VLN-MME: Diagnosing MLLMs as Language-guided Visual Navigation agents
作者: Xunyi Zhao, Gengze Zhou, Qi Wu
分类: cs.CV, cs.RO
发布日期: 2025-12-31 (更新: 2026-01-06)
💡 一句话要点
VLN-MME:诊断多模态大语言模型在语言引导视觉导航任务中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 多模态大语言模型 具身智能 评估框架 零样本学习
📋 核心要点
- 现有具身智能体研究缺乏统一的评估框架,难以有效诊断多模态大语言模型在视觉导航中的能力。
- 论文提出VLN-MME框架,将传统导航数据集转化为标准化基准,用于零样本评估MLLMs在VLN任务中的表现。
- 实验发现,增强MLLM的CoT推理和自我反思反而导致性能下降,揭示了其在具身导航中上下文感知能力不足。
📝 摘要(中文)
多模态大语言模型(MLLMs)在各种视觉-语言任务中表现出卓越的能力。然而,它们作为具身智能体的性能,需要多轮对话空间推理和序列动作预测,仍有待进一步探索。本研究通过引入一个统一且可扩展的评估框架VLN-MME,将传统导航数据集转化为标准化基准,以检验MLLMs作为零样本智能体在视觉-语言导航(VLN)中的潜力。我们通过高度模块化和易于访问的设计简化了评估。这种灵活性简化了实验,实现了跨不同MLLM架构、智能体设计和导航任务的结构化比较和组件级消融研究。重要的是,在我们的框架支持下,我们观察到使用思维链(CoT)推理和自我反思增强我们的基线智能体反而导致性能下降。这表明MLLMs在具身导航任务中表现出较差的上下文感知能力;尽管它们可以遵循指令并构建其输出,但它们的3D空间推理保真度较低。VLN-MME为在具身导航环境中系统评估通用MLLMs奠定了基础,并揭示了它们在序列决策能力方面的局限性。我们相信这些发现为MLLM作为具身智能体的后训练提供了关键指导。
🔬 方法详解
问题定义:论文旨在解决如何有效评估多模态大语言模型(MLLMs)在视觉-语言导航(VLN)任务中的能力。现有方法缺乏统一的评估标准和框架,难以对不同MLLM架构、智能体设计和导航任务进行系统性比较和分析。此外,现有方法难以诊断MLLMs在多轮对话、空间推理和序列动作预测等方面的具体不足。
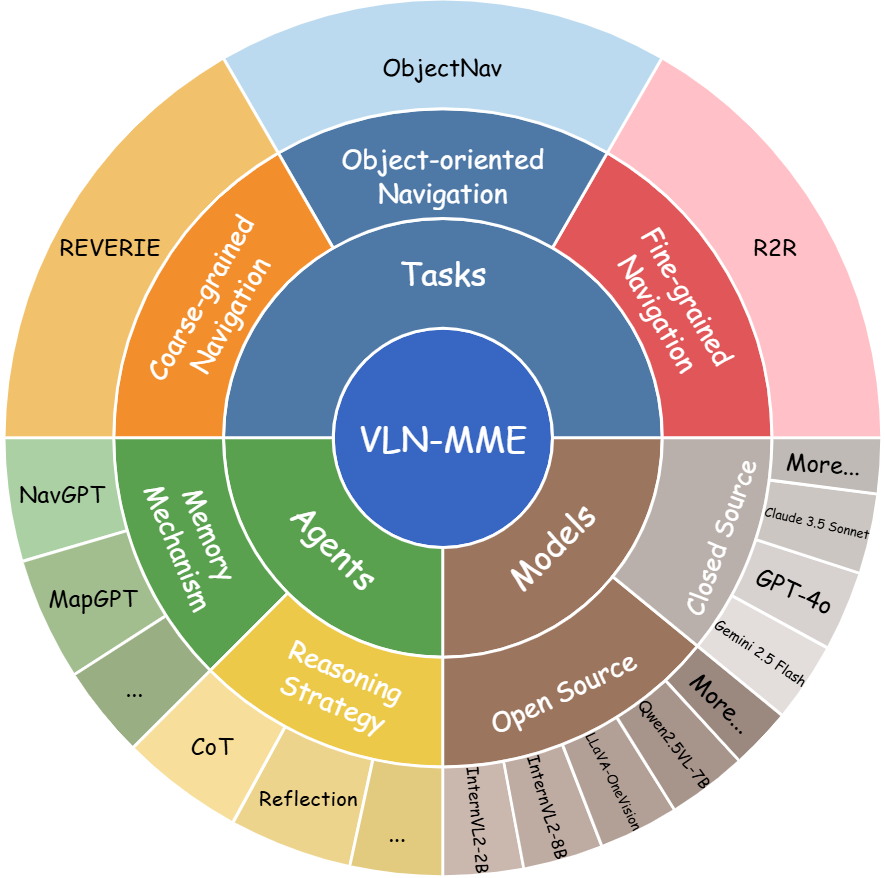
核心思路:论文的核心思路是构建一个统一且可扩展的评估框架VLN-MME,将传统的导航数据集转化为一个标准化的基准。通过这个基准,可以系统地评估MLLMs作为零样本智能体在VLN任务中的表现,并深入分析其在不同方面的能力和局限性。VLN-MME的设计目标是模块化、易于访问和灵活,以便于进行各种实验和消融研究。
技术框架:VLN-MME框架主要包含以下几个模块:1) 数据集标准化模块,将不同的VLN数据集转换为统一的格式;2) 智能体接口模块,定义了MLLM智能体与环境交互的标准接口;3) 评估指标模块,用于计算智能体的导航性能;4) 可视化模块,用于展示智能体的导航轨迹和决策过程。整个流程是,首先将导航数据集输入到智能体接口模块,MLLM智能体根据当前的环境信息和导航指令做出动作预测,然后环境根据智能体的动作更新状态,并将新的环境信息反馈给智能体。这个过程不断循环,直到智能体到达目标位置或达到最大步数。最后,评估指标模块根据智能体的导航轨迹计算其性能。
关键创新:VLN-MME的关键创新在于其统一性和可扩展性。它提供了一个标准化的基准,使得研究人员可以方便地比较不同MLLM架构、智能体设计和导航任务的性能。此外,VLN-MME的模块化设计使得研究人员可以轻松地添加新的数据集、智能体接口和评估指标。另一个创新点是,论文发现增强MLLM的CoT推理和自我反思反而导致性能下降,这揭示了MLLMs在具身导航任务中上下文感知能力不足的问题。
关键设计:VLN-MME的关键设计包括:1) 使用统一的数据格式来表示不同的VLN数据集;2) 定义了标准的智能体接口,使得不同的MLLM智能体可以方便地与环境交互;3) 采用了多种评估指标,包括导航成功率、路径长度和时间步数等;4) 提供了可视化工具,用于展示智能体的导航轨迹和决策过程。此外,论文还设计了一系列的消融实验,用于分析不同组件对智能体性能的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在VLN-MME基准上,直接应用MLLMs作为导航智能体效果有限。令人惊讶的是,引入CoT推理和自我反思机制后,性能反而下降,这表明MLLMs在具身导航中存在空间推理和上下文理解的不足。这些发现为后续改进MLLMs在具身智能体应用中的性能提供了重要指导。
🎯 应用场景
该研究成果可应用于开发更智能的机器人导航系统,例如在家庭、办公室或仓库等复杂环境中自主导航的机器人。此外,该研究还可以促进多模态大语言模型在具身智能领域的应用,例如开发能够理解人类指令并在真实世界中执行任务的智能助手。未来的研究可以探索如何提高MLLMs在具身导航任务中的上下文感知能力和空间推理能力。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across a wide range of vision-language tasks. However, their performance as embodied agents, which requires multi-round dialogue spatial reasoning and sequential action prediction, needs further exploration. Our work investigates this potential in the context of Vision-and-Language Navigation (VLN) by introducing a unified and extensible evaluation framework to probe MLLMs as zero-shot agents by bridging traditional navigation datasets into a standardized benchmark, named VLN-MME. We simplify the evaluation with a highly modular and accessible design. This flexibility streamlines experiments, enabling structured comparisons and component-level ablations across diverse MLLM architectures, agent designs, and navigation tasks. Crucially, enabled by our framework, we observe that enhancing our baseline agent with Chain-of-Thought (CoT) reasoning and self-reflection leads to an unexpected performance decrease. This suggests MLLMs exhibit poor context awareness in embodied navigation tasks; although they can follow instructions and structure their output, their 3D spatial reasoning fidelity is low. VLN-MME lays the groundwork for systematic evaluation of general-purpose MLLMs in embodied navigation settings and reveals limitations in their sequential decision-making capabilities. We believe these findings offer crucial guidance for MLLM post-training as embodied agents.