motion Retargeting
作者: Siqi Liu, Maoyu Wang, Bo Dai, Cewu Lu
分类: cs.CV
发布日期: 2026-01-12
💡 一句话要点
PALUM:提出基于部件注意力学习的统一运动重定向方法
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 运动重定向 部件注意力 骨骼动画 循环一致性 深度学习
📋 核心要点
- 现有运动重定向方法难以处理骨骼结构差异大的角色,导致运动语义和质量下降。
- PALUM将关节划分为语义部件,利用注意力机制学习与骨骼无关的通用运动表示,实现跨骨骼的运动迁移。
- 实验表明,PALUM在处理不同骨骼结构时,能保持运动的真实感和语义保真度,并具有良好的泛化能力。
📝 摘要(中文)
运动重定向是计算机动画中的一个基本挑战,尤其是在具有不同骨骼结构的骨骼角色之间进行运动迁移时。当源角色和目标角色的骨骼排列差异很大时,保持原始运动的语义和质量变得非常困难。本文提出了一种名为PALUM的新方法,该方法通过将关节划分为语义身体部位,并应用注意力机制来捕获时空关系,从而学习跨不同骨骼拓扑的通用运动表示。我们的方法利用这些与骨骼无关的表示以及特定于目标的结构信息,将运动传递到目标骨骼。为了确保鲁棒学习并保持运动保真度,我们引入了一种循环一致性机制,该机制在整个重定向过程中保持语义连贯性。大量实验表明,即使在推广到以前未见过的骨骼-运动组合时,该方法在处理各种骨骼结构、同时保持运动真实感和语义保真度方面也表现出卓越的性能。我们将公开我们的实现,以支持未来的研究。
🔬 方法详解
问题定义:运动重定向旨在将一个角色的运动迁移到另一个角色上。现有方法在处理骨骼结构差异较大的角色时,难以保持原始运动的语义和质量,容易出现失真或不自然的运动。这是因为不同骨骼结构的角色,其关节数量、连接方式和运动范围可能存在显著差异,导致直接的运动映射效果不佳。
核心思路:PALUM的核心思路是将关节划分为语义相关的身体部件(如头部、躯干、四肢),并学习这些部件之间的时空关系。通过注意力机制,模型可以关注对运动迁移至关重要的部件,并忽略不相关的部件。这种基于部件的注意力学习方法,能够提取与骨骼结构无关的通用运动表示,从而实现跨不同骨骼结构的运动重定向。
技术框架:PALUM的整体框架包括以下几个主要模块:1) 部件划分模块:将输入骨骼的关节划分为不同的语义部件。2) 特征提取模块:提取每个部件的时空特征。3) 注意力学习模块:利用注意力机制学习部件之间的关系,生成与骨骼无关的运动表示。4) 运动重定向模块:将通用运动表示映射到目标骨骼,生成目标角色的运动。5) 循环一致性模块:通过循环重定向,确保运动语义的一致性。
关键创新:PALUM的关键创新在于:1) 基于部件的注意力学习:通过将关节划分为语义部件,并利用注意力机制学习部件之间的关系,提取与骨骼无关的通用运动表示。2) 循环一致性机制:通过循环重定向,确保运动语义的一致性,提高重定向的质量和鲁棒性。
关键设计:PALUM的关键设计包括:1) 部件划分策略:采用预定义的语义部件划分方案,例如头部、躯干、四肢等。2) 注意力机制:使用Transformer或类似的注意力机制,学习部件之间的时空关系。3) 损失函数:采用多种损失函数,包括运动学损失、语义损失和循环一致性损失,以确保重定向的质量和语义保真度。4) 网络结构:采用编码器-解码器结构,编码器用于提取通用运动表示,解码器用于将通用运动表示映射到目标骨骼。
🖼️ 关键图片


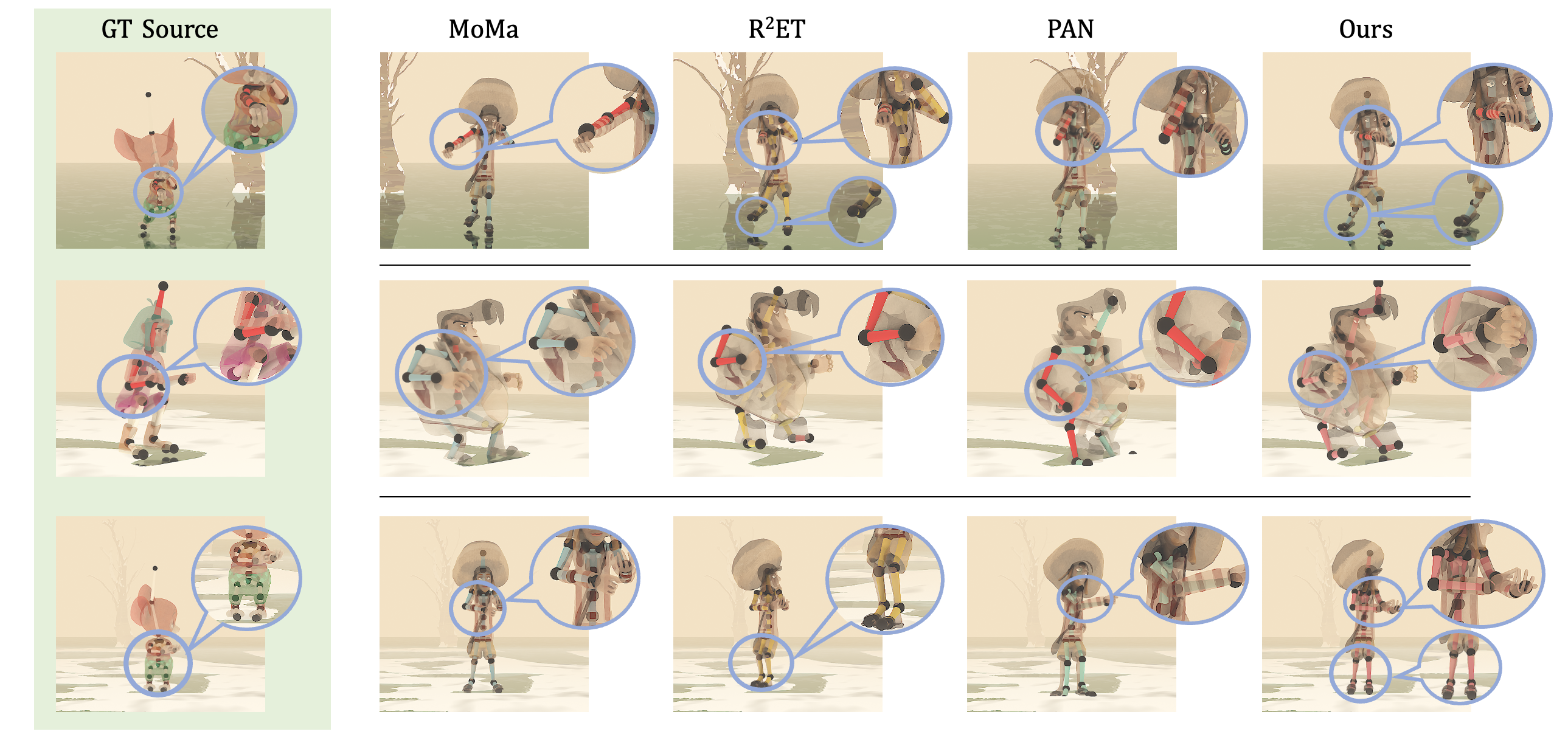
📊 实验亮点
实验结果表明,PALUM在运动重定向任务上取得了显著的性能提升。与现有方法相比,PALUM能够更好地处理骨骼结构差异较大的角色,并保持运动的真实感和语义保真度。在多个数据集上的实验结果表明,PALUM在运动质量和语义相似度方面均优于其他基线方法,尤其是在处理具有复杂骨骼结构的角色时,优势更加明显。
🎯 应用场景
PALUM可广泛应用于游戏开发、虚拟现实、动画制作等领域。它可以帮助开发者快速地将运动数据迁移到具有不同骨骼结构的角色上,从而节省大量的人工成本。此外,PALUM还可以用于创建更加逼真和自然的虚拟角色动画,提升用户体验。未来,该技术有望应用于人机交互、机器人控制等领域。
📄 摘要(原文)
Retargeting motion between characters with different skeleton structures is a fundamental challenge in computer animation. When source and target characters have vastly different bone arrangements, maintaining the original motion's semantics and quality becomes increasingly difficult. We present PALUM, a novel approach that learns common motion representations across diverse skeleton topologies by partitioning joints into semantic body parts and applying attention mechanisms to capture spatio-temporal relationships. Our method transfers motion to target skeletons by leveraging these skeleton-agnostic representations alongside target-specific structural information. To ensure robust learning and preserve motion fidelity, we introduce a cycle consistency mechanism that maintains semantic coherence throughout the retargeting process. Extensive experiments demonstrate superior performance in handling diverse skeletal structures while maintaining motion realism and semantic fidelity, even when generalizing to previously unseen skeleton-motion combinations. We will make our implementation publicly available to support future research.