ShowUI-Aloha: Human-Taught GUI Agent
作者: Yichun Zhang, Xiangwu Guo, Yauhong Goh, Jessica Hu, Zhiheng Chen, Xin Wang, Difei Gao, Mike Zheng Shou
分类: cs.CV
发布日期: 2026-01-12
备注: 13 Pages, 16 Figures
💡 一句话要点
ShowUI-Aloha:一种基于人类示教的GUI智能体框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GUI自动化 人机交互 模仿学习 屏幕录像 任务规划
📋 核心要点
- 现有GUI自动化方法缺乏大规模、高质量的训练数据,难以处理真实场景中复杂、非结构化的用户交互。
- ShowUI-Aloha框架通过记录、解析、规划和执行四个模块,将人类屏幕录像转化为可执行的GUI任务。
- 该方法旨在通过观察人类操作来学习,为构建通用GUI智能体提供了一种可行的、可扩展的解决方案。
📝 摘要(中文)
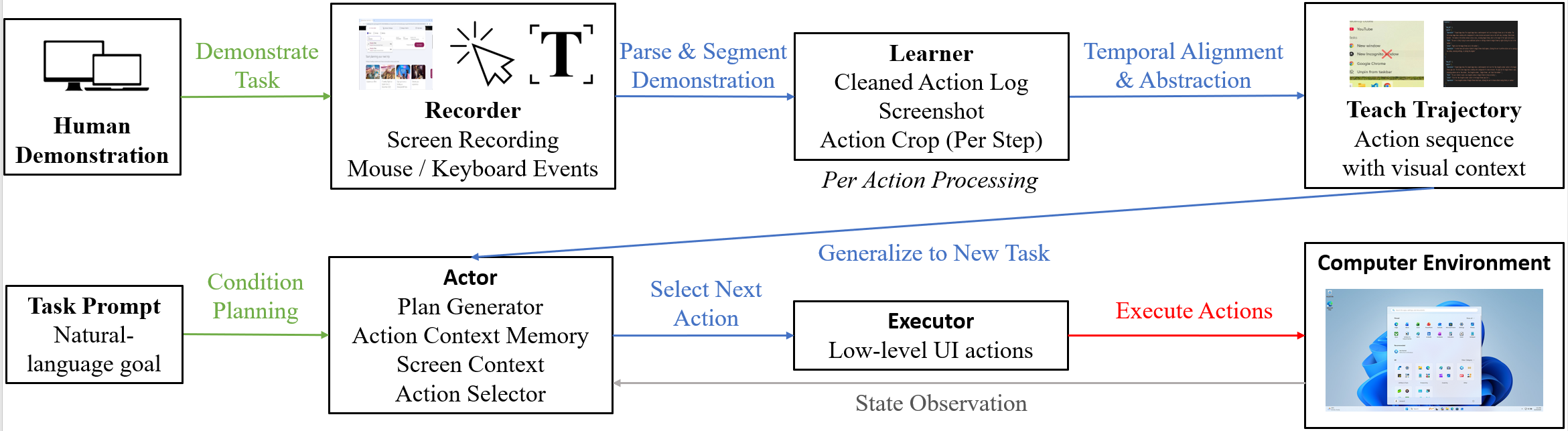
图形用户界面(GUI)是人机交互的核心,但自动化复杂的GUI任务对于自主智能体来说仍然是一个主要的挑战,这主要是由于缺乏可扩展的高质量训练数据。虽然人类演示记录提供了一个丰富的数据来源,但它们通常很长、非结构化且缺乏注释,这使得智能体难以从中学习。为了解决这个问题,我们引入了ShowUI-Aloha,这是一个全面的pipeline,可以将桌面环境中非结构化的、真实的屏幕录像转换为结构化的、可操作的任务。我们的框架包括四个关键组件:一个记录器,用于捕获屏幕视频以及精确的用户交互,如鼠标点击、键盘输入和滚动;一个学习器,用于语义地解释这些原始交互和周围的视觉上下文,将其翻译成描述性的自然语言标题;一个规划器,用于读取解析后的演示,维护任务状态,并基于上下文推理动态地制定下一个高级行动计划;一个执行器,用于在操作系统级别忠实地执行这些行动计划,执行精确的点击、拖动、文本输入和窗口操作,并具有安全检查和实时反馈。总之,这些组件提供了一个可扩展的解决方案,用于收集和解析真实世界的人类数据,展示了一条构建通用GUI智能体的可行路径,这些智能体可以通过简单地观察人类来有效地学习。
🔬 方法详解
问题定义:论文旨在解决GUI自动化任务中缺乏高质量训练数据的问题。现有的方法难以处理真实世界中人类操作的复杂性和非结构化,导致智能体难以学习和泛化。这些痛点包括数据获取成本高、数据标注困难以及模型泛化能力不足。
核心思路:论文的核心思路是将人类在GUI上的操作记录转化为结构化的、可执行的任务。通过模仿学习,智能体可以从人类的演示中学习如何完成各种GUI任务。这种方法避免了手动标注大量数据的需要,并且可以利用现有的屏幕录像数据。
技术框架:ShowUI-Aloha框架包含四个主要模块:记录器(Recorder)、学习器(Learner)、规划器(Planner)和执行器(Executor)。记录器负责捕获屏幕视频和用户交互数据;学习器负责解析这些数据,将其转化为自然语言描述;规划器负责根据当前任务状态制定行动计划;执行器负责执行这些计划,完成GUI操作。整个流程形成一个闭环,智能体可以通过不断学习和执行来提高其GUI自动化能力。
关键创新:该论文的关键创新在于构建了一个完整的pipeline,能够将非结构化的屏幕录像转化为结构化的、可执行的任务。这种方法避免了手动标注大量数据的需要,并且可以利用现有的屏幕录像数据。此外,该框架的模块化设计使得各个模块可以独立改进和优化。
关键设计:记录器需要精确地捕获用户交互,包括鼠标点击、键盘输入和滚动等。学习器需要能够理解用户操作的语义,并将其转化为自然语言描述。规划器需要能够根据当前任务状态制定合理的行动计划。执行器需要能够安全可靠地执行这些计划,并提供实时反馈。
🖼️ 关键图片


📊 实验亮点
论文提出了一个完整的GUI智能体框架,能够从人类屏幕录像中学习并执行GUI任务。该框架通过记录、解析、规划和执行四个模块,实现了将非结构化数据转化为可执行任务的目标。虽然论文中没有明确给出具体的性能数据,但该框架为构建通用GUI智能体提供了一条可行的路径。
🎯 应用场景
该研究成果可应用于自动化办公、软件测试、用户行为分析等领域。例如,可以利用该技术自动完成重复性的GUI操作,提高工作效率;可以用于自动化测试软件,发现潜在的bug;还可以用于分析用户行为,优化软件设计。未来,该技术有望实现更智能、更自主的人机交互。
📄 摘要(原文)
Graphical User Interfaces (GUIs) are central to human-computer interaction, yet automating complex GUI tasks remains a major challenge for autonomous agents, largely due to a lack of scalable, high-quality training data. While recordings of human demonstrations offer a rich data source, they are typically long, unstructured, and lack annotations, making them difficult for agents to learn from.To address this, we introduce ShowUI-Aloha, a comprehensive pipeline that transforms unstructured, in-the-wild human screen recordings from desktop environments into structured, actionable tasks. Our framework includes four key components: A recorder that captures screen video along with precise user interactions like mouse clicks, keystrokes, and scrolls. A learner that semantically interprets these raw interactions and the surrounding visual context, translating them into descriptive natural language captions. A planner that reads the parsed demonstrations, maintains task states, and dynamically formulates the next high-level action plan based on contextual reasoning. An executor that faithfully carries out these action plans at the OS level, performing precise clicks, drags, text inputs, and window operations with safety checks and real-time feedback. Together, these components provide a scalable solution for collecting and parsing real-world human data, demonstrating a viable path toward building general-purpose GUI agents that can learn effectively from simply observing humans.