PhyGDPO: Physics-Aware Groupwise Direct Preference Optimization for Physically Consistent Text-to-Video Generation
作者: Yuanhao Cai, Kunpeng Li, Menglin Jia, Jialiang Wang, Junzhe Sun, Feng Liang, Weifeng Chen, Felix Juefei-Xu, Chu Wang, Ali Thabet, Xiaoliang Dai, Xuan Ju, Alan Yuille, Ji Hou
分类: cs.CV
发布日期: 2025-12-31 (更新: 2026-01-30)
🔗 代码/项目: GITHUB | PROJECT_PAGE
💡 一句话要点
提出PhyGDPO框架,通过物理感知的群体偏好优化实现物理一致的文本生成视频。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本生成视频 物理一致性 群体偏好优化 视觉语言模型 物理引导奖励
📋 核心要点
- 现有文本生成视频方法难以保证生成的视频符合物理规律,泛化能力不足。
- 提出PhyGDPO框架,利用物理引导奖励和群体偏好优化,提升视频的物理一致性。
- 实验结果表明,该方法在PhyGenBench和VideoPhy2数据集上显著优于现有方法。
📝 摘要(中文)
本文旨在解决文本生成视频(T2V)领域中,生成符合物理规律的视频这一难题。现有方法主要依赖图形或提示扩展,难以泛化到复杂环境或学习隐式的物理推理。同时,缺乏包含丰富物理交互和现象的训练数据也是一个问题。为此,本文首先提出了一个物理增强的视频数据构建流程PhyAugPipe,利用具有思维链推理的视觉语言模型(VLM)来收集大规模训练数据集PhyVidGen-135K。然后,本文构建了一个基于物理的群体偏好直接优化框架PhyGDPO,该框架建立在群体Plackett-Luce概率模型之上,以捕获超越成对比较的整体偏好。在PhyGDPO中,设计了一个物理引导奖励(PGR)方案,嵌入基于VLM的物理奖励,以引导优化朝着物理一致性方向发展。此外,还提出了一种LoRA-Switch Reference(LoRA-SR)方案,消除了内存密集型参考复制,从而实现高效训练。实验表明,本文方法在PhyGenBench和VideoPhy2上显著优于最先进的开源方法。
🔬 方法详解
问题定义:现有文本生成视频(T2V)模型在生成视觉质量良好的视频方面取得了显著进展,但仍然难以生成符合物理规律的视频。现有方法,如基于图形的方法或提示扩展方法,通常难以泛化到复杂的物理环境中,并且缺乏学习隐式物理推理的能力。此外,缺乏包含丰富物理交互和现象的大规模训练数据也是一个关键瓶颈。
核心思路:本文的核心思路是通过引入物理感知的奖励机制和群体偏好优化,来引导T2V模型生成更符合物理规律的视频。具体来说,首先构建一个大规模的物理增强视频数据集,然后利用这个数据集训练一个能够识别和奖励物理一致性的模型,最后使用群体偏好优化方法来提升模型的整体性能。
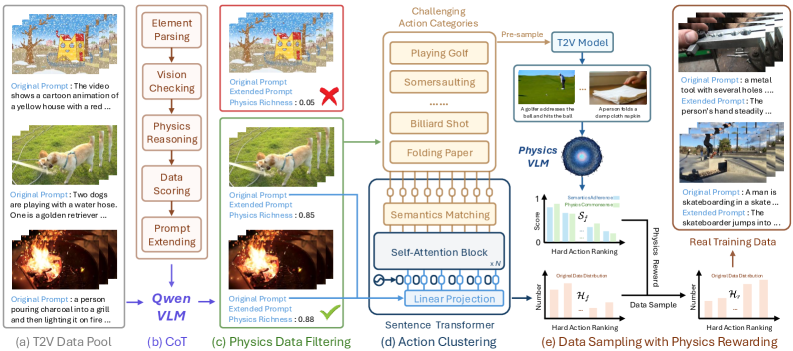
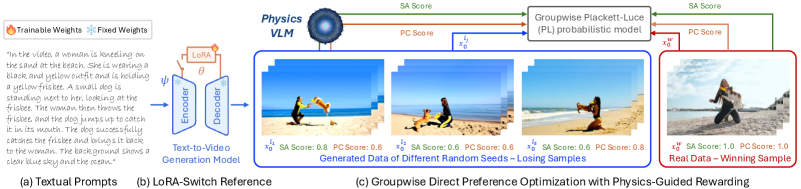
技术框架:PhyGDPO框架主要包含两个阶段:数据构建阶段和模型训练阶段。在数据构建阶段,使用PhyAugPipe流程,利用具有思维链推理能力的视觉语言模型(VLM)生成大规模的物理增强视频数据集PhyVidGen-135K。在模型训练阶段,使用PhyGDPO框架,该框架包含物理引导奖励(PGR)模块和LoRA-Switch Reference(LoRA-SR)模块。PGR模块利用VLM计算物理奖励,引导优化过程朝着物理一致性方向发展。LoRA-SR模块用于减少训练过程中的内存消耗。
关键创新:本文的关键创新在于以下几个方面:1) 提出了PhyAugPipe流程,用于构建大规模的物理增强视频数据集。2) 提出了PhyGDPO框架,该框架利用物理引导奖励和群体偏好优化来提升视频的物理一致性。3) 提出了LoRA-SR模块,用于减少训练过程中的内存消耗。
关键设计:在物理引导奖励(PGR)模块中,使用VLM来评估生成视频的物理一致性,并将其作为奖励信号。具体来说,VLM被用于判断视频中发生的物理事件是否符合常识。群体偏好优化基于Plackett-Luce模型,该模型能够捕获超越成对比较的整体偏好。LoRA-SR模块通过共享LoRA参数来减少内存消耗,避免了对大量参考视频进行重复编码。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PhyGDPO在PhyGenBench和VideoPhy2数据集上显著优于现有的开源方法。具体来说,在物理一致性指标上取得了显著提升,表明该方法能够有效提高生成视频的物理合理性。同时,LoRA-SR模块有效降低了训练过程中的内存消耗,使得大规模训练成为可能。
🎯 应用场景
该研究成果可应用于游戏开发、电影制作、虚拟现实等领域,生成更逼真、更符合物理规律的虚拟环境和内容。例如,可以用于创建更真实的物理模拟游戏,或生成更具沉浸感的虚拟现实体验。此外,该技术还可以用于教育领域,帮助学生更好地理解物理概念。
📄 摘要(原文)
Recent advances in text-to-video (T2V) generation have achieved good visual quality, yet synthesizing videos that faithfully follow physical laws remains an open challenge. Existing methods mainly based on graphics or prompt extension struggle to generalize beyond simple simulated environments or learn implicit physical reasoning. The scarcity of training data with rich physics interactions and phenomena is also a problem. In this paper, we first introduce a Physics-Augmented video data construction Pipeline, PhyAugPipe, that leverages a vision-language model (VLM) with chain-of-thought reasoning to collect a large-scale training dataset, PhyVidGen-135K. Then we formulate a principled Physics-aware Groupwise Direct Preference Optimization, PhyGDPO, framework that builds upon the groupwise Plackett-Luce probabilistic model to capture holistic preferences beyond pairwise comparisons. In PhyGDPO, we design a Physics-Guided Rewarding (PGR) scheme that embeds VLM-based physics rewards to steer optimization toward physical consistency. We also propose a LoRA-Switch Reference (LoRA-SR) scheme that eliminates memory-heavy reference duplication for efficient training. Experiments show that our method significantly outperforms state-of-the-art open-source methods on PhyGenBench and VideoPhy2. Please check our project page at https://caiyuanhao1998.github.io/project/PhyGDPO for more video results. Our code, models, and data will be released at https://github.com/caiyuanhao1998/Open-PhyGDPO