TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
作者: Yabo Chen, Yuanzhi Liang, Jiepeng Wang, Tingxi Chen, Junfei Cheng, Zixiao Gu, Yuyang Huang, Zicheng Jiang, Wei Li, Tian Li, Weichen Li, Zuoxin Li, Guangce Liu, Jialun Liu, Junqi Liu, Haoyuan Wang, Qizhen Weng, Xuan'er Wu, Xunzhi Xiang, Xiaoyan Yang, Xin Zhang, Shiwen Zhang, Junyu Zhou, Chengcheng Zhou, Haibin Huang, Chi Zhang, Xuelong Li
分类: cs.CV
发布日期: 2025-12-31
💡 一句话要点
TeleWorld:基于4D世界模型的动态多模态实时合成框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 世界模型 视频生成 动态场景重建 4D建模 长期一致性 实时生成 具身智能 多模态融合
📋 核心要点
- 现有视频生成模型在实时交互、长期一致性和动态场景记忆方面存在不足,难以成为实用的世界模型。
- TeleWorld提出生成-重建-引导范式,将生成的视频流重建为4D时空表示,引导后续生成以保持一致性。
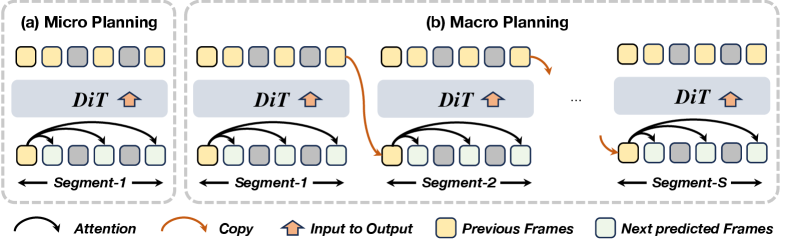
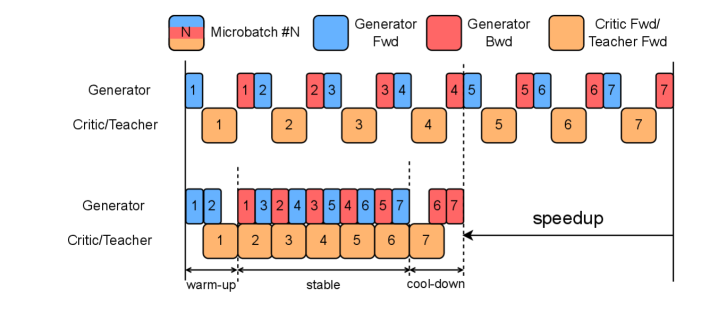
- TeleWorld结合分层规划MMPL和高效蒸馏DMD,在保证长期一致性的前提下,实现了实时视频合成。
📝 摘要(中文)
世界模型旨在赋予AI系统以连贯且时序一致的方式表示、生成动态环境并与之交互的能力。虽然最近的视频生成模型展示了令人印象深刻的视觉质量,但它们在实时交互、长时程一致性和动态场景的持久记忆方面仍然受到限制,阻碍了它们发展成为实用的世界模型。本报告介绍了TeleWorld,一个实时的多模态4D世界建模框架,它统一了视频生成、动态场景重建和长期世界记忆在一个闭环系统中。TeleWorld引入了一种新的生成-重建-引导范式,其中生成的视频流被连续地重建为动态的4D时空表示,进而引导后续生成以维持空间、时间和物理一致性。为了支持低延迟的长时程生成,我们采用了一种基于自回归扩散的视频模型,该模型通过Macro-from-Micro Planning (MMPL)进行了增强——一种将误差累积从帧级别降低到段级别的分层规划方法——以及高效的Distribution Matching Distillation (DMD),从而在实际的计算预算下实现实时合成。我们的方法实现了动态对象建模和静态场景表示在统一的4D框架内的无缝集成,从而推动世界模型朝着实用、交互式和计算可访问的系统发展。广泛的实验表明,TeleWorld在静态和动态世界理解、长期一致性和实时生成效率方面都取得了强大的性能,使其成为迈向交互式、具有记忆功能的多模态生成和具身智能世界模型的切实一步。
🔬 方法详解
问题定义:现有视频生成模型难以兼顾实时性、长期一致性和动态场景记忆,无法满足交互式世界模型的需求。它们通常缺乏对生成内容的持续理解和修正机制,导致长期生成过程中出现漂移和不一致。
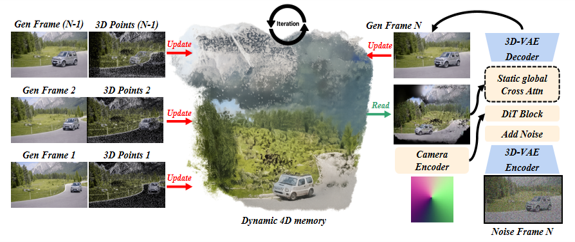
核心思路:TeleWorld的核心思路是引入一个闭环的生成-重建-引导流程。通过不断地将生成的视频重建为4D世界模型,并利用该模型指导后续的生成过程,从而实现对生成内容的持续监控和修正,保证长期一致性。这种方法类似于人类的记忆和反思过程,能够更好地理解和控制生成的内容。
技术框架:TeleWorld包含三个主要模块:视频生成模块、动态场景重建模块和世界记忆模块。视频生成模块负责生成初始视频帧;动态场景重建模块将生成的视频帧重建为4D时空表示;世界记忆模块存储和更新4D世界模型,并将其用于指导后续的视频生成。整个流程形成一个闭环,不断迭代优化生成结果。
关键创新:TeleWorld的关键创新在于其生成-重建-引导范式,以及将动态对象建模和静态场景表示集成到统一的4D框架中。此外,MMPL分层规划方法和DMD蒸馏方法也显著提升了生成效率和长期一致性。
关键设计:TeleWorld采用自回归扩散模型作为视频生成器,并使用MMPL进行分层规划,将生成过程分解为宏观的片段级别和微观的帧级别。DMD蒸馏方法用于加速生成过程,降低计算成本。4D世界模型采用神经辐射场(NeRF)等技术进行表示,能够有效地捕捉场景的几何和外观信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TeleWorld在静态和动态世界理解、长期一致性和实时生成效率方面都取得了显著的提升。与现有方法相比,TeleWorld能够生成更逼真、更一致的视频序列,并且能够以更低的延迟进行实时交互。具体性能数据未知,但论文强调了其在多个指标上的优越性。
🎯 应用场景
TeleWorld具有广泛的应用前景,例如虚拟现实/增强现实、游戏开发、机器人导航和控制、自动驾驶等领域。它可以用于创建逼真的虚拟环境,模拟复杂的物理交互,并为智能体提供长期记忆和规划能力,从而实现更智能、更自然的交互体验。
📄 摘要(原文)
World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.