UR-Bench: A Benchmark for Multi-Hop Reasoning over Ultra-High-Resolution Images
作者: Siqi Li, Xinyu Cai, Jianbiao Mei, Nianchen Deng, Pinlong Cai, Licheng Wen, Yufan Shen, Xuemeng Yang, Botian Shi, Yong Liu
分类: cs.CV, cs.AI
发布日期: 2025-12-31
备注: 10 pages, 5 figures
💡 一句话要点
提出UR-Bench,用于评估多模态大模型在超高分辨率图像上的多跳推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 超高分辨率图像 多模态推理 视觉问答 基准数据集 代理框架
📋 核心要点
- 现有VQA基准在视觉复杂度上存在局限性,无法充分评估MLLM在超高分辨率图像上的推理能力。
- UR-Bench通过构建包含人文和自然场景的超高分辨率图像数据集,并设计多级推理问答,弥补了现有基准的不足。
- 论文提出了基于代理的框架,并引入语义抽象和检索工具,以提升MLLM在超高分辨率图像上的推理效率。
📝 摘要(中文)
本文提出了超高分辨率推理基准(UR-Bench),旨在评估多模态大语言模型(MLLM)在极端视觉信息下的推理能力。现有视觉问答(VQA)基准主要依赖于中等分辨率数据,视觉复杂度有限。UR-Bench包含人文场景和自然场景两大类,涵盖四个具有不同空间结构和数据来源的超高分辨率图像子集。每个子集包含数百万到数十亿像素的图像,并提供三个级别的问答,用于评估模型在超高分辨率场景下的推理能力。此外,本文还提出了一个基于代理的框架,其中语言模型通过调用外部视觉工具进行推理。同时,引入了语义抽象和检索工具,以更有效地处理超高分辨率图像。通过端到端MLLM和基于代理的框架,验证了该框架的有效性。
🔬 方法详解
问题定义:现有视觉问答(VQA)基准主要使用中等分辨率图像,无法充分测试多模态大语言模型(MLLM)在处理和推理超高分辨率图像时的能力。现有方法难以有效处理超高分辨率图像带来的巨大计算量和信息复杂性,限制了模型在实际应用中的潜力。
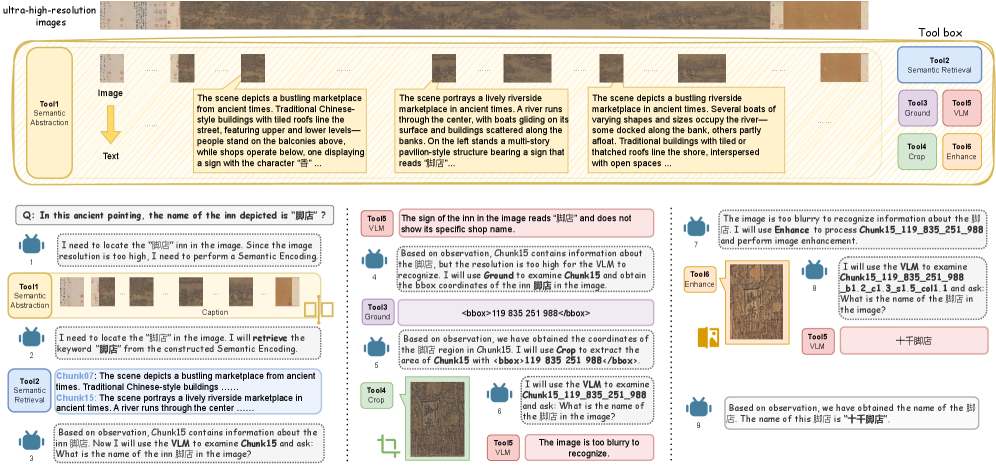
核心思路:论文的核心思路是构建一个专门针对超高分辨率图像的推理基准,并设计相应的工具和框架,以提升MLLM在处理此类图像时的效率和准确性。通过引入外部视觉工具和语义抽象,降低了模型直接处理原始高分辨率图像的难度。
技术框架:UR-Bench包含超高分辨率图像数据集和基于代理的推理框架。数据集分为人文场景和自然场景两大类,包含多个子集,每个子集包含不同分辨率的图像和多级推理问答。基于代理的框架允许语言模型通过调用外部视觉工具(如语义抽象和检索工具)来辅助推理。整体流程包括:问题输入、代理决策(选择合适的工具)、工具调用、结果整合和答案生成。
关键创新:该论文的关键创新在于:1) 构建了首个针对超高分辨率图像推理的基准数据集UR-Bench;2) 提出了基于代理的推理框架,允许模型利用外部视觉工具进行推理,从而降低了对模型自身计算能力的要求;3) 引入了语义抽象和检索工具,以更有效地处理超高分辨率图像,减少计算负担。
关键设计:语义抽象工具用于提取图像的语义信息,例如目标检测、场景分割等。检索工具用于在图像中查找与问题相关的区域或对象。代理的选择策略至关重要,需要根据问题的类型和图像的特点选择合适的工具组合。具体的参数设置和网络结构取决于所使用的外部视觉工具和MLLM。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了UR-Bench的有效性。实验结果表明,基于代理的框架在超高分辨率图像推理任务上优于端到端MLLM。语义抽象和检索工具的引入显著提升了推理效率,降低了计算成本。具体的性能数据和提升幅度在论文中有详细展示。
🎯 应用场景
UR-Bench的研究成果可应用于遥感图像分析、医学影像诊断、文物保护等领域。通过提升MLLM在超高分辨率图像上的推理能力,可以更准确地识别和分析图像中的细节信息,为相关领域的决策提供更可靠的依据。未来,该研究有望推动多模态大模型在更多实际场景中的应用。
📄 摘要(原文)
Recent multimodal large language models (MLLMs) show strong capabilities in visual-language reasoning, yet their performance on ultra-high-resolution imagery remains largely unexplored. Existing visual question answering (VQA) benchmarks typically rely on medium-resolution data, offering limited visual complexity. To bridge this gap, we introduce Ultra-high-resolution Reasoning Benchmark (UR-Bench), a benchmark designed to evaluate the reasoning capabilities of MLLMs under extreme visual information. UR-Bench comprises two major categories, Humanistic Scenes and Natural Scenes, covering four subsets of ultra-high-resolution images with distinct spatial structures and data sources. Each subset contains images ranging from hundreds of megapixels to gigapixels, accompanied by questions organized into three levels, enabling evaluation of models' reasoning capabilities in ultra-high-resolution scenarios. We further propose an agent-based framework in which a language model performs reasoning by invoking external visual tools. In addition, we introduce Semantic Abstraction and Retrieval tools that enable more efficient processing of ultra-high-resolution images. We evaluate state-of-the-art models using both an end-to-end MLLMs and our agent-based framework, demonstrating the effectiveness of our framework.